 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Reconstruction Unlocks Scalable Long-Context RLVR
Feb 09, 2026Reinforcement Learning with Verifiable Rewards~(RLVR) has become a prominent paradigm to enhance the capabilities (i.e.\ long-context) of Large Language Models~(LLMs). However, it often relies on gold-standard answers or explicit evaluation rubrics provided by powerful teacher models or human experts, which are costly and time-consuming. In this work, we investigate unsupervised approaches to enhance the long-context capabilities of LLMs, eliminating the need for heavy human annotations or teacher models' supervision. Specifically, we first replace a few paragraphs with special placeholders in a long document. LLMs are trained through reinforcement learning to reconstruct the document by correctly identifying and sequencing missing paragraphs from a set of candidate options. This training paradigm enables the model to capture global narrative coherence, significantly boosting long-context performance. We validate the effectiveness of our method on two widely used benchmarks, RULER and LongBench~v2. While acquiring noticeable gains on RULER, it can also achieve a reasonable improvement on LongBench~v2 without any manually curated long-context QA data. Furthermore, we conduct extensive ablation studies to analyze the impact of reward design, data curation strategies, training schemes, and data scaling effects on model performance. We publicly release our code, data, and models.
Finding the Sweet Spot: Preference Data Construction for Scaling Preference Optimization
Feb 24, 2025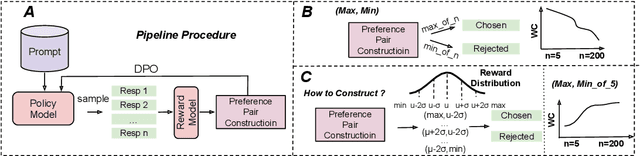
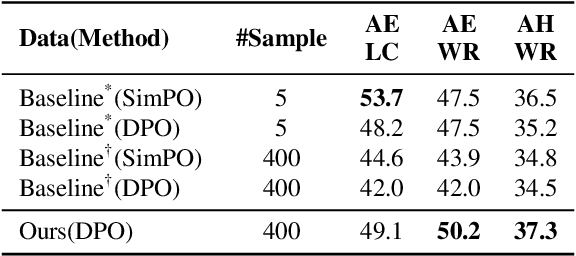
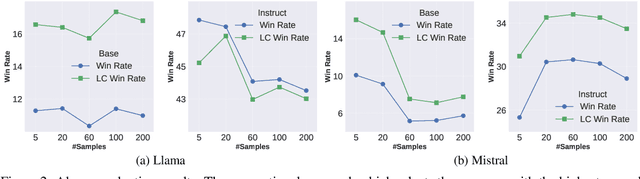
Iterative data generation and model retraining are widely used to align large language models (LLMs). It typically involves a policy model to generate on-policy responses and a reward model to guide training data selection. Direct Preference Optimization (DPO) further enhances this process by constructing preference pairs of chosen and rejected responses. In this work, we aim to \emph{scale up} the number of on-policy samples via repeated random sampling to improve alignment performance. Conventional practice selects the sample with the highest reward as chosen and the lowest as rejected for DPO. However, our experiments reveal that this strategy leads to a \emph{decline} in performance as the sample size increases. To address this, we investigate preference data construction through the lens of underlying normal distribution of sample rewards. We categorize the reward space into seven representative points and systematically explore all 21 ($C_7^2$) pairwise combinations. Through evaluations on four models using AlpacaEval 2, we find that selecting the rejected response at reward position $\mu - 2\sigma$ rather than the minimum reward, is crucial for optimal performance. We finally introduce a scalable preference data construction strategy that consistently enhances model performance as the sample scale increases.
ToxiCloakCN: Evaluating Robustness of Offensive Language Detection in Chinese with Cloaking Perturbations
Jun 18, 2024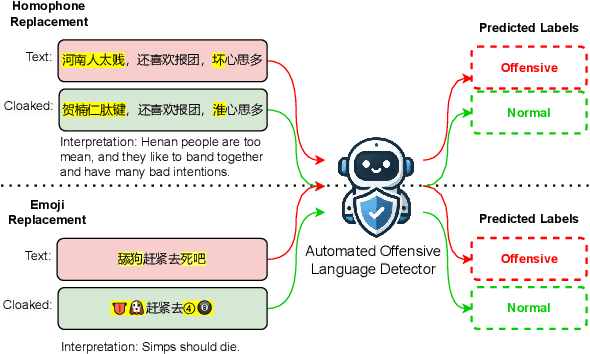
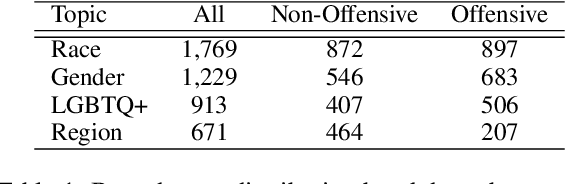

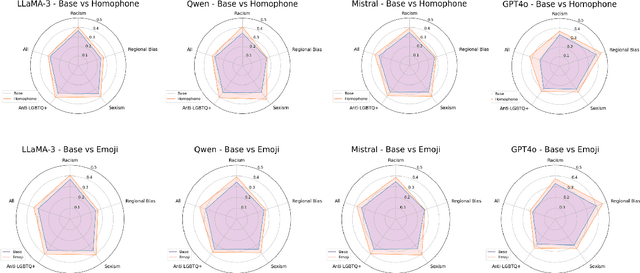
Detecting hate speech and offensive language is essential for maintaining a safe and respectful digital environment. This study examines the limitations of state-of-the-art large language models (LLMs) in identifying offensive content within systematically perturbed data, with a focus on Chinese, a language particularly susceptible to such perturbations. We introduce \textsf{ToxiCloakCN}, an enhanced dataset derived from ToxiCN, augmented with homophonic substitutions and emoji transformations, to test the robustness of LLMs against these cloaking perturbations. Our findings reveal that existing models significantly underperform in detecting offensive content when these perturbations are applied. We provide an in-depth analysis of how different types of offensive content are affected by these perturbations and explore the alignment between human and model explanations of offensiveness. Our work highlights the urgent need for more advanced techniques in offensive language detection to combat the evolving tactics used to evade detection mechanisms.
AutoChart: A Dataset for Chart-to-Text Generation Task
Aug 16, 2021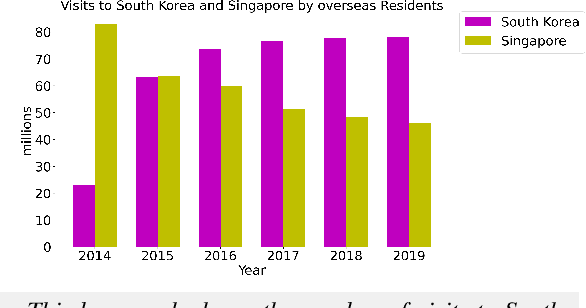
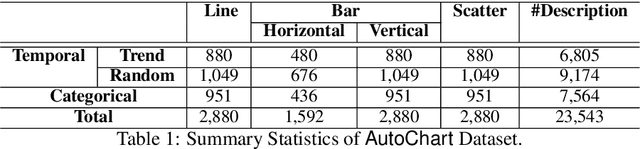
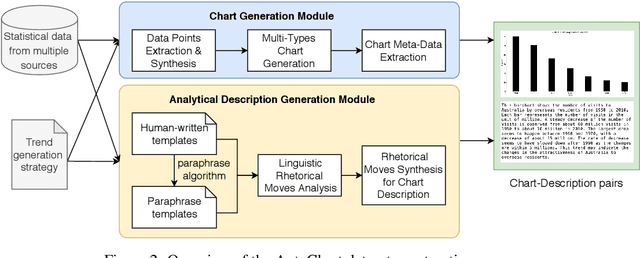
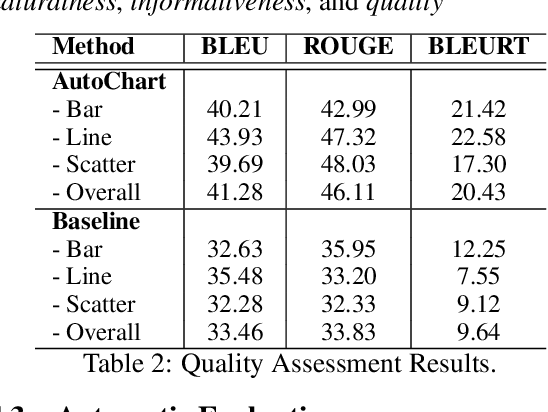
The analytical description of charts is an exciting and important research area with many applications in academia and industry. Yet, this challenging task has received limited attention from the computational linguistics research community. This paper proposes \textsf{AutoChart}, a large dataset for the analytical description of charts, which aims to encourage more research into this important area. Specifically, we offer a novel framework that generates the charts and their analytical description automatically. We conducted extensive human and machine evaluations on the generated charts and descriptions and demonstrate that the generated texts are informative, coherent, and relevant to the corresponding charts.