 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Dynamic Transformer for Efficient Object Tracking
Paper and Code
Mar 26, 2024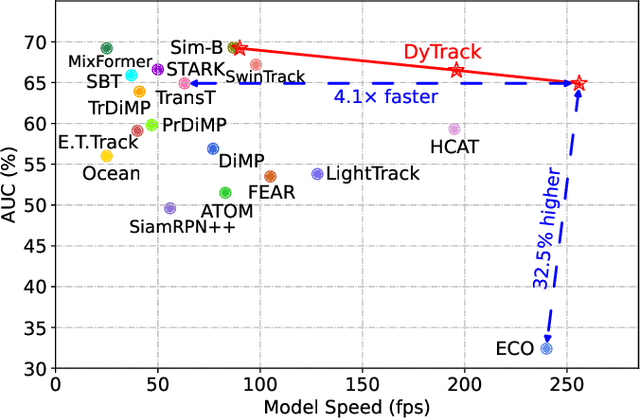



The speed-precision trade-off is a critical problem for visual object tracking which usually requires low latency and deployment on constrained resources. Existing solutions for efficient tracking mainly focus on adopting light-weight backbones or modules, which nevertheless come at the cost of a sacrifice in precision. In this paper, inspired by dynamic network routing, we propose DyTrack, a dynamic transformer framework for efficient tracking. Real-world tracking scenarios exhibit diverse levels of complexity. We argue that a simple network is sufficient for easy frames in video sequences, while more computation could be assigned to difficult ones. DyTrack automatically learns to configure proper reasoning routes for various inputs, gaining better utilization of the available computational budget. Thus, it can achieve higher performance with the same running speed. We formulate instance-specific tracking as a sequential decision problem and attach terminating branches to intermediate layers of the entire model. Especially, to fully utilize the computations, we introduce the feature recycling mechanism to reuse the outputs of predecessors. Furthermore, a target-aware self-distillation strategy is designed to enhance the discriminating capabilities of early predictions by effectively mimicking the representation pattern of the deep model. Extensive experiments on multiple benchmarks demonstrate that DyTrack achieves promising speed-precision trade-offs with only a single model. For instance, DyTrack obtains 64.9% AUC on LaSOT with a speed of 256 fps.