 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Regularization Against Visual Representation Degradation in Multimodal Large Language Models
Mar 21, 2026While Multimodal Large Language Models (MLLMs) excel at vision-language tasks, the cost of their language-driven training on internal visual foundational competence remains unclear. In this paper, we conduct a detailed diagnostic analysis to unveil a pervasive issue: visual representation degradation in MLLMs. Specifically, we find that compared to the initial visual features, the visual representation in the middle layers of LLM exhibits both a degradation in global function and patch structure. We attribute this phenomenon to a visual sacrifice driven by the singular text-generation objective, where the model compromises its visual fidelity to optimize for answer generation. We argue that a robust MLLM requires both strong cross-modal reasoning and core visual competence, and propose Predictive Regularization (PRe) to force degraded intermediate features to predict initial visual features, thereby maintaining the inherent visual attributes of the MLLM's internal representations. Extensive experiments confirm that mitigating this visual degradation effectively boosts vision-language performance, underscoring the critical importance of fostering robust internal visual representations within MLLMs for comprehensive multimodal understanding.
Photography Perspective Composition: Towards Aesthetic Perspective Recommendation
May 27, 2025Traditional photography composition approaches are dominated by 2D cropping-based methods. However, these methods fall short when scenes contain poorly arranged subjects. Professional photographers often employ perspective adjustment as a form of 3D recomposition, modifying the projected 2D relationships between subjects while maintaining their actual spatial positions to achieve better compositional balance. Inspired by this artistic practice, we propose photography perspective composition (PPC), extending beyond traditional cropping-based methods. However, implementing the PPC faces significant challenges: the scarcity of perspective transformation datasets and undefined assessment criteria for perspective quality. To address these challenges, we present three key contributions: (1) An automated framework for building PPC datasets through expert photographs. (2) A video generation approach that demonstrates the transformation process from suboptimal to optimal perspectives. (3) A perspective quality assessment (PQA) model constructed based on human performance. Our approach is concise and requires no additional prompt instructions or camera trajectories, helping and guiding ordinary users to enhance their composition skills.
Enhancing Visual Grounding for GUI Agents via Self-Evolutionary Reinforcement Learning
May 18, 2025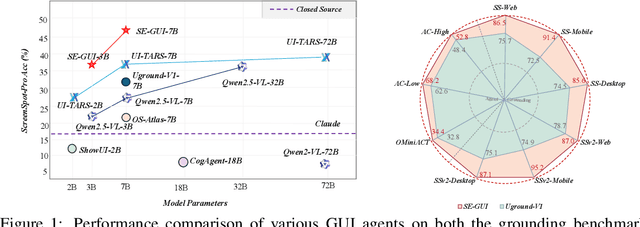
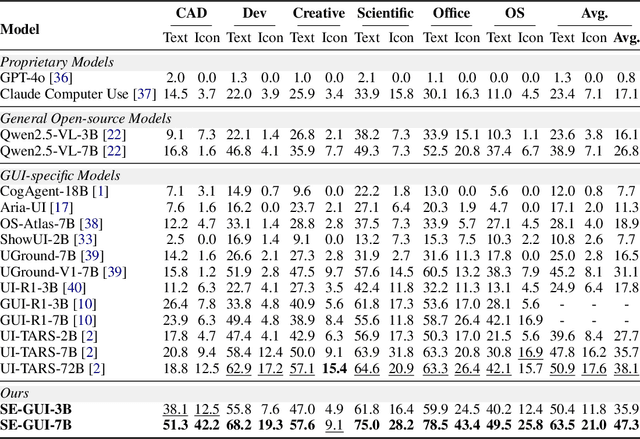
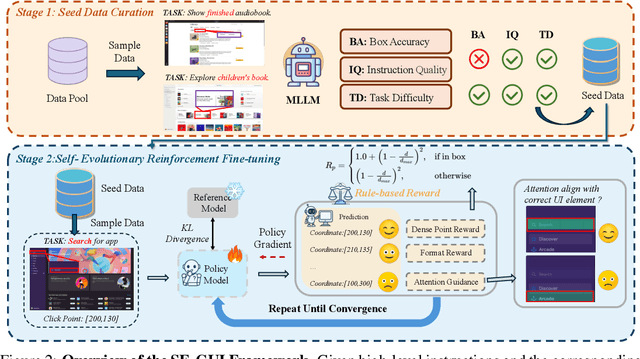
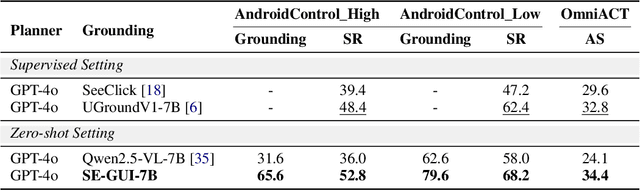
Graphical User Interface (GUI) agents have made substantial strides in understanding and executing user instructions across diverse platforms. Yet, grounding these instructions to precise interface elements remains challenging, especially in complex, high-resolution, professional environments. Traditional supervised finetuning (SFT) methods often require large volumes of diverse data and exhibit weak generalization. To overcome these limitations, we introduce a reinforcement learning (RL) based framework that incorporates three core strategies: (1) seed data curation to ensure high quality training samples, (2) a dense policy gradient that provides continuous feedback based on prediction accuracy, and (3) a self evolutionary reinforcement finetuning mechanism that iteratively refines the model using attention maps. With only 3k training samples, our 7B-parameter model achieves state-of-the-art results among similarly sized models on three grounding benchmarks. Notably, it attains 47.3\% accuracy on the ScreenSpot-Pro dataset, outperforming much larger models, such as UI-TARS-72B, by a margin of 24.2\%. These findings underscore the effectiveness of RL-based approaches in enhancing GUI agent performance, particularly in high-resolution, complex environments.
Strip R-CNN: Large Strip Convolution for Remote Sensing Object Detection
Jan 08, 2025While witnessed with rapid development, remote sensing object detection remains challenging for detecting high aspect ratio objects. This paper shows that large strip convolutions are good feature representation learners for remote sensing object detection and can detect objects of various aspect ratios well. Based on large strip convolutions, we build a new network architecture called Strip R-CNN, which is simple, efficient, and powerful. Unlike recent remote sensing object detectors that leverage large-kernel convolutions with square shapes, our Strip R-CNN takes advantage of sequential orthogonal large strip convolutions to capture spatial information. In addition, we enhance the localization capability of remote-sensing object detectors by decoupling the detection heads and equipping the localization head with strip convolutions to better localize the target objects. Extensive experiments on several benchmarks, e.g., DOTA, FAIR1M, HRSC2016, and DIOR, show that our Strip R-CNN can largely improve previous works. Notably, our 30M model achieves 82.75% mAP on DOTA-v1.0, setting a new state-of-the-art record.Code is available at https://github.com/YXB-NKU/Strip-R-CNN.
ChatAnything: Facetime Chat with LLM-Enhanced Personas
Nov 12, 2023



In this technical report, we target generating anthropomorphized personas for LLM-based characters in an online manner, including visual appearance, personality and tones, with only text descriptions. To achieve this, we first leverage the in-context learning capability of LLMs for personality generation by carefully designing a set of system prompts. We then propose two novel concepts: the mixture of voices (MoV) and the mixture of diffusers (MoD) for diverse voice and appearance generation. For MoV, we utilize the text-to-speech (TTS) algorithms with a variety of pre-defined tones and select the most matching one based on the user-provided text description automatically. For MoD, we combine the recent popular text-to-image generation techniques and talking head algorithms to streamline the process of generating talking objects. We termed the whole framework as ChatAnything. With it, users could be able to animate anything with any personas that are anthropomorphic using just a few text inputs. However, we have observed that the anthropomorphic objects produced by current generative models are often undetectable by pre-trained face landmark detectors, leading to failure of the face motion generation, even if these faces possess human-like appearances because those images are nearly seen during the training (e.g., OOD samples). To address this issue, we incorporate pixel-level guidance to infuse human face landmarks during the image generation phase. To benchmark these metrics, we have built an evaluation dataset. Based on it, we verify that the detection rate of the face landmark is significantly increased from 57.0% to 92.5% thus allowing automatic face animation based on generated speech content. The code and more results can be found at https://chatanything.github.io/.
YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection
Aug 10, 2023



We aim at providing the object detection community with an efficient and performant object detector, termed YOLO-MS. The core design is based on a series of investigations on how convolutions with different kernel sizes affect the detection performance of objects at different scales. The outcome is a new strategy that can strongly enhance multi-scale feature representations of real-time object detectors. To verify the effectiveness of our strategy, we build a network architecture, termed YOLO-MS. We train our YOLO-MS on the MS COCO dataset from scratch without relying on any other large-scale datasets, like ImageNet, or pre-trained weights. Without bells and whistles, our YOLO-MS outperforms the recent state-of-the-art real-time object detectors, including YOLO-v7 and RTMDet, when using a comparable number of parameters and FLOPs. Taking the XS version of YOLO-MS as an example, with only 4.5M learnable parameters and 8.7G FLOPs, it can achieve an AP score of 43%+ on MS COCO, which is about 2%+ higher than RTMDet with the same model size. Moreover, our work can also be used as a plug-and-play module for other YOLO models. Typically, our method significantly improves the AP of YOLOv8 from 37%+ to 40%+ with even fewer parameters and FLOPs. Code is available at https://github.com/FishAndWasabi/YOLO-MS.