 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-Guided Reflective Sampling for Aligning Language Models
Paper and Code
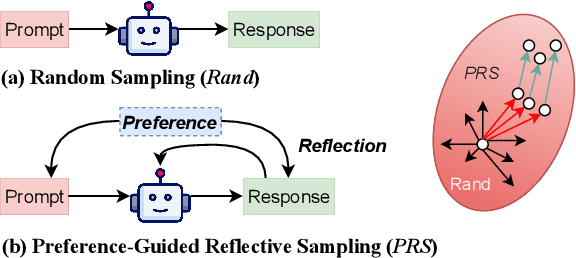


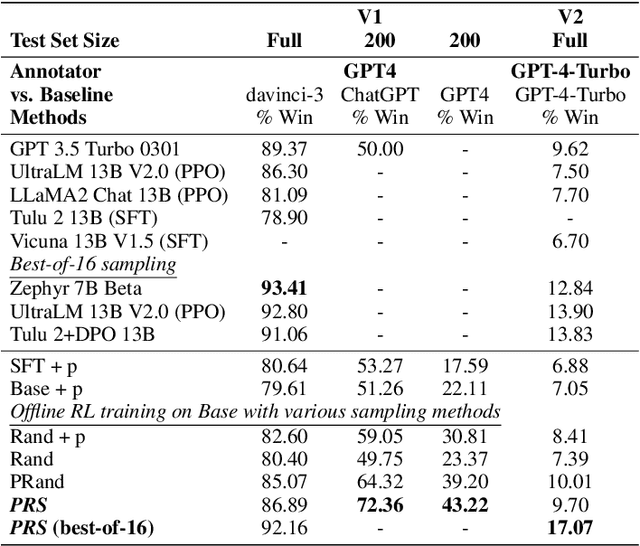
Large language models (LLMs) are aligned with human preferences by reinforcement learning from human feedback (RLHF). Effective data sampling is crucial for RLHF, as it determines the efficiency of model training, ensuring that models learn from the informative samples. To achieve better data generation, we propose a new sampling method called Preference-Guided Reflective Sampling (PRS). PRS frames the response generation as an optimization process to the explicitly specified user preference described in natural language. It employs a tree-based generation framework to enable an efficient sampling process, which guides the direction of generation through preference and better explores the sampling space with adaptive self-refinement. Notably, PRS can align LLMs to diverse preferences. We study preference-controlled text generation for instruction following and keyword-focused document summarization. Our findings indicate that PRS, across different LLM policies, generates training data with much higher rewards than strong baselines. PRS also excels in post-RL training.