 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Consistency: Preserving Temporal Structure in Zero-Shot Video Editing
Jun 07, 2026Existing zero-shot video editing methods rely on pre-trained diffusion models, successfully achieving spatial control and basic temporal consistency but fundamentally fail to preserve the video's original temporal structure.This distinction is critical: temporal consistency ensures visual smoothness, but temporal structure dictates the video's high-level narrative, rhythm, and semantic flow. Without this preservation, the edited output, especially for long videos with complex semantic variations, becomes narratively incoherent and semantically ambiguous. To address this limitation, we introduce a novel zero-shot editing approach that, for the first time, explicitly focuses on preserving the source video's temporal structure. We achieve this by adaptively partitioning the video into semantically distinct clips based on feature similarity and selecting a representative anchor frame for each clip. To enhance both intra-clip fidelity and computational efficiency, we design a clip-adaptive token merging strategy which leverages the anchor's semantic dominance to stabilize the editing. Furthermore, we employ an alternating combination strategy that ensures seamless inter-clip transitions while maintaining semantic distinction. Extensive experiments demonstrate that our method achieves state-of-the-art results, successfully balancing the preservation of original temporal structure with computational efficiency, and setting a new benchmark for zero-shot video editing fidelity.
EventFace: Event-Based Face Recognition via Structure-Driven Spatiotemporal Modeling
Apr 08, 2026Event cameras offer a promising sensing modality for face recognition due to their inherent advantages in illumination robustness and privacy-friendliness. However, because event streams lack the stable photometric appearance relied upon by conventional RGB-based face recognition systems, we argue that event-based face recognition should model structure-driven spatiotemporal identity representations shaped by rigid facial motion and individual facial geometry. Since dedicated datasets for event-based face recognition remain lacking, we construct EFace, a small-scale event-based face dataset captured under rigid facial motion. To learn effectively from this limited event data, we further propose EventFace, a framework for event-based face recognition that integrates spatial structure and temporal dynamics for identity modeling. Specifically, we employ Low-Rank Adaptation (LoRA) to transfer structural facial priors from pretrained RGB face models to the event domain, thereby establishing a reliable spatial basis for identity modeling. Building on this foundation, we further introduce a Motion Prompt Encoder (MPE) to explicitly encode temporal features and a Spatiotemporal Modulator (STM) to fuse them with spatial features, thereby enhancing the representation of identity-relevant event patterns. Extensive experiments demonstrate that EventFace achieves the best performance among the evaluated baselines, with a Rank-1 identification rate of 94.19% and an equal error rate (EER) of 5.35%. Results further indicate that EventFace exhibits stronger robustness under degraded illumination than the competing methods. In addition, the learned representations exhibit reduced template reconstructability.
Structure and Progress Aware Diffusion for Medical Image Segmentation
Mar 09, 2026Medical image segmentation is crucial for computer-aided diagnosis, which necessitates understanding both coarse morphological and semantic structures, as well as carving fine boundaries. The morphological and semantic structures in medical images are beneficial and stable clues for target understanding. While the fine boundaries of medical targets (like tumors and lesions) are usually ambiguous and noisy since lesion overlap, annotation uncertainty, and so on, making it not reliable to serve as early supervision. However, existing methods simultaneously learn coarse structures and fine boundaries throughout the training process. In this paper, we propose a structure and progress-aware diffusion (SPAD) for medical image segmentation, which consists of a semantic-concentrated diffusion (ScD) and a boundary-centralized diffusion (BcD) modulated by a progress-aware scheduler (PaS). Specifically, the semantic-concentrated diffusion introduces anchor-preserved target perturbation, which perturbs pixels within a medical target but preserves unaltered areas as semantic anchors, encouraging the model to infer noisy target areas from the surrounding semantic context. The boundary-centralized diffusion introduces progress-aware boundary noise, which blurs unreliable and ambiguous boundaries, thus compelling the model to focus on coarse but stable anatomical morphology and global semantics. Furthermore, the progress-aware scheduler gradually modulates noise intensity of the ScD and BcD forming a coarse-to-fine diffusion paradigm, which encourage focusing on coarse morphological and semantic structures during early target understanding stages and gradually shifting to fine target boundaries during later contour adjusting stages.
UltraGS: Gaussian Splatting for Ultrasound Novel View Synthesis
Nov 11, 2025Ultrasound imaging is a cornerstone of non-invasive clinical diagnostics, yet its limited field of view complicates novel view synthesis. We propose \textbf{UltraGS}, a Gaussian Splatting framework optimized for ultrasound imaging. First, we introduce a depth-aware Gaussian splatting strategy, where each Gaussian is assigned a learnable field of view, enabling accurate depth prediction and precise structural representation. Second, we design SH-DARS, a lightweight rendering function combining low-order spherical harmonics with ultrasound-specific wave physics, including depth attenuation, reflection, and scattering, to model tissue intensity accurately. Third, we contribute the Clinical Ultrasound Examination Dataset, a benchmark capturing diverse anatomical scans under real-world clinical protocols. Extensive experiments on three datasets demonstrate UltraGS's superiority, achieving state-of-the-art results in PSNR (up to 29.55), SSIM (up to 0.89), and MSE (as low as 0.002) while enabling real-time synthesis at 64.69 fps. The code and dataset are open-sourced at: https://github.com/Bean-Young/UltraGS.
Auto-US: An Ultrasound Video Diagnosis Agent Using Video Classification Framework and LLMs
Nov 11, 2025AI-assisted ultrasound video diagnosis presents new opportunities to enhance the efficiency and accuracy of medical imaging analysis. However, existing research remains limited in terms of dataset diversity, diagnostic performance, and clinical applicability. In this study, we propose \textbf{Auto-US}, an intelligent diagnosis agent that integrates ultrasound video data with clinical diagnostic text. To support this, we constructed \textbf{CUV Dataset} of 495 ultrasound videos spanning five categories and three organs, aggregated from multiple open-access sources. We developed \textbf{CTU-Net}, which achieves state-of-the-art performance in ultrasound video classification, reaching an accuracy of 86.73\% Furthermore, by incorporating large language models, Auto-US is capable of generating clinically meaningful diagnostic suggestions. The final diagnostic scores for each case exceeded 3 out of 5 and were validated by professional clinicians. These results demonstrate the effectiveness and clinical potential of Auto-US in real-world ultrasound applications. Code and data are available at: https://github.com/Bean-Young/Auto-US.
Wormhole Dynamics in Deep Neural Networks
Aug 20, 2025



This work investigates the generalization behavior of deep neural networks (DNNs), focusing on the phenomenon of "fooling examples," where DNNs confidently classify inputs that appear random or unstructured to humans. To explore this phenomenon, we introduce an analytical framework based on maximum likelihood estimation, without adhering to conventional numerical approaches that rely on gradient-based optimization and explicit labels. Our analysis reveals that DNNs operating in an overparameterized regime exhibit a collapse in the output feature space. While this collapse improves network generalization, adding more layers eventually leads to a state of degeneracy, where the model learns trivial solutions by mapping distinct inputs to the same output, resulting in zero loss. Further investigation demonstrates that this degeneracy can be bypassed using our newly derived "wormhole" solution. The wormhole solution, when applied to arbitrary fooling examples, reconciles meaningful labels with random ones and provides a novel perspective on shortcut learning. These findings offer deeper insights into DNN generalization and highlight directions for future research on learning dynamics in unsupervised settings to bridge the gap between theory and practice.
Explicit and Implicit Representations in AI-based 3D Reconstruction for Radiology: A systematic literature review
Apr 15, 2025



The demand for high-quality medical imaging in clinical practice and assisted diagnosis has made 3D reconstruction in radiological imaging a key research focus. Artificial intelligence (AI) has emerged as a promising approach to enhancing reconstruction accuracy while reducing acquisition and processing time, thereby minimizing patient radiation exposure and discomfort and ultimately benefiting clinical diagnosis. This review explores state-of-the-art AI-based 3D reconstruction algorithms in radiological imaging, categorizing them into explicit and implicit approaches based on their underlying principles. Explicit methods include point-based, volume-based, and Gaussian representations, while implicit methods encompass implicit prior embedding and neural radiance fields. Additionally, we examine commonly used evaluation metrics and benchmark datasets. Finally, we discuss the current state of development, key challenges, and future research directions in this evolving field. Our project available on: https://github.com/Bean-Young/AI4Med.
Test-Time Domain Generalization via Universe Learning: A Multi-Graph Matching Approach for Medical Image Segmentation
Mar 17, 2025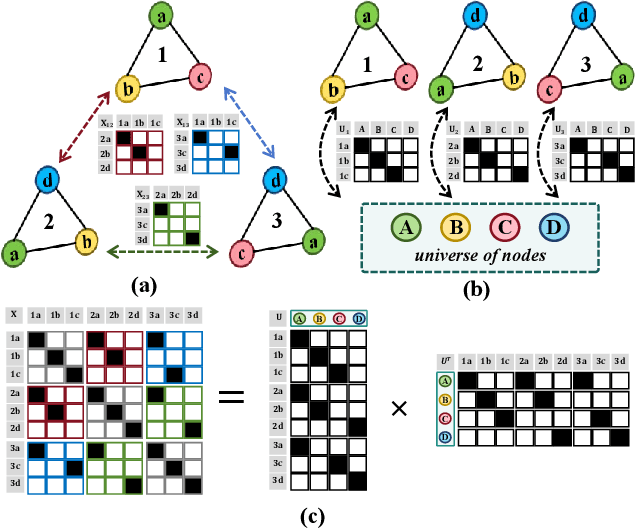

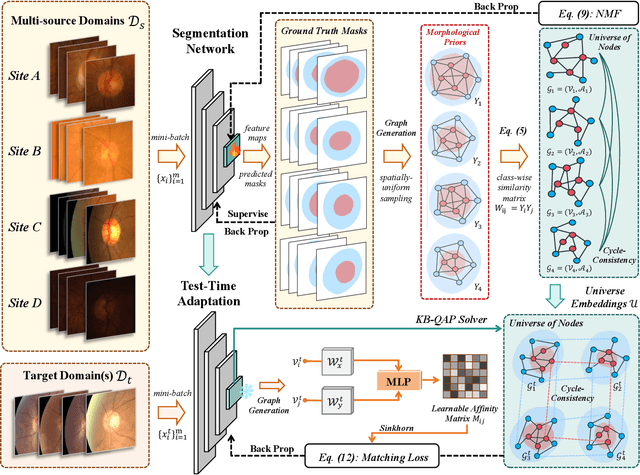

Despite domain generalization (DG) has significantly addressed the performance degradation of pre-trained models caused by domain shifts, it often falls short in real-world deployment. Test-time adaptation (TTA), which adjusts a learned model using unlabeled test data, presents a promising solution. However, most existing TTA methods struggle to deliver strong performance in medical image segmentation, primarily because they overlook the crucial prior knowledge inherent to medical images. To address this challenge, we incorporate morphological information and propose a framework based on multi-graph matching. Specifically, we introduce learnable universe embeddings that integrate morphological priors during multi-source training, along with novel unsupervised test-time paradigms for domain adaptation. This approach guarantees cycle-consistency in multi-matching while enabling the model to more effectively capture the invariant priors of unseen data, significantly mitigating the effects of domain shifts. Extensive experiments demonstrate that our method outperforms other state-of-the-art approaches on two medical image segmentation benchmarks for both multi-source and single-source domain generalization tasks. The source code is available at https://github.com/Yore0/TTDG-MGM.
Compose Your Aesthetics: Empowering Text-to-Image Models with the Principles of Art
Mar 15, 2025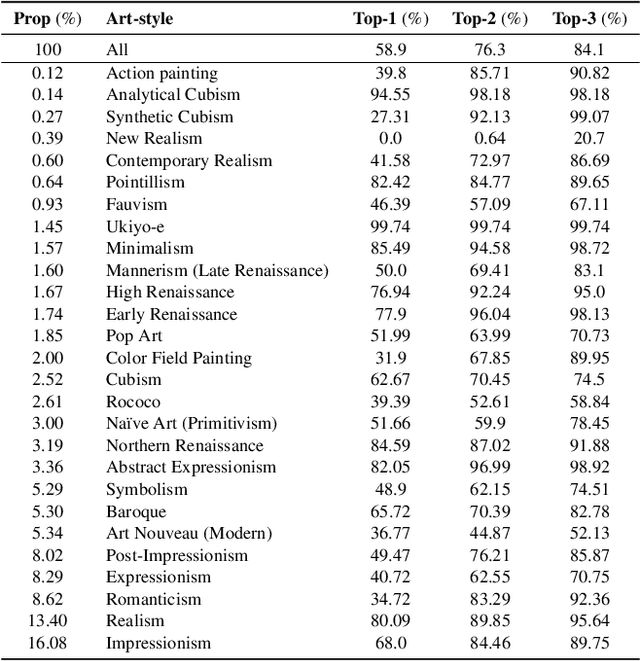

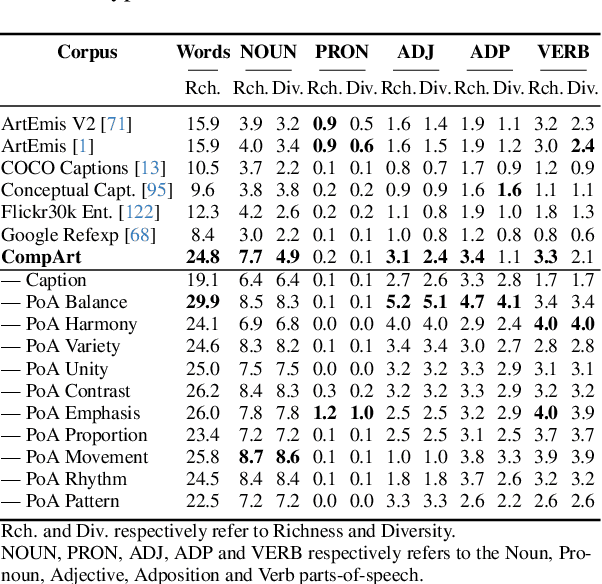
Text-to-Image (T2I) diffusion models (DM) have garnered widespread adoption due to their capability in generating high-fidelity outputs and accessibility to anyone able to put imagination into words. However, DMs are often predisposed to generate unappealing outputs, much like the random images on the internet they were trained on. Existing approaches to address this are founded on the implicit premise that visual aesthetics is universal, which is limiting. Aesthetics in the T2I context should be about personalization and we propose the novel task of aesthetics alignment which seeks to align user-specified aesthetics with the T2I generation output. Inspired by how artworks provide an invaluable perspective to approach aesthetics, we codify visual aesthetics using the compositional framework artists employ, known as the Principles of Art (PoA). To facilitate this study, we introduce CompArt, a large-scale compositional art dataset building on top of WikiArt with PoA analysis annotated by a capable Multimodal LLM. Leveraging the expressive power of LLMs and training a lightweight and transferrable adapter, we demonstrate that T2I DMs can effectively offer 10 compositional controls through user-specified PoA conditions. Additionally, we design an appropriate evaluation framework to assess the efficacy of our approach.
A Multi-task Adversarial Attack Against Face Authentication
Aug 15, 2024Deep-learning-based identity management systems, such as face authentication systems, are vulnerable to adversarial attacks. However, existing attacks are typically designed for single-task purposes, which means they are tailored to exploit vulnerabilities unique to the individual target rather than being adaptable for multiple users or systems. This limitation makes them unsuitable for certain attack scenarios, such as morphing, universal, transferable, and counter attacks. In this paper, we propose a multi-task adversarial attack algorithm called MTADV that are adaptable for multiple users or systems. By interpreting these scenarios as multi-task attacks, MTADV is applicable to both single- and multi-task attacks, and feasible in the white- and gray-box settings. Furthermore, MTADV is effective against various face datasets, including LFW, CelebA, and CelebA-HQ, and can work with different deep learning models, such as FaceNet, InsightFace, and CurricularFace. Importantly, MTADV retains its feasibility as a single-task attack targeting a single user/system. To the best of our knowledge, MTADV is the first adversarial attack method that can target all of the aforementioned scenarios in one algorithm.