 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpider: A Unified Framework for Context-dependent Concept Understanding
May 02, 2024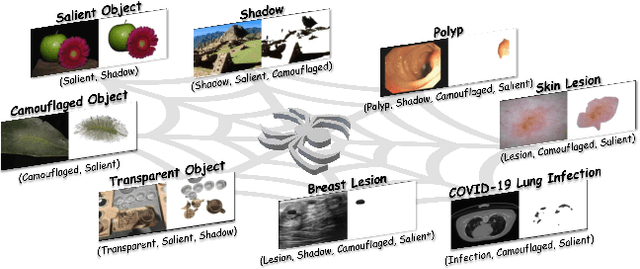
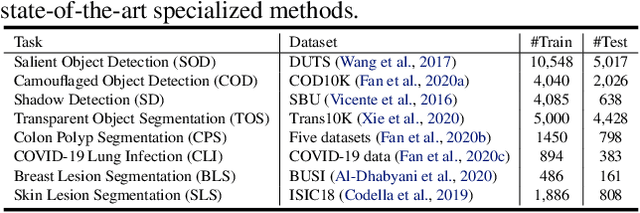
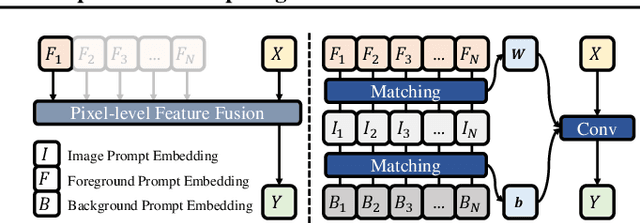
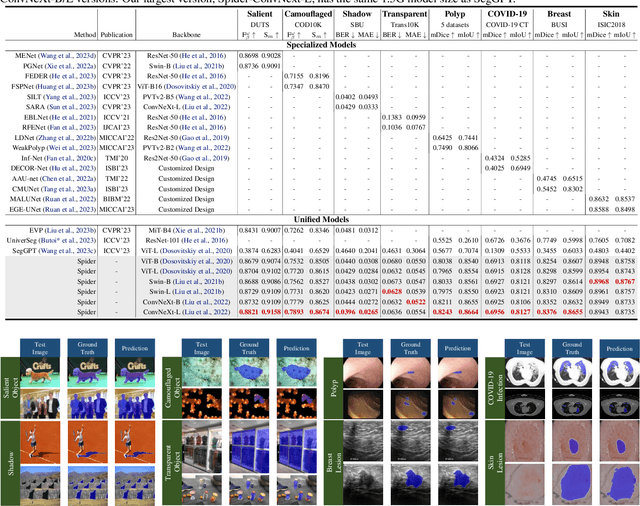
Different from the context-independent (CI) concepts such as human, car, and airplane, context-dependent (CD) concepts require higher visual understanding ability, such as camouflaged object and medical lesion. Despite the rapid advance of many CD understanding tasks in respective branches, the isolated evolution leads to their limited cross-domain generalisation and repetitive technique innovation. Since there is a strong coupling relationship between foreground and background context in CD tasks, existing methods require to train separate models in their focused domains. This restricts their real-world CD concept understanding towards artificial general intelligence (AGI). We propose a unified model with a single set of parameters, Spider, which only needs to be trained once. With the help of the proposed concept filter driven by the image-mask group prompt, Spider is able to understand and distinguish diverse strong context-dependent concepts to accurately capture the Prompter's intention. Without bells and whistles, Spider significantly outperforms the state-of-the-art specialized models in 8 different context-dependent segmentation tasks, including 4 natural scenes (salient, camouflaged, and transparent objects and shadow) and 4 medical lesions (COVID-19, polyp, breast, and skin lesion with color colonoscopy, CT, ultrasound, and dermoscopy modalities). Besides, Spider shows obvious advantages in continuous learning. It can easily complete the training of new tasks by fine-tuning parameters less than 1\% and bring a tolerable performance degradation of less than 5\% for all old tasks. The source code will be publicly available at \href{https://github.com/Xiaoqi-Zhao-DLUT/Spider-UniCDSeg}{Spider-UniCDSeg}.