 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame of Thought: Robust Information Seeking with Large Language Models Using Game Theory
Feb 02, 2026Large Language Models (LLMs) are increasingly deployed in real-world scenarios where they may lack sufficient information to complete a given task. In such settings, the ability to actively seek out missing information becomes a critical capability. Existing approaches to enhancing this ability often rely on simplifying assumptions that degrade \textit{worst-case} performance. This is an issue with serious implications in high-stakes applications. In this work, we use the game of Twenty Questions to evaluate the information-seeking ability of LLMs. We introduce and formalize its adversarial counterpart, the Strategic Language Search (SLS) problem along with its variants as a two-player zero-sum extensive form game. We propose Game of Thought (GoT), a framework that applies game-theoretic techniques to approximate a Nash equilibrium (NE) strategy for the restricted variant of the game. Empirical results demonstrate that our approach consistently improves worst-case performance compared to (1) direct prompting-based methods and (2) heuristic-guided search methods across all tested settings.
OpenSeal: Good, Fast, and Cheap Construction of an Open-Source Southeast Asian LLM via Parallel Data
Feb 02, 2026Large language models (LLMs) have proven to be effective tools for a wide range of natural language processing (NLP) applications. Although many LLMs are multilingual, most remain English-centric and perform poorly on low-resource languages. Recently, several Southeast Asia-focused LLMs have been developed, but none are truly open source, as they do not publicly disclose their training data. Truly open-source models are important for transparency and for enabling a deeper and more precise understanding of LLM internals and development, including biases, generalization, and multilinguality. Motivated by recent advances demonstrating the effectiveness of parallel data in improving multilingual performance, we conduct controlled and comprehensive experiments to study the effectiveness of parallel data in continual pretraining of LLMs. Our findings show that using only parallel data is the most effective way to extend an LLM to new languages. Using just 34.7B tokens of parallel data and 180 hours on 8x NVIDIA H200 GPUs, we built OpenSeal, the first truly open Southeast Asian LLM that rivals the performance of existing models of similar size.
Parametric Knowledge is Not All You Need: Toward Honest Large Language Models via Retrieval of Pretraining Data
Jan 29, 2026Large language models (LLMs) are highly capable of answering questions, but they are often unaware of their own knowledge boundary, i.e., knowing what they know and what they don't know. As a result, they can generate factually incorrect responses on topics they do not have enough knowledge of, commonly known as hallucination. Rather than hallucinating, a language model should be more honest and respond with "I don't know" when it does not have enough knowledge about a topic. Many methods have been proposed to improve LLM honesty, but their evaluations lack robustness, as they do not take into account the knowledge that the LLM has ingested during its pretraining. In this paper, we propose a more robust evaluation benchmark dataset for LLM honesty by utilizing Pythia, a truly open LLM with publicly available pretraining data. In addition, we also propose a novel method for harnessing the pretraining data to build a more honest LLM.
FocusUI: Efficient UI Grounding via Position-Preserving Visual Token Selection
Jan 07, 2026Vision-Language Models (VLMs) have shown remarkable performance in User Interface (UI) grounding tasks, driven by their ability to process increasingly high-resolution screenshots. However, screenshots are tokenized into thousands of visual tokens (e.g., about 4700 for 2K resolution), incurring significant computational overhead and diluting attention. In contrast, humans typically focus on regions of interest when interacting with UI. In this work, we pioneer the task of efficient UI grounding. Guided by practical analysis of the task's characteristics and challenges, we propose FocusUI, an efficient UI grounding framework that selects patches most relevant to the instruction while preserving positional continuity for precise grounding. FocusUI addresses two key challenges: (1) Eliminating redundant tokens in visual encoding. We construct patch-level supervision by fusing an instruction-conditioned score with a rule-based UI-graph score that down-weights large homogeneous regions to select distinct and instruction-relevant visual tokens. (2) Preserving positional continuity during visual token selection. We find that general visual token pruning methods suffer from severe accuracy degradation on UI grounding tasks due to broken positional information. We introduce a novel PosPad strategy, which compresses each contiguous sequence of dropped visual tokens into a single special marker placed at the sequence's last index to preserve positional continuity. Comprehensive experiments on four grounding benchmarks demonstrate that FocusUI surpasses GUI-specific baselines. On the ScreenSpot-Pro benchmark, FocusUI-7B achieves a performance improvement of 3.7% over GUI-Actor-7B. Even with only 30% visual token retention, FocusUI-7B drops by only 3.2% while achieving up to 1.44x faster inference and 17% lower peak GPU memory.
Factorized Learning for Temporally Grounded Video-Language Models
Dec 30, 2025Recent video-language models have shown great potential for video understanding, but still struggle with accurate temporal grounding for event-level perception. We observe that two main factors in video understanding (i.e., temporal grounding and textual response) form a logical hierarchy: accurate temporal evidence grounding lays the foundation for reliable textual response. However, existing works typically handle these two tasks in a coupled manner without a clear logical structure, leading to sub-optimal objectives. We address this from a factorized learning perspective. We first propose D$^2$VLM, a framework that decouples the learning of these two tasks while also emphasizing their inherent dependency. We adopt a "grounding then answering with evidence referencing" paradigm and introduce evidence tokens for evidence grounding, which emphasize event-level visual semantic capture beyond the focus on timestamp representation in existing works. To further facilitate the learning of these two tasks, we introduce a novel factorized preference optimization (FPO) algorithm. Unlike standard preference optimization, FPO explicitly incorporates probabilistic temporal grounding modeling into the optimization objective, enabling preference learning for both temporal grounding and textual response. We also construct a synthetic dataset to address the lack of suitable datasets for factorized preference learning with explicit temporal grounding. Experiments on various tasks demonstrate the clear advantage of our approach. Our source code is available at https://github.com/nusnlp/d2vlm.
SlideTailor: Personalized Presentation Slide Generation for Scientific Papers
Dec 23, 2025Automatic presentation slide generation can greatly streamline content creation. However, since preferences of each user may vary, existing under-specified formulations often lead to suboptimal results that fail to align with individual user needs. We introduce a novel task that conditions paper-to-slides generation on user-specified preferences. We propose a human behavior-inspired agentic framework, SlideTailor, that progressively generates editable slides in a user-aligned manner. Instead of requiring users to write their preferences in detailed textual form, our system only asks for a paper-slides example pair and a visual template - natural and easy-to-provide artifacts that implicitly encode rich user preferences across content and visual style. Despite the implicit and unlabeled nature of these inputs, our framework effectively distills and generalizes the preferences to guide customized slide generation. We also introduce a novel chain-of-speech mechanism to align slide content with planned oral narration. Such a design significantly enhances the quality of generated slides and enables downstream applications like video presentations. To support this new task, we construct a benchmark dataset that captures diverse user preferences, with carefully designed interpretable metrics for robust evaluation. Extensive experiments demonstrate the effectiveness of our framework.
Just Go Parallel: Improving the Multilingual Capabilities of Large Language Models
Jun 16, 2025Large language models (LLMs) have demonstrated impressive translation capabilities even without being explicitly trained on parallel data. This remarkable property has led some to believe that parallel data is no longer necessary for building multilingual language models. While some attribute this to the emergent abilities of LLMs due to scale, recent work suggests that it is actually caused by incidental bilingual signals present in the training data. Various methods have been proposed to maximize the utility of parallel data to enhance the multilingual capabilities of multilingual encoder-based and encoder-decoder language models. However, some decoder-based LLMs opt to ignore parallel data instead. In this work, we conduct a systematic study on the impact of adding parallel data on LLMs' multilingual capabilities, focusing specifically on translation and multilingual common-sense reasoning. Through controlled experiments, we demonstrate that parallel data can significantly improve LLMs' multilingual capabilities.
The Hallucination Dilemma: Factuality-Aware Reinforcement Learning for Large Reasoning Models
May 30, 2025Large language models (LLMs) have significantly advanced in reasoning tasks through reinforcement learning (RL) optimization, achieving impressive capabilities across various challenging benchmarks. However, our empirical analysis reveals a critical drawback: reasoning-oriented RL fine-tuning significantly increases the prevalence of hallucinations. We theoretically analyze the RL training dynamics, identifying high-variance gradient, entropy-induced randomness, and susceptibility to spurious local optima as key factors leading to hallucinations. To address this drawback, we propose Factuality-aware Step-wise Policy Optimization (FSPO), an innovative RL fine-tuning algorithm incorporating explicit factuality verification at each reasoning step. FSPO leverages automated verification against given evidence to dynamically adjust token-level advantage values, incentivizing factual correctness throughout the reasoning process. Experiments across mathematical reasoning and hallucination benchmarks using Qwen2.5 and Llama models demonstrate that FSPO effectively reduces hallucinations while enhancing reasoning accuracy, substantially improving both reliability and performance.
Finding the Sweet Spot: Preference Data Construction for Scaling Preference Optimization
Feb 24, 2025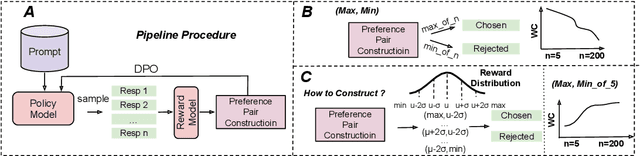
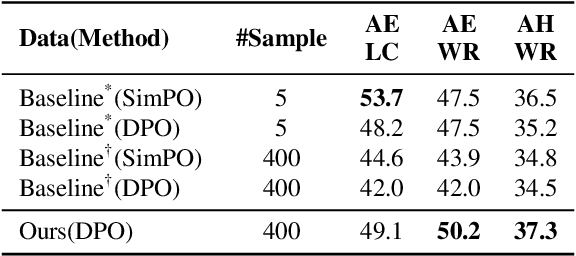
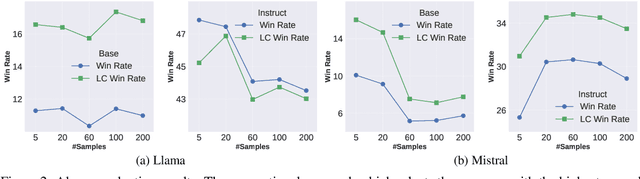
Iterative data generation and model retraining are widely used to align large language models (LLMs). It typically involves a policy model to generate on-policy responses and a reward model to guide training data selection. Direct Preference Optimization (DPO) further enhances this process by constructing preference pairs of chosen and rejected responses. In this work, we aim to \emph{scale up} the number of on-policy samples via repeated random sampling to improve alignment performance. Conventional practice selects the sample with the highest reward as chosen and the lowest as rejected for DPO. However, our experiments reveal that this strategy leads to a \emph{decline} in performance as the sample size increases. To address this, we investigate preference data construction through the lens of underlying normal distribution of sample rewards. We categorize the reward space into seven representative points and systematically explore all 21 ($C_7^2$) pairwise combinations. Through evaluations on four models using AlpacaEval 2, we find that selecting the rejected response at reward position $\mu - 2\sigma$ rather than the minimum reward, is crucial for optimal performance. We finally introduce a scalable preference data construction strategy that consistently enhances model performance as the sample scale increases.
Just What You Desire: Constrained Timeline Summarization with Self-Reflection for Enhanced Relevance
Dec 23, 2024



Given news articles about an entity, such as a public figure or organization, timeline summarization (TLS) involves generating a timeline that summarizes the key events about the entity. However, the TLS task is too underspecified, since what is of interest to each reader may vary, and hence there is not a single ideal or optimal timeline. In this paper, we introduce a novel task, called Constrained Timeline Summarization (CTLS), where a timeline is generated in which all events in the timeline meet some constraint. An example of a constrained timeline concerns the legal battles of Tiger Woods, where only events related to his legal problems are selected to appear in the timeline. We collected a new human-verified dataset of constrained timelines involving 47 entities and 5 constraints per entity. We propose an approach that employs a large language model (LLM) to summarize news articles according to a specified constraint and cluster them to identify key events to include in a constrained timeline. In addition, we propose a novel self-reflection method during summary generation, demonstrating that this approach successfully leads to improved performance.