 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Drug Delivery in Smart Pharmacies: A Novel Framework of Multi-Stage Grasping Network Combined with Adaptive Robotics Mechanism
Oct 01, 2024



Robots-based smart pharmacies are essential for modern healthcare systems, enabling efficient drug delivery. However, a critical challenge exists in the robotic handling of drugs with varying shapes and overlapping positions, which previous studies have not adequately addressed. To enhance the robotic arm's ability to grasp chaotic, overlapping, and variously shaped drugs, this paper proposed a novel framework combining a multi-stage grasping network with an adaptive robotics mechanism. The framework first preprocessed images using an improved Super-Resolution Convolutional Neural Network (SRCNN) algorithm, and then employed the proposed YOLOv5+E-A-SPPFCSPC+BIFPNC (YOLO-EASB) instance segmentation algorithm for precise drug segmentation. The most suitable drugs for grasping can be determined by assessing the completeness of the segmentation masks. Then, these segmented drugs were processed by our improved Adaptive Feature Fusion and Grasp-Aware Network (IAFFGA-Net) with the optimized loss function, which ensures accurate picking actions even in complex environments. To control the robot grasping, a time-optimal robotic arm trajectory planning algorithm that combines an improved ant colony algorithm with 3-5-3 interpolation was developed, further improving efficiency while ensuring smooth trajectories. Finally, this system was implemented and validated within an adaptive collaborative robot setup, which dynamically adjusts to different production environments and task requirements. Experimental results demonstrate the superiority of our multi-stage grasping network in optimizing smart pharmacy operations, while also showcasing its remarkable adaptability and effectiveness in practical applications.
HAAP: Vision-context Hierarchical Attention Autoregressive with Adaptive Permutation for Scene Text Recognition
May 15, 2024Internal Language Model (LM)-based methods use permutation language modeling (PLM) to solve the error correction caused by conditional independence in external LM-based methods. However, random permutations of human interference cause fit oscillations in the model training, and Iterative Refinement (IR) operation to improve multimodal information decoupling also introduces additional overhead. To address these issues, this paper proposes the Hierarchical Attention autoregressive Model with Adaptive Permutation (HAAP) to enhance the location-context-image interaction capability, improving autoregressive generalization with internal LM. First, we propose Implicit Permutation Neurons (IPN) to generate adaptive attention masks to dynamically exploit token dependencies. The adaptive masks increase the diversity of training data and prevent model dependency on a specific order. It reduces the training overhead of PLM while avoiding training fit oscillations. Second, we develop Cross-modal Hierarchical Attention mechanism (CHA) to couple context and image features. This processing establishes rich positional semantic dependencies between context and image while avoiding IR. Extensive experimental results show the proposed HAAP achieves state-of-the-art (SOTA) performance in terms of accuracy, complexity, and latency on several datasets.
IFViT: Interpretable Fixed-Length Representation for Fingerprint Matching via Vision Transformer
Apr 12, 2024
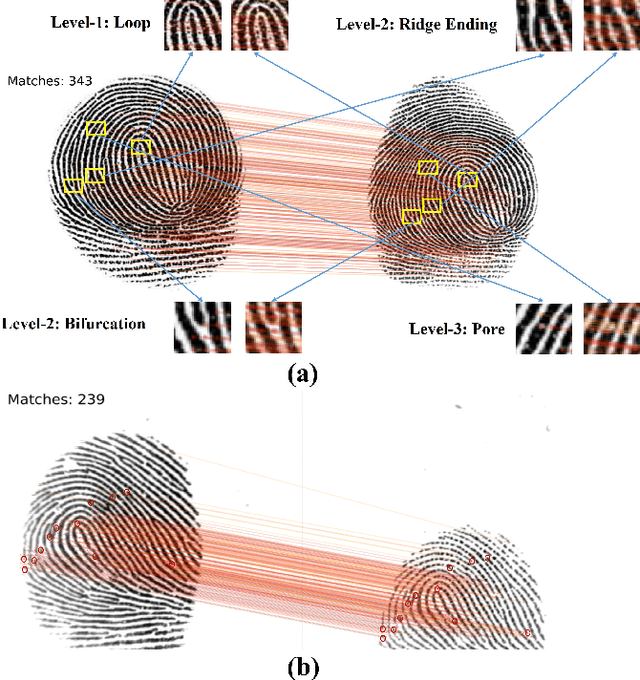
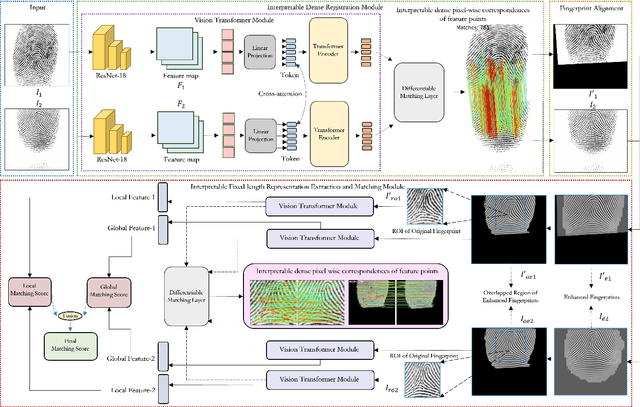

Determining dense feature points on fingerprints used in constructing deep fixed-length representations for accurate matching, particularly at the pixel level, is of significant interest. To explore the interpretability of fingerprint matching, we propose a multi-stage interpretable fingerprint matching network, namely Interpretable Fixed-length Representation for Fingerprint Matching via Vision Transformer (IFViT), which consists of two primary modules. The first module, an interpretable dense registration module, establishes a Vision Transformer (ViT)-based Siamese Network to capture long-range dependencies and the global context in fingerprint pairs. It provides interpretable dense pixel-wise correspondences of feature points for fingerprint alignment and enhances the interpretability in the subsequent matching stage. The second module takes into account both local and global representations of the aligned fingerprint pair to achieve an interpretable fixed-length representation extraction and matching. It employs the ViTs trained in the first module with the additional fully connected layer and retrains them to simultaneously produce the discriminative fixed-length representation and interpretable dense pixel-wise correspondences of feature points. Extensive experimental results on diverse publicly available fingerprint databases demonstrate that the proposed framework not only exhibits superior performance on dense registration and matching but also significantly promotes the interpretability in deep fixed-length representations-based fingerprint matching.