 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Lightweight Low-Light Image Enhancement: From a YUV Color Space Perspective
Jan 24, 2026In the current era of mobile internet, Lightweight Low-Light Image Enhancement (L3IE) is critical for mobile devices, which faces a persistent trade-off between visual quality and model compactness. While recent methods employ disentangling strategies to simplify lightweight architectural design, such as Retinex theory and YUV color space transformations, their performance is fundamentally limited by overlooking channel-specific degradation patterns and cross-channel interactions. To address this gap, we perform a frequency-domain analysis that confirms the superiority of the YUV color space for L3IE. We identify a key insight: the Y channel primarily loses low-frequency content, while the UV channels are corrupted by high-frequency noise. Leveraging this finding, we propose a novel YUV-based paradigm that strategically restores channels using a Dual-Stream Global-Local Attention module for the Y channel, a Y-guided Local-Aware Frequency Attention module for the UV channels, and a Guided Interaction module for final feature fusion. Extensive experiments validate that our model establishes a new state-of-the-art on multiple benchmarks, delivering superior visual quality with a significantly lower parameter count.
Restore Text First, Enhance Image Later: Two-Stage Scene Text Image Super-Resolution with Glyph Structure Guidance
Oct 24, 2025
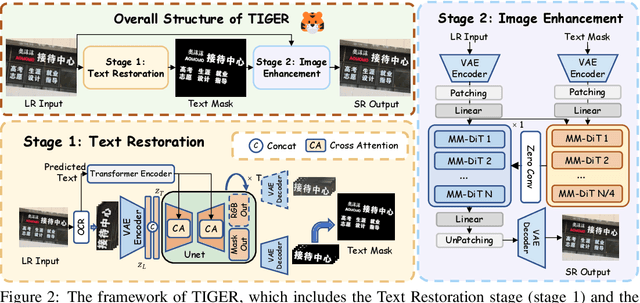
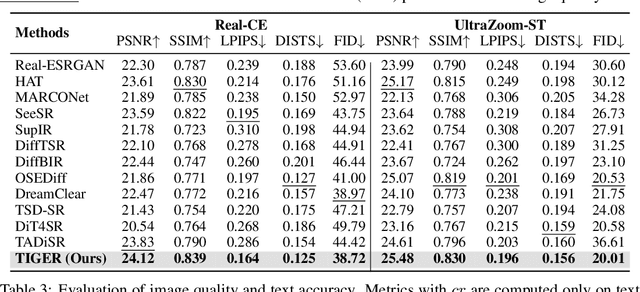
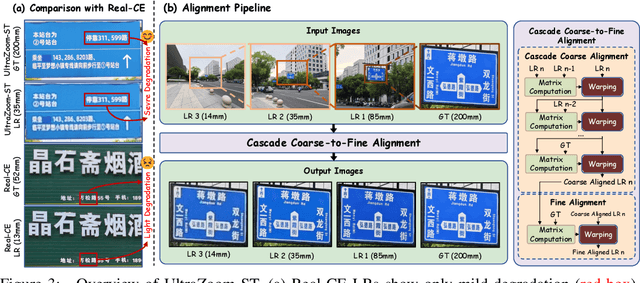
Current generative super-resolution methods show strong performance on natural images but distort text, creating a fundamental trade-off between image quality and textual readability. To address this, we introduce \textbf{TIGER} (\textbf{T}ext-\textbf{I}mage \textbf{G}uided sup\textbf{E}r-\textbf{R}esolution), a novel two-stage framework that breaks this trade-off through a \textit{"text-first, image-later"} paradigm. \textbf{TIGER} explicitly decouples glyph restoration from image enhancement: it first reconstructs precise text structures and then uses them to guide subsequent full-image super-resolution. This glyph-to-image guidance ensures both high fidelity and visual consistency. To support comprehensive training and evaluation, we also contribute the \textbf{UltraZoom-ST} (UltraZoom-Scene Text), the first scene text dataset with extreme zoom (\textbf{$\times$14.29}). Extensive experiments show that \textbf{TIGER} achieves \textbf{state-of-the-art} performance, enhancing readability while preserving overall image quality.
TinySR: Pruning Diffusion for Real-World Image Super-Resolution
Aug 24, 2025
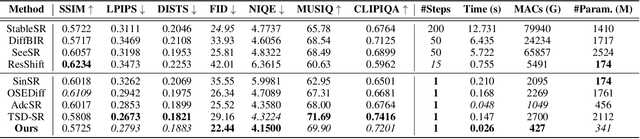
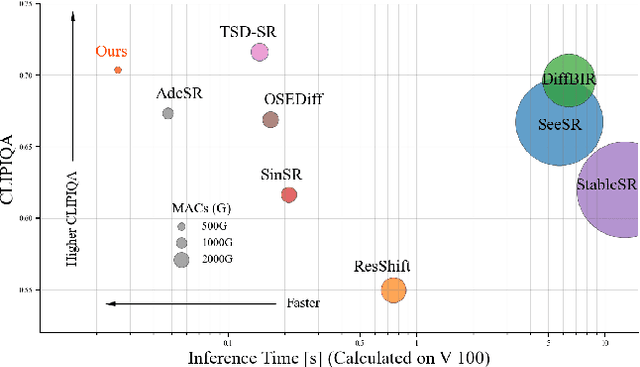
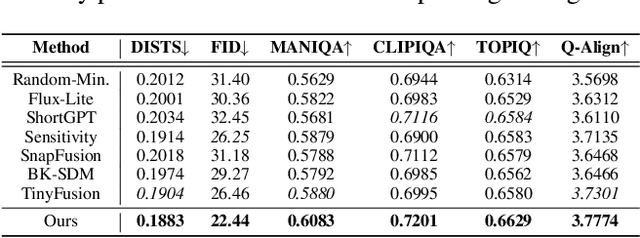
Real-world image super-resolution (Real-ISR) focuses on recovering high-quality images from low-resolution inputs that suffer from complex degradations like noise, blur, and compression. Recently, diffusion models (DMs) have shown great potential in this area by leveraging strong generative priors to restore fine details. However, their iterative denoising process incurs high computational overhead, posing challenges for real-time applications. Although one-step distillation methods, such as OSEDiff and TSD-SR, offer faster inference, they remain fundamentally constrained by their large, over-parameterized model architectures. In this work, we present TinySR, a compact yet effective diffusion model specifically designed for Real-ISR that achieves real-time performance while maintaining perceptual quality. We introduce a Dynamic Inter-block Activation and an Expansion-Corrosion Strategy to facilitate more effective decision-making in depth pruning. We achieve VAE compression through channel pruning, attention removal and lightweight SepConv. We eliminate time- and prompt-related modules and perform pre-caching techniques to further speed up the model. TinySR significantly reduces computational cost and model size, achieving up to 5.68x speedup and 83% parameter reduction compared to its teacher TSD-SR, while still providing high quality results.
BokehDiff: Neural Lens Blur with One-Step Diffusion
Jul 24, 2025We introduce BokehDiff, a novel lens blur rendering method that achieves physically accurate and visually appealing outcomes, with the help of generative diffusion prior. Previous methods are bounded by the accuracy of depth estimation, generating artifacts in depth discontinuities. Our method employs a physics-inspired self-attention module that aligns with the image formation process, incorporating depth-dependent circle of confusion constraint and self-occlusion effects. We adapt the diffusion model to the one-step inference scheme without introducing additional noise, and achieve results of high quality and fidelity. To address the lack of scalable paired data, we propose to synthesize photorealistic foregrounds with transparency with diffusion models, balancing authenticity and scene diversity.
HyperMotion: DiT-Based Pose-Guided Human Image Animation of Complex Motions
May 29, 2025Recent advances in diffusion models have significantly improved conditional video generation, particularly in the pose-guided human image animation task. Although existing methods are capable of generating high-fidelity and time-consistent animation sequences in regular motions and static scenes, there are still obvious limitations when facing complex human body motions (Hypermotion) that contain highly dynamic, non-standard motions, and the lack of a high-quality benchmark for evaluation of complex human motion animations. To address this challenge, we introduce the \textbf{Open-HyperMotionX Dataset} and \textbf{HyperMotionX Bench}, which provide high-quality human pose annotations and curated video clips for evaluating and improving pose-guided human image animation models under complex human motion conditions. Furthermore, we propose a simple yet powerful DiT-based video generation baseline and design spatial low-frequency enhanced RoPE, a novel module that selectively enhances low-frequency spatial feature modeling by introducing learnable frequency scaling. Our method significantly improves structural stability and appearance consistency in highly dynamic human motion sequences. Extensive experiments demonstrate the effectiveness of our dataset and proposed approach in advancing the generation quality of complex human motion image animations. Code and dataset will be made publicly available.
MagicTryOn: Harnessing Diffusion Transformer for Garment-Preserving Video Virtual Try-on
May 28, 2025Video Virtual Try-On (VVT) aims to simulate the natural appearance of garments across consecutive video frames, capturing their dynamic variations and interactions with human body motion. However, current VVT methods still face challenges in terms of spatiotemporal consistency and garment content preservation. First, they use diffusion models based on the U-Net, which are limited in their expressive capability and struggle to reconstruct complex details. Second, they adopt a separative modeling approach for spatial and temporal attention, which hinders the effective capture of structural relationships and dynamic consistency across frames. Third, their expression of garment details remains insufficient, affecting the realism and stability of the overall synthesized results, especially during human motion. To address the above challenges, we propose MagicTryOn, a video virtual try-on framework built upon the large-scale video diffusion Transformer. We replace the U-Net architecture with a diffusion Transformer and combine full self-attention to jointly model the spatiotemporal consistency of videos. We design a coarse-to-fine garment preservation strategy. The coarse strategy integrates garment tokens during the embedding stage, while the fine strategy incorporates multiple garment-based conditions, such as semantics, textures, and contour lines during the denoising stage. Moreover, we introduce a mask-aware loss to further optimize garment region fidelity. Extensive experiments on both image and video try-on datasets demonstrate that our method outperforms existing SOTA methods in comprehensive evaluations and generalizes to in-the-wild scenarios.
Photography Perspective Composition: Towards Aesthetic Perspective Recommendation
May 27, 2025Traditional photography composition approaches are dominated by 2D cropping-based methods. However, these methods fall short when scenes contain poorly arranged subjects. Professional photographers often employ perspective adjustment as a form of 3D recomposition, modifying the projected 2D relationships between subjects while maintaining their actual spatial positions to achieve better compositional balance. Inspired by this artistic practice, we propose photography perspective composition (PPC), extending beyond traditional cropping-based methods. However, implementing the PPC faces significant challenges: the scarcity of perspective transformation datasets and undefined assessment criteria for perspective quality. To address these challenges, we present three key contributions: (1) An automated framework for building PPC datasets through expert photographs. (2) A video generation approach that demonstrates the transformation process from suboptimal to optimal perspectives. (3) A perspective quality assessment (PQA) model constructed based on human performance. Our approach is concise and requires no additional prompt instructions or camera trajectories, helping and guiding ordinary users to enhance their composition skills.
Any-to-Bokeh: One-Step Video Bokeh via Multi-Plane Image Guided Diffusion
May 27, 2025Recent advances in diffusion based editing models have enabled realistic camera simulation and image-based bokeh, but video bokeh remains largely unexplored. Existing video editing models cannot explicitly control focus planes or adjust bokeh intensity, limiting their applicability for controllable optical effects. Moreover, naively extending image-based bokeh methods to video often results in temporal flickering and unsatisfactory edge blur transitions due to the lack of temporal modeling and generalization capability. To address these challenges, we propose a novel one-step video bokeh framework that converts arbitrary input videos into temporally coherent, depth-aware bokeh effects. Our method leverages a multi-plane image (MPI) representation constructed through a progressively widening depth sampling function, providing explicit geometric guidance for depth-dependent blur synthesis. By conditioning a single-step video diffusion model on MPI layers and utilizing the strong 3D priors from pre-trained models such as Stable Video Diffusion, our approach achieves realistic and consistent bokeh effects across diverse scenes. Additionally, we introduce a progressive training strategy to enhance temporal consistency, depth robustness, and detail preservation. Extensive experiments demonstrate that our method produces high-quality, controllable bokeh effects and achieves state-of-the-art performance on multiple evaluation benchmarks.
Enhancing Visual Grounding for GUI Agents via Self-Evolutionary Reinforcement Learning
May 18, 2025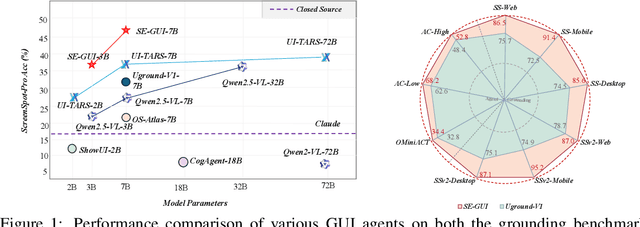
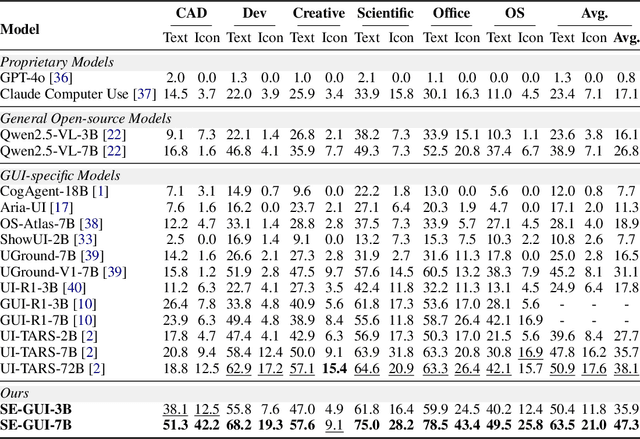
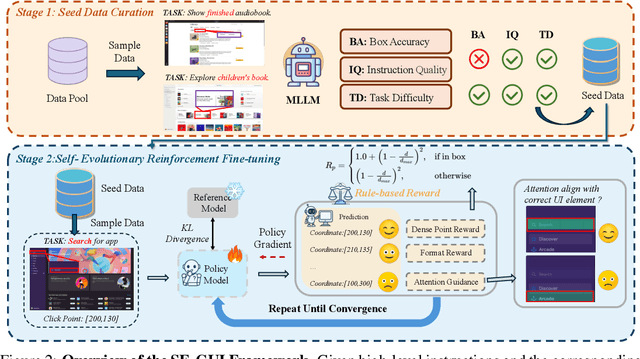
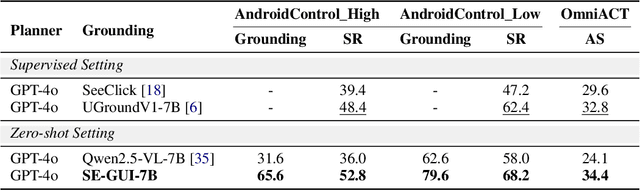
Graphical User Interface (GUI) agents have made substantial strides in understanding and executing user instructions across diverse platforms. Yet, grounding these instructions to precise interface elements remains challenging, especially in complex, high-resolution, professional environments. Traditional supervised finetuning (SFT) methods often require large volumes of diverse data and exhibit weak generalization. To overcome these limitations, we introduce a reinforcement learning (RL) based framework that incorporates three core strategies: (1) seed data curation to ensure high quality training samples, (2) a dense policy gradient that provides continuous feedback based on prediction accuracy, and (3) a self evolutionary reinforcement finetuning mechanism that iteratively refines the model using attention maps. With only 3k training samples, our 7B-parameter model achieves state-of-the-art results among similarly sized models on three grounding benchmarks. Notably, it attains 47.3\% accuracy on the ScreenSpot-Pro dataset, outperforming much larger models, such as UI-TARS-72B, by a margin of 24.2\%. These findings underscore the effectiveness of RL-based approaches in enhancing GUI agent performance, particularly in high-resolution, complex environments.
Advancing Comprehensive Aesthetic Insight with Multi-Scale Text-Guided Self-Supervised Learning
Dec 16, 2024



Image Aesthetic Assessment (IAA) is a vital and intricate task that entails analyzing and assessing an image's aesthetic values, and identifying its highlights and areas for improvement. Traditional methods of IAA often concentrate on a single aesthetic task and suffer from inadequate labeled datasets, thus impairing in-depth aesthetic comprehension. Despite efforts to overcome this challenge through the application of Multi-modal Large Language Models (MLLMs), such models remain underdeveloped for IAA purposes. To address this, we propose a comprehensive aesthetic MLLM capable of nuanced aesthetic insight. Central to our approach is an innovative multi-scale text-guided self-supervised learning technique. This technique features a multi-scale feature alignment module and capitalizes on a wealth of unlabeled data in a self-supervised manner to structurally and functionally enhance aesthetic ability. The empirical evidence indicates that accompanied with extensive instruct-tuning, our model sets new state-of-the-art benchmarks across multiple tasks, including aesthetic scoring, aesthetic commenting, and personalized image aesthetic assessment. Remarkably, it also demonstrates zero-shot learning capabilities in the emerging task of aesthetic suggesting. Furthermore, for personalized image aesthetic assessment, we harness the potential of in-context learning and showcase its inherent advantages.