 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Forcing: Dual-Mode Self-Evolution for Fast Autoregressive Audio-Video Character Generation
Apr 28, 2026In this work, we propose Mutual Forcing, a framework for fast autoregressive audio-video generation with long-horizon audio-video synchronization. Our approach addresses two key challenges: joint audio-video modeling and fast autoregressive generation. To ease joint audio-video optimization, we adopt a two-stage training strategy: we first train uni-modal generators and then couple them into a unified audio-video model for joint training on paired data. For streaming generation, we ask whether a native fast causal audio-video model can be trained directly, instead of following existing streaming distillation pipelines that typically train a bidirectional model first and then convert it into a causal generator through multiple distillation stages. Our answer is Mutual Forcing, which builds directly on native autoregressive model and integrates few-step and multi-step generation within a single weight-shared model, enabling self-distillation and improved training-inference consistency. The multi-step mode improves the few-step mode via self-distillation, while the few-step mode generates historical context during training to improve training-inference consistency; because the two modes share parameters, these two effects reinforce each other within a single model. Compared with prior approaches such as Self-Forcing, Mutual Forcing removes the need for an additional bidirectional teacher model, supports more flexible training sequence lengths, reduces training overhead, and allows the model to improve directly from real paired data rather than a fixed teacher. Experiments show that Mutual Forcing matches or surpasses strong baselines that require around 50 sampling steps while using only 4 to 8 steps, demonstrating substantial advantages in both efficiency and quality. The project page is available at https://mutualforcing.github.io.
The Constant Eye: Benchmarking and Bridging Appearance Robustness in Autonomous Driving
Feb 13, 2026Despite rapid progress, autonomous driving algorithms remain notoriously fragile under Out-of-Distribution (OOD) conditions. We identify a critical decoupling failure in current research: the lack of distinction between appearance-based shifts, such as weather and lighting, and structural scene changes. This leaves a fundamental question unanswered: Is the planner failing because of complex road geometry, or simply because it is raining? To resolve this, we establish navdream, a high-fidelity robustness benchmark leveraging generative pixel-aligned style transfer. By creating a visual stress test with negligible geometric deviation, we isolate the impact of appearance on driving performance. Our evaluation reveals that existing planning algorithms often show significant degradation under OOD appearance conditions, even when the underlying scene structure remains consistent. To bridge this gap, we propose a universal perception interface leveraging a frozen visual foundation model (DINOv3). By extracting appearance-invariant features as a stable interface for the planner, we achieve exceptional zero-shot generalization across diverse planning paradigms, including regression-based, diffusion-based, and scoring-based models. Our plug-and-play solution maintains consistent performance across extreme appearance shifts without requiring further fine-tuning. The benchmark and code will be made available.
COME: Adding Scene-Centric Forecasting Control to Occupancy World Model
Jun 16, 2025World models are critical for autonomous driving to simulate environmental dynamics and generate synthetic data. Existing methods struggle to disentangle ego-vehicle motion (perspective shifts) from scene evolvement (agent interactions), leading to suboptimal predictions. Instead, we propose to separate environmental changes from ego-motion by leveraging the scene-centric coordinate systems. In this paper, we introduce COME: a framework that integrates scene-centric forecasting Control into the Occupancy world ModEl. Specifically, COME first generates ego-irrelevant, spatially consistent future features through a scene-centric prediction branch, which are then converted into scene condition using a tailored ControlNet. These condition features are subsequently injected into the occupancy world model, enabling more accurate and controllable future occupancy predictions. Experimental results on the nuScenes-Occ3D dataset show that COME achieves consistent and significant improvements over state-of-the-art (SOTA) methods across diverse configurations, including different input sources (ground-truth, camera-based, fusion-based occupancy) and prediction horizons (3s and 8s). For example, under the same settings, COME achieves 26.3% better mIoU metric than DOME and 23.7% better mIoU metric than UniScene. These results highlight the efficacy of disentangled representation learning in enhancing spatio-temporal prediction fidelity for world models. Code and videos will be available at https://github.com/synsin0/COME.
HUGSIM: A Real-Time, Photo-Realistic and Closed-Loop Simulator for Autonomous Driving
Dec 02, 2024

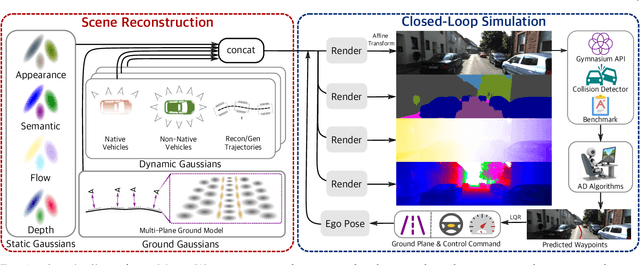
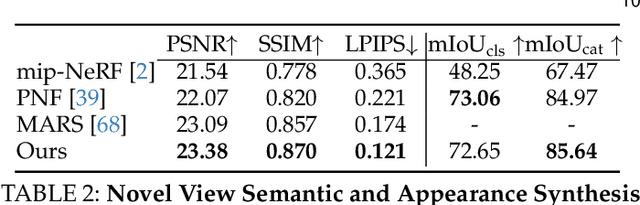
In the past few decades, autonomous driving algorithms have made significant progress in perception, planning, and control. However, evaluating individual components does not fully reflect the performance of entire systems, highlighting the need for more holistic assessment methods. This motivates the development of HUGSIM, a closed-loop, photo-realistic, and real-time simulator for evaluating autonomous driving algorithms. We achieve this by lifting captured 2D RGB images into the 3D space via 3D Gaussian Splatting, improving the rendering quality for closed-loop scenarios, and building the closed-loop environment. In terms of rendering, We tackle challenges of novel view synthesis in closed-loop scenarios, including viewpoint extrapolation and 360-degree vehicle rendering. Beyond novel view synthesis, HUGSIM further enables the full closed simulation loop, dynamically updating the ego and actor states and observations based on control commands. Moreover, HUGSIM offers a comprehensive benchmark across more than 70 sequences from KITTI-360, Waymo, nuScenes, and PandaSet, along with over 400 varying scenarios, providing a fair and realistic evaluation platform for existing autonomous driving algorithms. HUGSIM not only serves as an intuitive evaluation benchmark but also unlocks the potential for fine-tuning autonomous driving algorithms in a photorealistic closed-loop setting.
Vision Mamba Distillation for Low-resolution Fine-grained Image Classification
Nov 27, 2024



Low-resolution fine-grained image classification has recently made significant progress, largely thanks to the super-resolution techniques and knowledge distillation methods. However, these approaches lead to an exponential increase in the number of parameters and computational complexity of models. In order to solve this problem, in this letter, we propose a Vision Mamba Distillation (ViMD) approach to enhance the effectiveness and efficiency of low-resolution fine-grained image classification. Concretely, a lightweight super-resolution vision Mamba classification network (SRVM-Net) is proposed to improve its capability for extracting visual features by redesigning the classification sub-network with Mamba modeling. Moreover, we design a novel multi-level Mamba knowledge distillation loss boosting the performance, which can transfer prior knowledge obtained from a High-resolution Vision Mamba classification Network (HRVM-Net) as a teacher into the proposed SRVM-Net as a student. Extensive experiments on seven public fine-grained classification datasets related to benchmarks confirm our ViMD achieves a new state-of-the-art performance. While having higher accuracy, ViMD outperforms similar methods with fewer parameters and FLOPs, which is more suitable for embedded device applications. Code is available at https://github.com/boa2004plaust/ViMD.
Paying more attention to local contrast: improving infrared small target detection performance via prior knowledge
Nov 20, 2024The data-driven method for infrared small target detection (IRSTD) has achieved promising results. However, due to the small scale of infrared small target datasets and the limited number of pixels occupied by the targets themselves, it is a challenging task for deep learning methods to directly learn from these samples. Utilizing human expert knowledge to assist deep learning methods in better learning is worthy of exploration. To effectively guide the model to focus on targets' spatial features, this paper proposes the Local Contrast Attention Enhanced infrared small target detection Network (LCAE-Net), combining prior knowledge with data-driven deep learning methods. LCAE-Net is a U-shaped neural network model which consists of two developed modules: a Local Contrast Enhancement (LCE) module and a Channel Attention Enhancement (CAE) module. The LCE module takes advantages of prior knowledge, leveraging handcrafted convolution operator to acquire Local Contrast Attention (LCA), which could realize background suppression while enhance the potential target region, thus guiding the neural network to pay more attention to potential infrared small targets' location information. To effectively utilize the response information throughout downsampling progresses, the CAE module is proposed to achieve the information fusion among feature maps' different channels. Experimental results indicate that our LCAE-Net outperforms existing state-of-the-art methods on the three public datasets NUDT-SIRST, NUAA-SIRST, and IRSTD-1K, and its detection speed could reach up to 70 fps. Meanwhile, our model has a parameter count and Floating-Point Operations (FLOPs) of 1.945M and 4.862G respectively, which is suitable for deployment on edge devices.
Guided Self-attention: Find the Generalized Necessarily Distinct Vectors for Grain Size Grading
Oct 08, 2024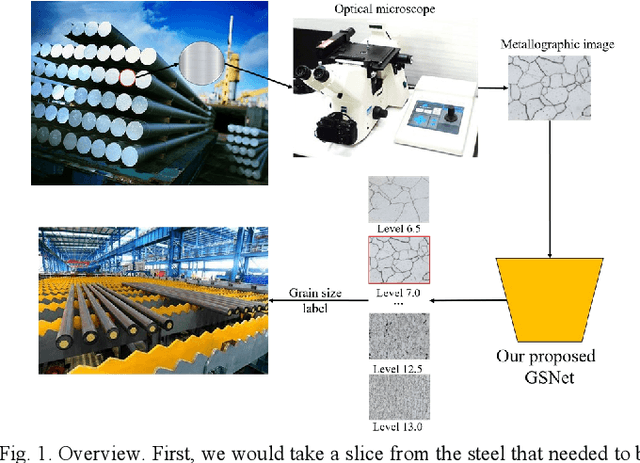

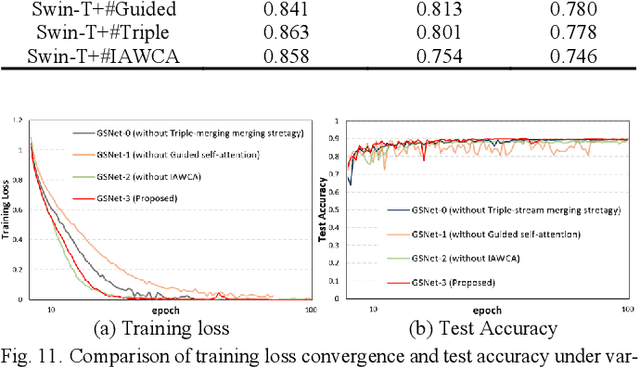

With the development of steel materials, metallographic analysis has become increasingly important. Unfortunately, grain size analysis is a manual process that requires experts to evaluate metallographic photographs, which is unreliable and time-consuming. To resolve this problem, we propose a novel classifi-cation method based on deep learning, namely GSNets, a family of hybrid models which can effectively introduce guided self-attention for classifying grain size. Concretely, we build our models from three insights:(1) Introducing our novel guided self-attention module can assist the model in finding the generalized necessarily distinct vectors capable of retaining intricate rela-tional connections and rich local feature information; (2) By improving the pixel-wise linear independence of the feature map, the highly condensed semantic representation will be captured by the model; (3) Our novel triple-stream merging module can significantly improve the generalization capability and efficiency of the model. Experiments show that our GSNet yields a classifi-cation accuracy of 90.1%, surpassing the state-of-the-art Swin Transformer V2 by 1.9% on the steel grain size dataset, which comprises 3,599 images with 14 grain size levels. Furthermore, we intuitively believe our approach is applicable to broader ap-plications like object detection and semantic segmentation.
OPUS: Occupancy Prediction Using a Sparse Set
Sep 14, 2024
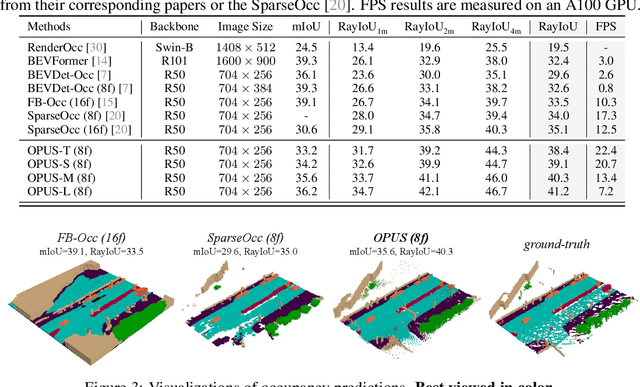
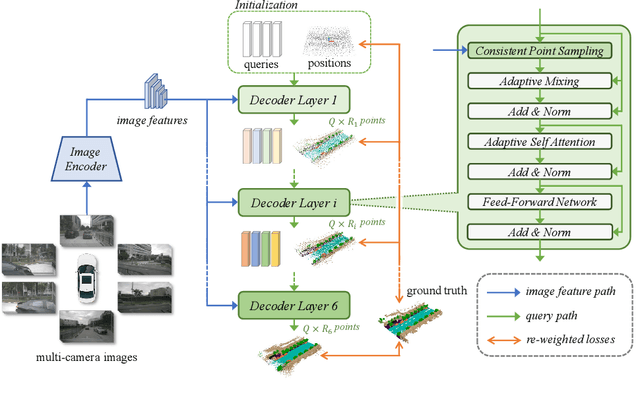
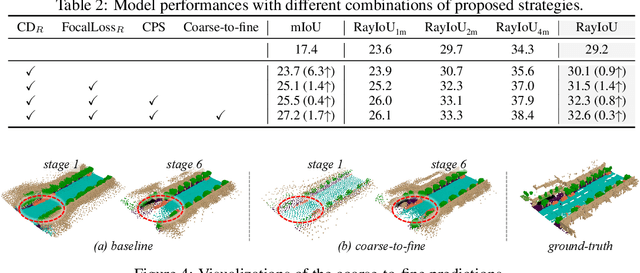
Occupancy prediction, aiming at predicting the occupancy status within voxelized 3D environment, is quickly gaining momentum within the autonomous driving community. Mainstream occupancy prediction works first discretize the 3D environment into voxels, then perform classification on such dense grids. However, inspection on sample data reveals that the vast majority of voxels is unoccupied. Performing classification on these empty voxels demands suboptimal computation resource allocation, and reducing such empty voxels necessitates complex algorithm designs. To this end, we present a novel perspective on the occupancy prediction task: formulating it as a streamlined set prediction paradigm without the need for explicit space modeling or complex sparsification procedures. Our proposed framework, called OPUS, utilizes a transformer encoder-decoder architecture to simultaneously predict occupied locations and classes using a set of learnable queries. Firstly, we employ the Chamfer distance loss to scale the set-to-set comparison problem to unprecedented magnitudes, making training such model end-to-end a reality. Subsequently, semantic classes are adaptively assigned using nearest neighbor search based on the learned locations. In addition, OPUS incorporates a suite of non-trivial strategies to enhance model performance, including coarse-to-fine learning, consistent point sampling, and adaptive re-weighting, etc. Finally, compared with current state-of-the-art methods, our lightest model achieves superior RayIoU on the Occ3D-nuScenes dataset at near 2x FPS, while our heaviest model surpasses previous best results by 6.1 RayIoU.
Towards Stable 3D Object Detection
Jul 05, 2024



In autonomous driving, the temporal stability of 3D object detection greatly impacts the driving safety. However, the detection stability cannot be accessed by existing metrics such as mAP and MOTA, and consequently is less explored by the community. To bridge this gap, this work proposes Stability Index (SI), a new metric that can comprehensively evaluate the stability of 3D detectors in terms of confidence, box localization, extent, and heading. By benchmarking state-of-the-art object detectors on the Waymo Open Dataset, SI reveals interesting properties of object stability that have not been previously discovered by other metrics. To help models improve their stability, we further introduce a general and effective training strategy, called Prediction Consistency Learning (PCL). PCL essentially encourages the prediction consistency of the same objects under different timestamps and augmentations, leading to enhanced detection stability. Furthermore, we examine the effectiveness of PCL with the widely-used CenterPoint, and achieve a remarkable SI of 86.00 for vehicle class, surpassing the baseline by 5.48. We hope our work could serve as a reliable baseline and draw the community's attention to this crucial issue in 3D object detection. Codes will be made publicly available.
HAAP: Vision-context Hierarchical Attention Autoregressive with Adaptive Permutation for Scene Text Recognition
May 15, 2024Internal Language Model (LM)-based methods use permutation language modeling (PLM) to solve the error correction caused by conditional independence in external LM-based methods. However, random permutations of human interference cause fit oscillations in the model training, and Iterative Refinement (IR) operation to improve multimodal information decoupling also introduces additional overhead. To address these issues, this paper proposes the Hierarchical Attention autoregressive Model with Adaptive Permutation (HAAP) to enhance the location-context-image interaction capability, improving autoregressive generalization with internal LM. First, we propose Implicit Permutation Neurons (IPN) to generate adaptive attention masks to dynamically exploit token dependencies. The adaptive masks increase the diversity of training data and prevent model dependency on a specific order. It reduces the training overhead of PLM while avoiding training fit oscillations. Second, we develop Cross-modal Hierarchical Attention mechanism (CHA) to couple context and image features. This processing establishes rich positional semantic dependencies between context and image while avoiding IR. Extensive experimental results show the proposed HAAP achieves state-of-the-art (SOTA) performance in terms of accuracy, complexity, and latency on several datasets.