 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUETrack: A Unified and Efficient Framework for Single Object Tracking
Mar 03, 2026With growing real-world demands, efficient tracking has received increasing attention. However, most existing methods are limited to RGB inputs and struggle in multi-modal scenarios. Moreover, current multi-modal tracking approaches typically use complex designs, making them too heavy and slow for resource-constrained deployment. To tackle these limitations, we propose UETrack, an efficient framework for single object tracking. UETrack demonstrates high practicality and versatility, efficiently handling multiple modalities including RGB, Depth, Thermal, Event, and Language, and addresses the gap in efficient multi-modal tracking. It introduces two key components: a Token-Pooling-based Mixture-of-Experts mechanism that enhances modeling capacity through feature aggregation and expert specialization, and a Target-aware Adaptive Distillation strategy that selectively performs distillation based on sample characteristics, reducing redundant supervision and improving performance. Extensive experiments on 12 benchmarks across 3 hardware platforms show that UETrack achieves a superior speed-accuracy trade-off compared to previous methods. For instance, UETrack-B achieves 69.2% AUC on LaSOT and runs at 163/56/60 FPS on GPU/CPU/AGX, demonstrating strong practicality and versatility. Code is available at https://github.com/kangben258/UETrack.
SUTrack: Towards Simple and Unified Single Object Tracking
Dec 26, 2024



In this paper, we propose a simple yet unified single object tracking (SOT) framework, dubbed SUTrack. It consolidates five SOT tasks (RGB-based, RGB-Depth, RGB-Thermal, RGB-Event, RGB-Language Tracking) into a unified model trained in a single session. Due to the distinct nature of the data, current methods typically design individual architectures and train separate models for each task. This fragmentation results in redundant training processes, repetitive technological innovations, and limited cross-modal knowledge sharing. In contrast, SUTrack demonstrates that a single model with a unified input representation can effectively handle various common SOT tasks, eliminating the need for task-specific designs and separate training sessions. Additionally, we introduce a task-recognition auxiliary training strategy and a soft token type embedding to further enhance SUTrack's performance with minimal overhead. Experiments show that SUTrack outperforms previous task-specific counterparts across 11 datasets spanning five SOT tasks. Moreover, we provide a range of models catering edge devices as well as high-performance GPUs, striking a good trade-off between speed and accuracy. We hope SUTrack could serve as a strong foundation for further compelling research into unified tracking models. Code and models are available at github.com/chenxin-dlut/SUTrack.
Exploring Enhanced Contextual Information for Video-Level Object Tracking
Dec 15, 2024
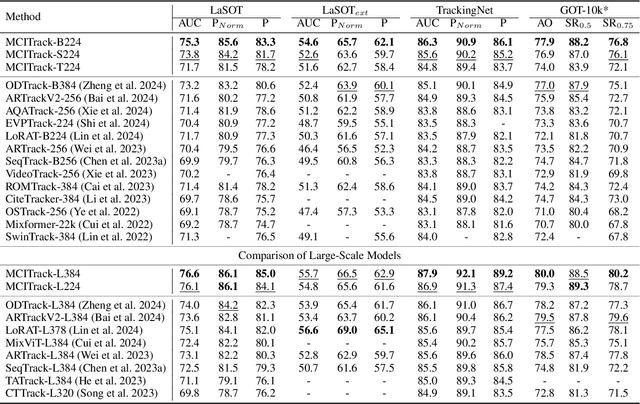
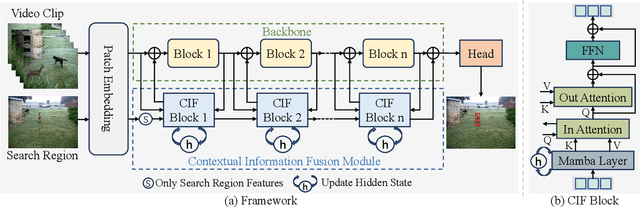
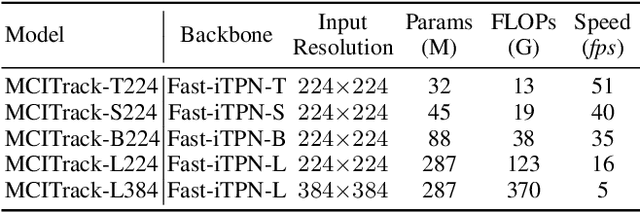
Contextual information at the video level has become increasingly crucial for visual object tracking. However, existing methods typically use only a few tokens to convey this information, which can lead to information loss and limit their ability to fully capture the context. To address this issue, we propose a new video-level visual object tracking framework called MCITrack. It leverages Mamba's hidden states to continuously record and transmit extensive contextual information throughout the video stream, resulting in more robust object tracking. The core component of MCITrack is the Contextual Information Fusion module, which consists of the mamba layer and the cross-attention layer. The mamba layer stores historical contextual information, while the cross-attention layer integrates this information into the current visual features of each backbone block. This module enhances the model's ability to capture and utilize contextual information at multiple levels through deep integration with the backbone. Experiments demonstrate that MCITrack achieves competitive performance across numerous benchmarks. For instance, it gets 76.6% AUC on LaSOT and 80.0% AO on GOT-10k, establishing a new state-of-the-art performance. Code and models are available at https://github.com/kangben258/MCITrack.
MambaVT: Spatio-Temporal Contextual Modeling for robust RGB-T Tracking
Aug 15, 2024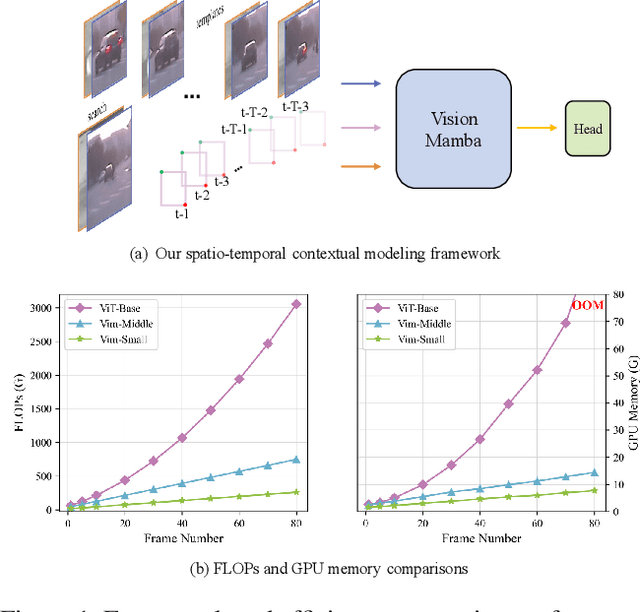
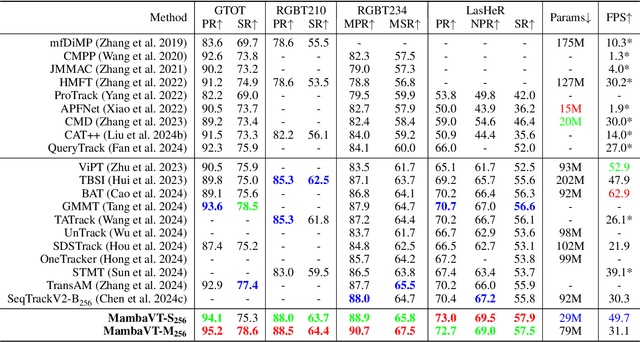
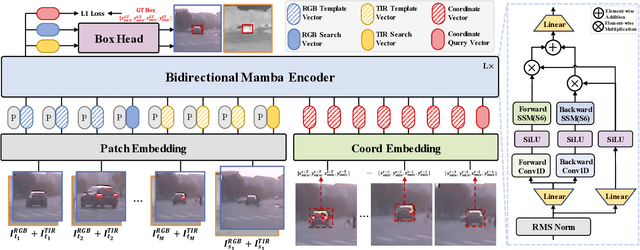
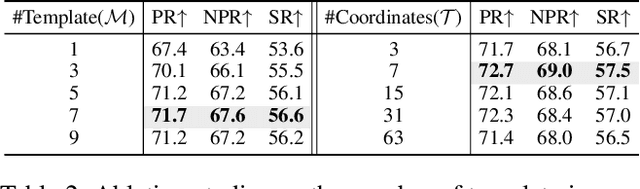
Existing RGB-T tracking algorithms have made remarkable progress by leveraging the global interaction capability and extensive pre-trained models of the Transformer architecture. Nonetheless, these methods mainly adopt imagepair appearance matching and face challenges of the intrinsic high quadratic complexity of the attention mechanism, resulting in constrained exploitation of temporal information. Inspired by the recently emerged State Space Model Mamba, renowned for its impressive long sequence modeling capabilities and linear computational complexity, this work innovatively proposes a pure Mamba-based framework (MambaVT) to fully exploit spatio-temporal contextual modeling for robust visible-thermal tracking. Specifically, we devise the long-range cross-frame integration component to globally adapt to target appearance variations, and introduce short-term historical trajectory prompts to predict the subsequent target states based on local temporal location clues. Extensive experiments show the significant potential of vision Mamba for RGB-T tracking, with MambaVT achieving state-of-the-art performance on four mainstream benchmarks while requiring lower computational costs. We aim for this work to serve as a simple yet strong baseline, stimulating future research in this field. The code and pre-trained models will be made available.
Exploring Lightweight Hierarchical Vision Transformers for Efficient Visual Tracking
Aug 14, 2023



Transformer-based visual trackers have demonstrated significant progress owing to their superior modeling capabilities. However, existing trackers are hampered by low speed, limiting their applicability on devices with limited computational power. To alleviate this problem, we propose HiT, a new family of efficient tracking models that can run at high speed on different devices while retaining high performance. The central idea of HiT is the Bridge Module, which bridges the gap between modern lightweight transformers and the tracking framework. The Bridge Module incorporates the high-level information of deep features into the shallow large-resolution features. In this way, it produces better features for the tracking head. We also propose a novel dual-image position encoding technique that simultaneously encodes the position information of both the search region and template images. The HiT model achieves promising speed with competitive performance. For instance, it runs at 61 frames per second (fps) on the Nvidia Jetson AGX edge device. Furthermore, HiT attains 64.6% AUC on the LaSOT benchmark, surpassing all previous efficient trackers.
3rd Place Solution for PVUW2023 VSS Track: A Large Model for Semantic Segmentation on VSPW
Jun 06, 2023



In this paper, we introduce 3rd place solution for PVUW2023 VSS track. Semantic segmentation is a fundamental task in computer vision with numerous real-world applications. We have explored various image-level visual backbones and segmentation heads to tackle the problem of video semantic segmentation. Through our experimentation, we find that InternImage-H as the backbone and Mask2former as the segmentation head achieves the best performance. In addition, we explore two post-precessing methods: CascadePSP and Segment Anything Model (SAM). Ultimately, our approach obtains 62.60\% and 64.84\% mIoU on the VSPW test set1 and final test set, respectively, securing the third position in the PVUW2023 VSS track.