 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePulseMind: A Multi-Modal Medical Model for Real-World Clinical Diagnosis
Jan 12, 2026Recent advances in medical multi-modal models focus on specialized image analysis like dermatology, pathology, or radiology. However, they do not fully capture the complexity of real-world clinical diagnostics, which involve heterogeneous inputs and require ongoing contextual understanding during patient-physician interactions. To bridge this gap, we introduce PulseMind, a new family of multi-modal diagnostic models that integrates a systematically curated dataset, a comprehensive evaluation benchmark, and a tailored training framework. Specifically, we first construct a diagnostic dataset, MediScope, which comprises 98,000 real-world multi-turn consultations and 601,500 medical images, spanning over 10 major clinical departments and more than 200 sub-specialties. Then, to better reflect the requirements of real-world clinical diagnosis, we develop the PulseMind Benchmark, a multi-turn diagnostic consultation benchmark with a four-dimensional evaluation protocol comprising proactiveness, accuracy, usefulness, and language quality. Finally, we design a training framework tailored for multi-modal clinical diagnostics, centered around a core component named Comparison-based Reinforcement Policy Optimization (CRPO). Compared to absolute score rewards, CRPO uses relative preference signals from multi-dimensional com-parisons to provide stable and human-aligned training guidance. Extensive experiments demonstrate that PulseMind achieves competitive performance on both the diagnostic consultation benchmark and public medical benchmarks.
Learning Dynamic Collaborative Network for Semi-supervised 3D Vessel Segmentation
Jan 12, 2026In this paper, we present a new dynamic collaborative network for semi-supervised 3D vessel segmentation, termed DiCo. Conventional mean teacher (MT) methods typically employ a static approach, where the roles of the teacher and student models are fixed. However, due to the complexity of 3D vessel data, the teacher model may not always outperform the student model, leading to cognitive biases that can limit performance. To address this issue, we propose a dynamic collaborative network that allows the two models to dynamically switch their teacher-student roles. Additionally, we introduce a multi-view integration module to capture various perspectives of the inputs, mirroring the way doctors conduct medical analysis. We also incorporate adversarial supervision to constrain the shape of the segmented vessels in unlabeled data. In this process, the 3D volume is projected into 2D views to mitigate the impact of label inconsistencies. Experiments demonstrate that our DiCo method sets new state-of-the-art performance on three 3D vessel segmentation benchmarks. The code repository address is https://github.com/xujiaommcome/DiCo
Referring Camouflaged Object Detection With Multi-Context Overlapped Windows Cross-Attention
Nov 17, 2025Referring camouflaged object detection (Ref-COD) aims to identify hidden objects by incorporating reference information such as images and text descriptions. Previous research has transformed reference images with salient objects into one-dimensional prompts, yielding significant results. We explore ways to enhance performance through multi-context fusion of rich salient image features and camouflaged object features. Therefore, we propose RFMNet, which utilizes features from multiple encoding stages of the reference salient images and performs interactive fusion with the camouflage features at the corresponding encoding stages. Given that the features in salient object images contain abundant object-related detail information, performing feature fusion within local areas is more beneficial for detecting camouflaged objects. Therefore, we propose an Overlapped Windows Cross-attention mechanism to enable the model to focus more attention on the local information matching based on reference features. Besides, we propose the Referring Feature Aggregation (RFA) module to decode and segment the camouflaged objects progressively. Extensive experiments on the Ref-COD benchmark demonstrate that our method achieves state-of-the-art performance.
UniMRSeg: Unified Modality-Relax Segmentation via Hierarchical Self-Supervised Compensation
Sep 19, 2025Multi-modal image segmentation faces real-world deployment challenges from incomplete/corrupted modalities degrading performance. While existing methods address training-inference modality gaps via specialized per-combination models, they introduce high deployment costs by requiring exhaustive model subsets and model-modality matching. In this work, we propose a unified modality-relax segmentation network (UniMRSeg) through hierarchical self-supervised compensation (HSSC). Our approach hierarchically bridges representation gaps between complete and incomplete modalities across input, feature and output levels. % First, we adopt modality reconstruction with the hybrid shuffled-masking augmentation, encouraging the model to learn the intrinsic modality characteristics and generate meaningful representations for missing modalities through cross-modal fusion. % Next, modality-invariant contrastive learning implicitly compensates the feature space distance among incomplete-complete modality pairs. Furthermore, the proposed lightweight reverse attention adapter explicitly compensates for the weak perceptual semantics in the frozen encoder. Last, UniMRSeg is fine-tuned under the hybrid consistency constraint to ensure stable prediction under all modality combinations without large performance fluctuations. Without bells and whistles, UniMRSeg significantly outperforms the state-of-the-art methods under diverse missing modality scenarios on MRI-based brain tumor segmentation, RGB-D semantic segmentation, RGB-D/T salient object segmentation. The code will be released at https://github.com/Xiaoqi-Zhao-DLUT/UniMRSeg.
Power Battery Detection
Aug 11, 2025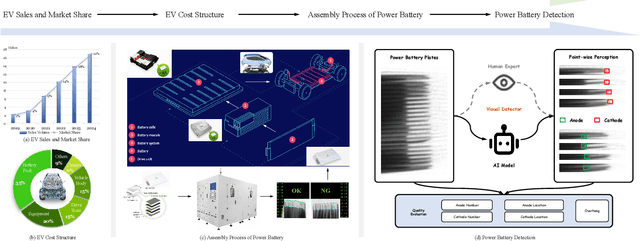



Power batteries are essential components in electric vehicles, where internal structural defects can pose serious safety risks. We conduct a comprehensive study on a new task, power battery detection (PBD), which aims to localize the dense endpoints of cathode and anode plates from industrial X-ray images for quality inspection. Manual inspection is inefficient and error-prone, while traditional vision algorithms struggle with densely packed plates, low contrast, scale variation, and imaging artifacts. To address this issue and drive more attention into this meaningful task, we present PBD5K, the first large-scale benchmark for this task, consisting of 5,000 X-ray images from nine battery types with fine-grained annotations and eight types of real-world visual interference. To support scalable and consistent labeling, we develop an intelligent annotation pipeline that combines image filtering, model-assisted pre-labeling, cross-verification, and layered quality evaluation. We formulate PBD as a point-level segmentation problem and propose MDCNeXt, a model designed to extract and integrate multi-dimensional structure clues including point, line, and count information from the plate itself. To improve discrimination between plates and suppress visual interference, MDCNeXt incorporates two state space modules. The first is a prompt-filtered module that learns contrastive relationships guided by task-specific prompts. The second is a density-aware reordering module that refines segmentation in regions with high plate density. In addition, we propose a distance-adaptive mask generation strategy to provide robust supervision under varying spatial distributions of anode and cathode positions. The source code and datasets will be publicly available at \href{https://github.com/Xiaoqi-Zhao-DLUT/X-ray-PBD}{PBD5K}.
EffOWT: Transfer Visual Language Models to Open-World Tracking Efficiently and Effectively
Apr 09, 2025Open-World Tracking (OWT) aims to track every object of any category, which requires the model to have strong generalization capabilities. Trackers can improve their generalization ability by leveraging Visual Language Models (VLMs). However, challenges arise with the fine-tuning strategies when VLMs are transferred to OWT: full fine-tuning results in excessive parameter and memory costs, while the zero-shot strategy leads to sub-optimal performance. To solve the problem, EffOWT is proposed for efficiently transferring VLMs to OWT. Specifically, we build a small and independent learnable side network outside the VLM backbone. By freezing the backbone and only executing backpropagation on the side network, the model's efficiency requirements can be met. In addition, EffOWT enhances the side network by proposing a hybrid structure of Transformer and CNN to improve the model's performance in the OWT field. Finally, we implement sparse interactions on the MLP, thus reducing parameter updates and memory costs significantly. Thanks to the proposed methods, EffOWT achieves an absolute gain of 5.5% on the tracking metric OWTA for unknown categories, while only updating 1.3% of the parameters compared to full fine-tuning, with a 36.4% memory saving. Other metrics also demonstrate obvious improvement.
AdvAnchor: Enhancing Diffusion Model Unlearning with Adversarial Anchors
Dec 28, 2024Security concerns surrounding text-to-image diffusion models have driven researchers to unlearn inappropriate concepts through fine-tuning. Recent fine-tuning methods typically align the prediction distributions of unsafe prompts with those of predefined text anchors. However, these techniques exhibit a considerable performance trade-off between eliminating undesirable concepts and preserving other concepts. In this paper, we systematically analyze the impact of diverse text anchors on unlearning performance. Guided by this analysis, we propose AdvAnchor, a novel approach that generates adversarial anchors to alleviate the trade-off issue. These adversarial anchors are crafted to closely resemble the embeddings of undesirable concepts to maintain overall model performance, while selectively excluding defining attributes of these concepts for effective erasure. Extensive experiments demonstrate that AdvAnchor outperforms state-of-the-art methods. Our code is publicly available at https://anonymous.4open.science/r/AdvAnchor.
Inspiring the Next Generation of Segment Anything Models: Comprehensively Evaluate SAM and SAM 2 with Diverse Prompts Towards Context-Dependent Concepts under Different Scenes
Dec 02, 2024As a foundational model, SAM has significantly influenced multiple fields within computer vision, and its upgraded version, SAM 2, enhances capabilities in video segmentation, poised to make a substantial impact once again. While SAMs (SAM and SAM 2) have demonstrated excellent performance in segmenting context-independent concepts like people, cars, and roads, they overlook more challenging context-dependent (CD) concepts, such as visual saliency, camouflage, product defects, and medical lesions. CD concepts rely heavily on global and local contextual information, making them susceptible to shifts in different contexts, which requires strong discriminative capabilities from the model. The lack of comprehensive evaluation of SAMs limits understanding of their performance boundaries, which may hinder the design of future models. In this paper, we conduct a thorough quantitative evaluation of SAMs on 11 CD concepts across 2D and 3D images and videos in various visual modalities within natural, medical, and industrial scenes. We develop a unified evaluation framework for SAM and SAM 2 that supports manual, automatic, and intermediate self-prompting, aided by our specific prompt generation and interaction strategies. We further explore the potential of SAM 2 for in-context learning and introduce prompt robustness testing to simulate real-world imperfect prompts. Finally, we analyze the benefits and limitations of SAMs in understanding CD concepts and discuss their future development in segmentation tasks. This work aims to provide valuable insights to guide future research in both context-independent and context-dependent concepts segmentation, potentially informing the development of the next version - SAM 3.
Adversarial Training: A Survey
Oct 19, 2024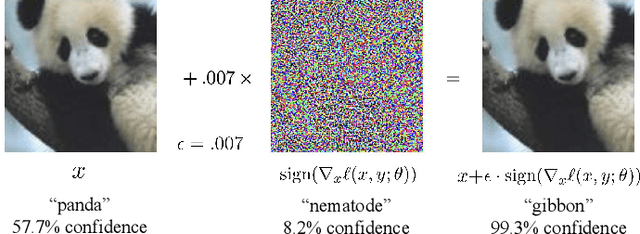
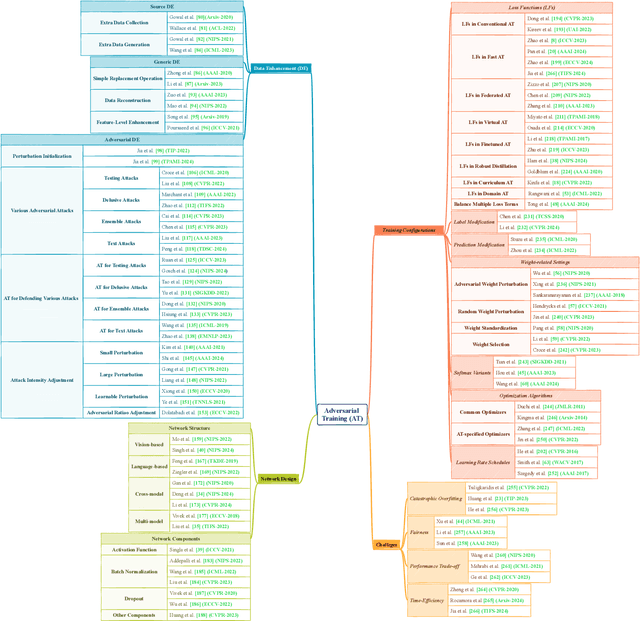
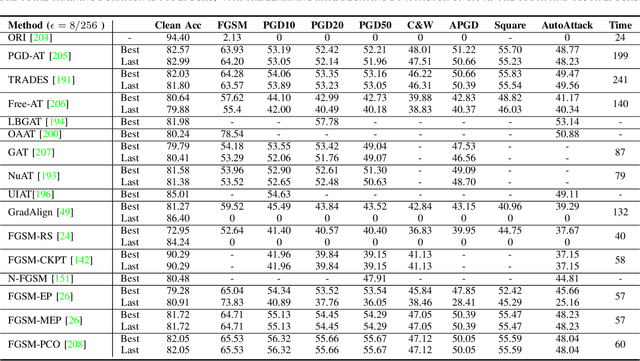
Adversarial training (AT) refers to integrating adversarial examples -- inputs altered with imperceptible perturbations that can significantly impact model predictions -- into the training process. Recent studies have demonstrated the effectiveness of AT in improving the robustness of deep neural networks against diverse adversarial attacks. However, a comprehensive overview of these developments is still missing. This survey addresses this gap by reviewing a broad range of recent and representative studies. Specifically, we first describe the implementation procedures and practical applications of AT, followed by a comprehensive review of AT techniques from three perspectives: data enhancement, network design, and training configurations. Lastly, we discuss common challenges in AT and propose several promising directions for future research.
High-Precision Dichotomous Image Segmentation via Probing Diffusion Capacity
Oct 14, 2024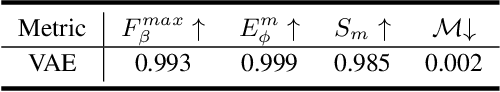
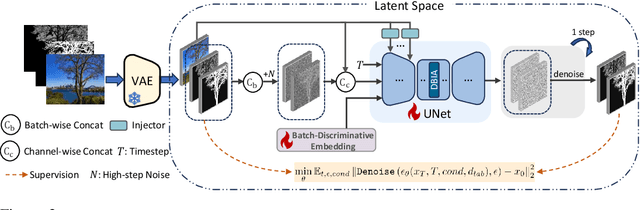


In the realm of high-resolution (HR), fine-grained image segmentation, the primary challenge is balancing broad contextual awareness with the precision required for detailed object delineation, capturing intricate details and the finest edges of objects. Diffusion models, trained on vast datasets comprising billions of image-text pairs, such as SD V2.1, have revolutionized text-to-image synthesis by delivering exceptional quality, fine detail resolution, and strong contextual awareness, making them an attractive solution for high-resolution image segmentation. To this end, we propose DiffDIS, a diffusion-driven segmentation model that taps into the potential of the pre-trained U-Net within diffusion models, specifically designed for high-resolution, fine-grained object segmentation. By leveraging the robust generalization capabilities and rich, versatile image representation prior of the SD models, coupled with a task-specific stable one-step denoising approach, we significantly reduce the inference time while preserving high-fidelity, detailed generation. Additionally, we introduce an auxiliary edge generation task to not only enhance the preservation of fine details of the object boundaries, but reconcile the probabilistic nature of diffusion with the deterministic demands of segmentation. With these refined strategies in place, DiffDIS serves as a rapid object mask generation model, specifically optimized for generating detailed binary maps at high resolutions, while demonstrating impressive accuracy and swift processing. Experiments on the DIS5K dataset demonstrate the superiority of DiffDIS, achieving state-of-the-art results through a streamlined inference process. Our code will be made publicly available.