 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Enhanced Contextual Information for Video-Level Object Tracking
Paper and Code
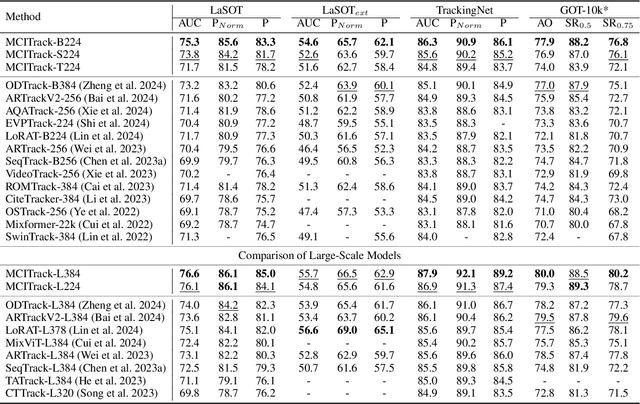
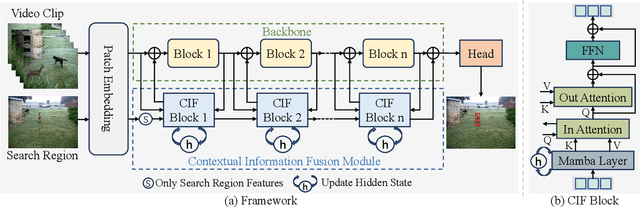
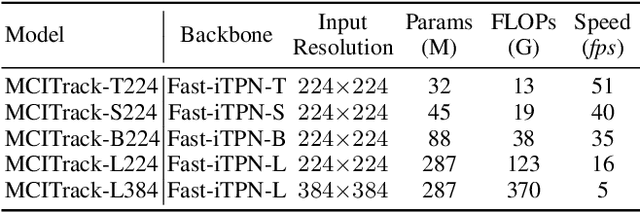
Contextual information at the video level has become increasingly crucial for visual object tracking. However, existing methods typically use only a few tokens to convey this information, which can lead to information loss and limit their ability to fully capture the context. To address this issue, we propose a new video-level visual object tracking framework called MCITrack. It leverages Mamba's hidden states to continuously record and transmit extensive contextual information throughout the video stream, resulting in more robust object tracking. The core component of MCITrack is the Contextual Information Fusion module, which consists of the mamba layer and the cross-attention layer. The mamba layer stores historical contextual information, while the cross-attention layer integrates this information into the current visual features of each backbone block. This module enhances the model's ability to capture and utilize contextual information at multiple levels through deep integration with the backbone. Experiments demonstrate that MCITrack achieves competitive performance across numerous benchmarks. For instance, it gets 76.6% AUC on LaSOT and 80.0% AO on GOT-10k, establishing a new state-of-the-art performance. Code and models are available at https://github.com/kangben258/MCITrack.