 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalyAgent: Training-Free Agentic Models for Zero-/Few-Shot Anomaly Detection
May 28, 2026Benefiting from generalizability of vision-language models (VLMs) such as CLIP, many zero-/few-shot anomaly detection (AD) approaches have achieved impressive detection performance across various datasets. Nevertheless, they require substantial training on large auxiliary datasets to adapt VLMs to anomaly detection, and their inference largely relies on visual-text embedding similarity-based anomaly scores, lacking reasoning abilities to detect complex anomalies that require in-depth contextual understanding. To address this limitation, we propose \textbf{AnomalyAgent}, a novel training-free, agentic framework that leverages the advanced reasoning and generalization capabilities of multimodal large language models (MLLMs) for anomaly detection. The key ingredients include \textbf{1)} a comprehensive anomaly-centric toolset that enables adaptive MLLM-driven, agentic anomaly reasoning in zero-shot settings, and \textbf{2)} a customized memory module that grounds anomaly reasoning with few-shot, in-context reference examples. We extend evaluation beyond the detection of simple anomalies (e.g., surface defects like cracks and dents and clear lesions) in widely used benchmarks to more diverse types of anomalies such as logical/contextual anomalies in logistics and manufacturing settings. Extensive experiment results demonstrate that our AnomalyAgent achieves substantially better performance compared to training-free VLM-based AD and generic agentic methods, highlighting its superior generalization capability in both zero-shot and few-shot anomaly detection settings. The code implementation can be find at this address.
Dynamic TMoE: A Drift-Aware Dynamic Mixture of Experts Framework for Non-Stationary Time Series Forecasting
May 20, 2026Non-stationary time series forecasting is challenged by evolving distribution shifts that static models struggle to capture. While Mixture-of-Experts (MoE) architectures offer a promising paradigm for decoupling complex drift patterns, existing approaches are limited by fixed expert pools and memoryless routing, hampering their ability to adapt to abrupt regime shifts. To address this, we propose Dynamic TMoE, a framework that unifies architectural evolution with temporal continuity during learning phase. By detecting distribution shifts via Maximum Mean Discrepancy (MMD), we dynamically instantiate heterogeneous experts and prune redundant ones to optimize capacity. Additionally, a temporal memory router leverages recurrent states and an anomaly repository to ensure stable, context-aware expert selection without requiring test-time updates. Experiments on nine benchmarks demonstrate state-of-the-art performance, reducing MSE by 10.4% and MAE by 7.8%. Code is available at https://github.com/andone-07/Dynamic-TMoE.
InCTRLv2: Generalist Residual Models for Few-Shot Anomaly Detection and Segmentation
Apr 06, 2026While recent anomaly detection (AD) methods have made substantial progress in recognizing abnormal patterns within specific domains, most of them are specialist models that are trained on large training samples from a specific target dataset, struggling to generalize to unseen datasets. To address this limitation, the paradigm of Generalist Anomaly Detection (GAD) has emerged in recent years, aiming to learn a single generalist model to detect anomalies across diverse domains without retraining. To this end, this work introduces InCTRLv2, a novel few-shot Generalist Anomaly Detection and Segmentation (GADS) framework that significantly extends our previously proposed GAD model, InCTRL. Building on the idea of learning in-context residuals with few-shot normal examples to detect anomalies as in InCTRL, InCTRLv2 introduces two new, complementary perspectives of anomaly perception under a dual-branch framework. This is accomplished by two novel modules upon InCTRL: i) Discriminative Anomaly Score Learning (DASL) with both normal and abnormal data in the main branch, which learns a semantic-guided abnormality and normality space that supports the classification of query samples from both the abnormality and normality perspectives; and ii) One-class Anomaly Score Learning (OASL) using only the normal data, which learns generalized normality patterns in a semantic space via an auxiliary branch, focusing on detecting anomalies through the lens of normality solely. Both branches are guided by rich visual-text semantic priors encoded by large-scale vision-language models. Together, they offer a dual semantic perspective for AD: one emphasizes normal-abnormal discriminations, while the other emphasizes normality-deviated semantics. Extensive experiments on ten AD datasets demonstrate that InCTRLv2 achieves SotA performance in both anomaly detection and segmentation tasks across various settings.
Unleashing Vision-Language Semantics for Deepfake Video Detection
Mar 25, 2026Recent Deepfake Video Detection (DFD) studies have demonstrated that pre-trained Vision-Language Models (VLMs) such as CLIP exhibit strong generalization capabilities in detecting artifacts across different identities. However, existing approaches focus on leveraging visual features only, overlooking their most distinctive strength -- the rich vision-language semantics embedded in the latent space. We propose VLAForge, a novel DFD framework that unleashes the potential of such cross-modal semantics to enhance model's discriminability in deepfake detection. This work i) enhances the visual perception of VLM through a ForgePerceiver, which acts as an independent learner to capture diverse, subtle forgery cues both granularly and holistically, while preserving the pretrained Vision-Language Alignment (VLA) knowledge, and ii) provides a complementary discriminative cue -- Identity-Aware VLA score, derived by coupling cross-modal semantics with the forgery cues learned by ForgePerceiver. Notably, the VLA score is augmented by an identity prior-informed text prompting to capture authenticity cues tailored to each identity, thereby enabling more discriminative cross-modal semantics. Comprehensive experiments on video DFD benchmarks, including classical face-swapping forgeries and recent full-face generation forgeries, demonstrate that our VLAForge substantially outperforms state-of-the-art methods at both frame and video levels. Code is available at https://github.com/mala-lab/VLAForge.
YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection
Dec 30, 2025Existing Real-Time Object Detection (RTOD) methods commonly adopt YOLO-like architectures for their favorable trade-off between accuracy and speed. However, these models rely on static dense computation that applies uniform processing to all inputs, misallocating representational capacity and computational resources such as over-allocating on trivial scenes while under-serving complex ones. This mismatch results in both computational redundancy and suboptimal detection performance. To overcome this limitation, we propose YOLO-Master, a novel YOLO-like framework that introduces instance-conditional adaptive computation for RTOD. This is achieved through a Efficient Sparse Mixture-of-Experts (ES-MoE) block that dynamically allocates computational resources to each input according to its scene complexity. At its core, a lightweight dynamic routing network guides expert specialization during training through a diversity enhancing objective, encouraging complementary expertise among experts. Additionally, the routing network adaptively learns to activate only the most relevant experts, thereby improving detection performance while minimizing computational overhead during inference. Comprehensive experiments on five large-scale benchmarks demonstrate the superiority of YOLO-Master. On MS COCO, our model achieves 42.4% AP with 1.62ms latency, outperforming YOLOv13-N by +0.8% mAP and 17.8% faster inference. Notably, the gains are most pronounced on challenging dense scenes, while the model preserves efficiency on typical inputs and maintains real-time inference speed. Code will be available.
Regularizing Subspace Redundancy of Low-Rank Adaptation
Jul 28, 2025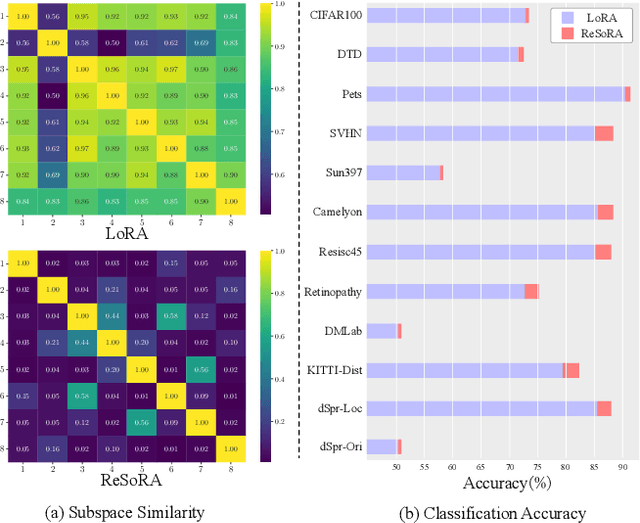
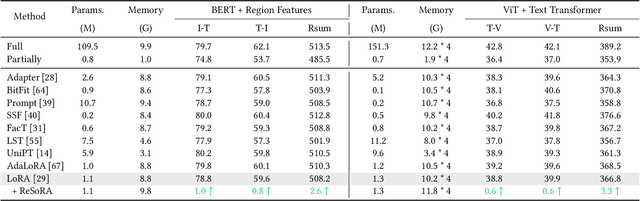
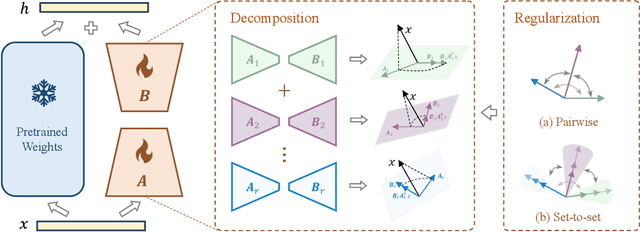
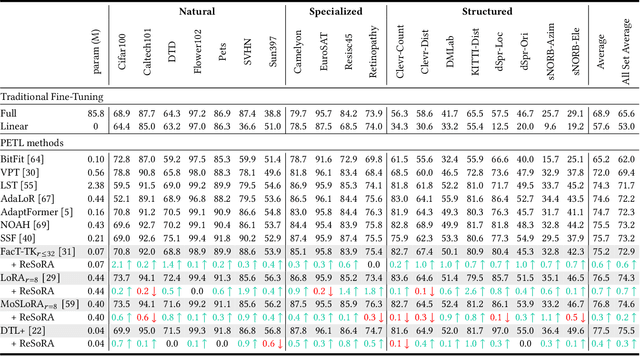
Low-Rank Adaptation (LoRA) and its variants have delivered strong capability in Parameter-Efficient Transfer Learning (PETL) by minimizing trainable parameters and benefiting from reparameterization. However, their projection matrices remain unrestricted during training, causing high representation redundancy and diminishing the effectiveness of feature adaptation in the resulting subspaces. While existing methods mitigate this by manually adjusting the rank or implicitly applying channel-wise masks, they lack flexibility and generalize poorly across various datasets and architectures. Hence, we propose ReSoRA, a method that explicitly models redundancy between mapping subspaces and adaptively Regularizes Subspace redundancy of Low-Rank Adaptation. Specifically, it theoretically decomposes the low-rank submatrices into multiple equivalent subspaces and systematically applies de-redundancy constraints to the feature distributions across different projections. Extensive experiments validate that our proposed method consistently facilitates existing state-of-the-art PETL methods across various backbones and datasets in vision-language retrieval and standard visual classification benchmarks. Besides, as a training supervision, ReSoRA can be seamlessly integrated into existing approaches in a plug-and-play manner, with no additional inference costs. Code is publicly available at: https://github.com/Lucenova/ReSoRA.
Adapting Large Language Models for Parameter-Efficient Log Anomaly Detection
Mar 11, 2025Log Anomaly Detection (LAD) seeks to identify atypical patterns in log data that are crucial to assessing the security and condition of systems. Although Large Language Models (LLMs) have shown tremendous success in various fields, the use of LLMs in enabling the detection of log anomalies is largely unexplored. This work aims to fill this gap. Due to the prohibitive costs involved in fully fine-tuning LLMs, we explore the use of parameter-efficient fine-tuning techniques (PEFTs) for adapting LLMs to LAD. To have an in-depth exploration of the potential of LLM-driven LAD, we present a comprehensive investigation of leveraging two of the most popular PEFTs -- Low-Rank Adaptation (LoRA) and Representation Fine-tuning (ReFT) -- to tap into three prominent LLMs of varying size, including RoBERTa, GPT-2, and Llama-3, for parameter-efficient LAD. Comprehensive experiments on four public log datasets are performed to reveal important insights into effective LLM-driven LAD in several key perspectives, including the efficacy of these PEFT-based LLM-driven LAD methods, their stability, sample efficiency, robustness w.r.t. unstable logs, and cross-dataset generalization. Code is available at https://github.com/mala-lab/LogADReft.
3UR-LLM: An End-to-End Multimodal Large Language Model for 3D Scene Understanding
Jan 14, 2025Multi-modal Large Language Models (MLLMs) exhibit impressive capabilities in 2D tasks, yet encounter challenges in discerning the spatial positions, interrelations, and causal logic in scenes when transitioning from 2D to 3D representations. We find that the limitations mainly lie in: i) the high annotation cost restricting the scale-up of volumes of 3D scene data, and ii) the lack of a straightforward and effective way to perceive 3D information which results in prolonged training durations and complicates the streamlined framework. To this end, we develop pipeline based on open-source 2D MLLMs and LLMs to generate high-quality 3D-text pairs and construct 3DS-160K , to enhance the pre-training process. Leveraging this high-quality pre-training data, we introduce the 3UR-LLM model, an end-to-end 3D MLLM designed for precise interpretation of 3D scenes, showcasing exceptional capability in navigating the complexities of the physical world. 3UR-LLM directly receives 3D point cloud as input and project 3D features fused with text instructions into a manageable set of tokens. Considering the computation burden derived from these hybrid tokens, we design a 3D compressor module to cohesively compress the 3D spatial cues and textual narrative. 3UR-LLM achieves promising performance with respect to the previous SOTAs, for instance, 3UR-LLM exceeds its counterparts by 7.1\% CIDEr on ScanQA, while utilizing fewer training resources. The code and model weights for 3UR-LLM and the 3DS-160K benchmark are available at 3UR-LLM.
SUTrack: Towards Simple and Unified Single Object Tracking
Dec 26, 2024



In this paper, we propose a simple yet unified single object tracking (SOT) framework, dubbed SUTrack. It consolidates five SOT tasks (RGB-based, RGB-Depth, RGB-Thermal, RGB-Event, RGB-Language Tracking) into a unified model trained in a single session. Due to the distinct nature of the data, current methods typically design individual architectures and train separate models for each task. This fragmentation results in redundant training processes, repetitive technological innovations, and limited cross-modal knowledge sharing. In contrast, SUTrack demonstrates that a single model with a unified input representation can effectively handle various common SOT tasks, eliminating the need for task-specific designs and separate training sessions. Additionally, we introduce a task-recognition auxiliary training strategy and a soft token type embedding to further enhance SUTrack's performance with minimal overhead. Experiments show that SUTrack outperforms previous task-specific counterparts across 11 datasets spanning five SOT tasks. Moreover, we provide a range of models catering edge devices as well as high-performance GPUs, striking a good trade-off between speed and accuracy. We hope SUTrack could serve as a strong foundation for further compelling research into unified tracking models. Code and models are available at github.com/chenxin-dlut/SUTrack.
UCDR-Adapter: Exploring Adaptation of Pre-Trained Vision-Language Models for Universal Cross-Domain Retrieval
Dec 14, 2024



Universal Cross-Domain Retrieval (UCDR) retrieves relevant images from unseen domains and classes without semantic labels, ensuring robust generalization. Existing methods commonly employ prompt tuning with pre-trained vision-language models but are inherently limited by static prompts, reducing adaptability. We propose UCDR-Adapter, which enhances pre-trained models with adapters and dynamic prompt generation through a two-phase training strategy. First, Source Adapter Learning integrates class semantics with domain-specific visual knowledge using a Learnable Textual Semantic Template and optimizes Class and Domain Prompts via momentum updates and dual loss functions for robust alignment. Second, Target Prompt Generation creates dynamic prompts by attending to masked source prompts, enabling seamless adaptation to unseen domains and classes. Unlike prior approaches, UCDR-Adapter dynamically adapts to evolving data distributions, enhancing both flexibility and generalization. During inference, only the image branch and generated prompts are used, eliminating reliance on textual inputs for highly efficient retrieval. Extensive benchmark experiments show that UCDR-Adapter consistently outperforms ProS in most cases and other state-of-the-art methods on UCDR, U(c)CDR, and U(d)CDR settings.