 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking Reasoning Processes: A Process-aware Benchmark for Evaluating Structural Mathematical Reasoning in LLMs
Jan 31, 2026Recent large language models (LLMs) achieve near-saturation accuracy on many established mathematical reasoning benchmarks, raising concerns about their ability to diagnose genuine reasoning competence. This saturation largely stems from the dominance of template-based computation and shallow arithmetic decomposition in existing datasets, which underrepresent reasoning skills such as multi-constraint coordination, constructive logical synthesis, and spatial inference. To address this gap, we introduce ReasoningMath-Plus, a benchmark of 150 carefully curated problems explicitly designed to evaluate structural reasoning. Each problem emphasizes reasoning under interacting constraints, constructive solution formation, or non-trivial structural insight, and is annotated with a minimal reasoning skeleton to support fine-grained process-level evaluation. Alongside the dataset, we introduce HCRS (Hazard-aware Chain-based Rule Score), a deterministic step-level scoring function, and train a Process Reward Model (PRM) on the annotated reasoning traces. Empirically, while leading models attain relatively high final-answer accuracy (up to 5.8/10), HCRS-based holistic evaluation yields substantially lower scores (average 4.36/10, best 5.14/10), showing that answer-only metrics can overestimate reasoning robustness.
SyncTwin: Fast Digital Twin Construction and Synchronization for Safe Robotic Grasping
Jan 14, 2026Accurate and safe grasping under dynamic and visually occluded conditions remains a core challenge in real-world robotic manipulation. We present SyncTwin, a digital twin framework that unifies fast 3D scene reconstruction and real-to-sim synchronization for robust and safety-aware grasping in such environments. In the offline stage, we employ VGGT to rapidly reconstruct object-level 3D assets from RGB images, forming a reusable geometry library for simulation. During execution, SyncTwin continuously synchronizes the digital twin by tracking real-world object states via point cloud segmentation updates and aligning them through colored-ICP registration. The updated twin enables motion planners to compute collision-free and dynamically feasible trajectories in simulation, which are safely executed on the real robot through a closed real-to-sim-to-real loop. Experiments in dynamic and occluded scenes show that SyncTwin improves grasp accuracy and motion safety, demonstrating the effectiveness of digital-twin synchronization for real-world robotic execution.
ReDDiT: Rehashing Noise for Discrete Visual Generation
May 26, 2025Discrete diffusion models are gaining traction in the visual generative area for their efficiency and compatibility. However, the pioneered attempts still fall behind the continuous counterparts, which we attribute to the noise (absorbing state) design and sampling heuristics. In this study, we propose the rehashing noise framework for discrete diffusion transformer, termed ReDDiT, to extend absorbing states and improve expressive capacity of discrete diffusion models. ReDDiT enriches the potential paths that latent variables can traverse during training with randomized multi-index corruption. The derived rehash sampler, which reverses the randomized absorbing paths, guarantees the diversity and low discrepancy of the generation process. These reformulations lead to more consistent and competitive generation quality, mitigating the need for heavily tuned randomness. Experiments show that ReDDiT significantly outperforms the baseline (reducing gFID from 6.18 to 1.61) and is on par with the continuous counterparts with higher efficiency.
DualAttWaveNet: Multiscale Attention Networks for Satellite Interference Detection
Apr 24, 2025The escalating overlap between non-geostationary orbit (NGSO) and geostationary orbit (GSO) satellite frequency allocations necessitates accurate interference detection methods that address two pivotal technical gaps: computationally efficient signal analysis for real-time operation, and robust anomaly discrimination under varying interference patterns. Existing deep learning approaches employ encoder-decoder anomaly detectors that threshold input-output discrepancies for robustness. While the transformer-based TrID model achieves state-of-the-art performance (AUC: 0.8318, F1: 0.8321), its multi-head attention incurs prohibitive computation time, and its decoupled training of time-frequency models overlooks cross-domain dependencies. To overcome these problems, we propose DualAttWaveNet. A bidirectional attention fusion layer dynamically correlates time-domain samples using parameter-efficient cross-attention routing. A wavelet-regularized reconstruction loss enforces multi-scale consistency. We train the model on public dataset which consists of 48 hours of satellite signals. Experiments show that compared to TrID, DualAttWaveNet improves AUC by 12% and reduces inference time by 50% to 540ms per batch while maintaining F1-score.
Explicit and Implicit Representations in AI-based 3D Reconstruction for Radiology: A systematic literature review
Apr 15, 2025The demand for high-quality medical imaging in clinical practice and assisted diagnosis has made 3D reconstruction in radiological imaging a key research focus. Artificial intelligence (AI) has emerged as a promising approach to enhancing reconstruction accuracy while reducing acquisition and processing time, thereby minimizing patient radiation exposure and discomfort and ultimately benefiting clinical diagnosis. This review explores state-of-the-art AI-based 3D reconstruction algorithms in radiological imaging, categorizing them into explicit and implicit approaches based on their underlying principles. Explicit methods include point-based, volume-based, and Gaussian representations, while implicit methods encompass implicit prior embedding and neural radiance fields. Additionally, we examine commonly used evaluation metrics and benchmark datasets. Finally, we discuss the current state of development, key challenges, and future research directions in this evolving field. Our project available on: https://github.com/Bean-Young/AI4Med.
ClawMachine: Fetching Visual Tokens as An Entity for Referring and Grounding
Jun 17, 2024An essential topic for multimodal large language models (MLLMs) is aligning vision and language concepts at a finer level. In particular, we devote efforts to encoding visual referential information for tasks such as referring and grounding. Existing methods, including proxy encoding and geometry encoding, incorporate additional syntax to encode the object's location, bringing extra burdens in training MLLMs to communicate between language and vision. This study presents ClawMachine, offering a new methodology that notates an entity directly using the visual tokens. It allows us to unify the prompt and answer of visual referential tasks without additional syntax. Upon a joint vision-language vocabulary, ClawMachine unifies visual referring and grounding into an auto-regressive format and learns with a decoder-only architecture. Experiments validate that our model achieves competitive performance across visual referring and grounding tasks with a reduced demand for training data. Additionally, ClawMachine demonstrates a native ability to integrate multi-source information for complex visual reasoning, which prior MLLMs can hardly perform without specific adaptions.
Tackling Non-Stationarity in Reinforcement Learning via Causal-Origin Representation
Jun 05, 2023



In real-world scenarios, the application of reinforcement learning is significantly challenged by complex non-stationarity. Most existing methods attempt to model the changes of the environment explicitly, often requiring impractical prior knowledge. In this paper, we propose a new perspective, positing that non-stationarity can propagate and accumulate through complex causal relationships during state transitions, thereby compounding its sophistication and affecting policy learning. We believe that this challenge can be more effectively addressed by tracing the causal origin of non-stationarity. To this end, we introduce the Causal-Origin REPresentation (COREP) algorithm. COREP primarily employs a guided updating mechanism to learn a stable graph representation for states termed as causal-origin representation. By leveraging this representation, the learned policy exhibits impressive resilience to non-stationarity. We supplement our approach with a theoretical analysis grounded in the causal interpretation for non-stationary reinforcement learning, advocating for the validity of the causal-origin representation. Experimental results further demonstrate the superior performance of COREP over existing methods in tackling non-stationarity.
Learnable Distribution Calibration for Few-Shot Class-Incremental Learning
Oct 01, 2022



Few-shot class-incremental learning (FSCIL) faces challenges of memorizing old class distributions and estimating new class distributions given few training samples. In this study, we propose a learnable distribution calibration (LDC) approach, with the aim to systematically solve these two challenges using a unified framework. LDC is built upon a parameterized calibration unit (PCU), which initializes biased distributions for all classes based on classifier vectors (memory-free) and a single covariance matrix. The covariance matrix is shared by all classes, so that the memory costs are fixed. During base training, PCU is endowed with the ability to calibrate biased distributions by recurrently updating sampled features under the supervision of real distributions. During incremental learning, PCU recovers distributions for old classes to avoid `forgetting', as well as estimating distributions and augmenting samples for new classes to alleviate `over-fitting' caused by the biased distributions of few-shot samples. LDC is theoretically plausible by formatting a variational inference procedure. It improves FSCIL's flexibility as the training procedure requires no class similarity priori. Experiments on CUB200, CIFAR100, and mini-ImageNet datasets show that LDC outperforms the state-of-the-arts by 4.64%, 1.98%, and 3.97%, respectively. LDC's effectiveness is also validated on few-shot learning scenarios.
Learnable Expansion-and-Compression Network for Few-shot Class-Incremental Learning
Apr 06, 2021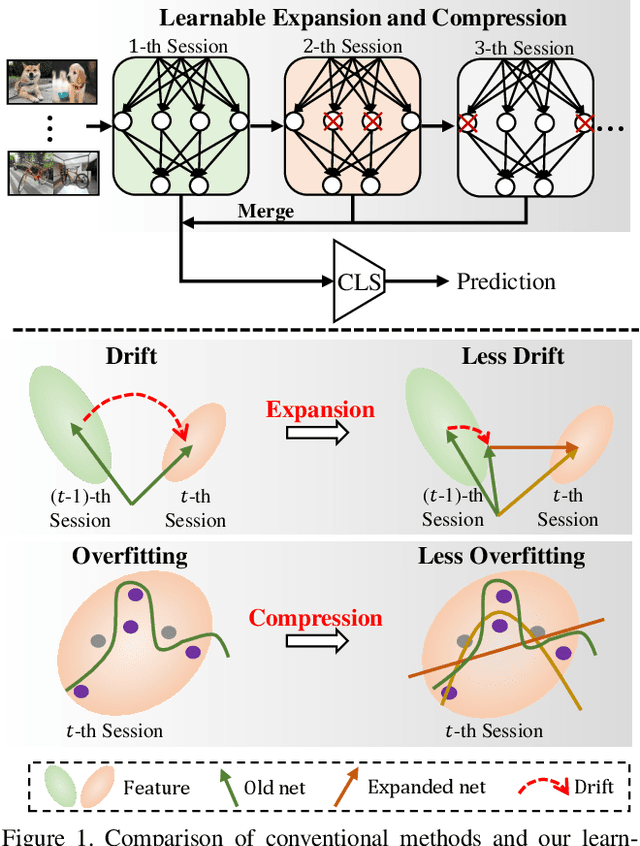
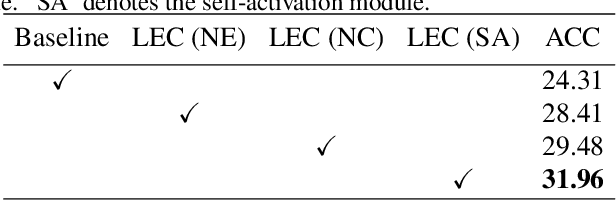

Few-shot class-incremental learning (FSCIL), which targets at continuously expanding model's representation capacity under few supervisions, is an important yet challenging problem. On the one hand, when fitting new tasks (novel classes), features trained on old tasks (old classes) could significantly drift, causing catastrophic forgetting. On the other hand, training the large amount of model parameters with few-shot novel-class examples leads to model over-fitting. In this paper, we propose a learnable expansion-and-compression network (LEC-Net), with the aim to simultaneously solve catastrophic forgetting and model over-fitting problems in a unified framework. By tentatively expanding network nodes, LEC-Net enlarges the representation capacity of features, alleviating feature drift of old network from the perspective of model regularization. By compressing the expanded network nodes, LEC-Net purses minimal increase of model parameters, alleviating over-fitting of the expanded network from a perspective of compact representation. Experiments on the CUB/CIFAR-100 datasets show that LEC-Net improves the baseline by 5~7% while outperforms the state-of-the-art by 5~6%. LEC-Net also demonstrates the potential to be a general incremental learning approach with dynamic model expansion capability.
Beyond Max-Margin: Class Margin Equilibrium for Few-shot Object Detection
Mar 10, 2021
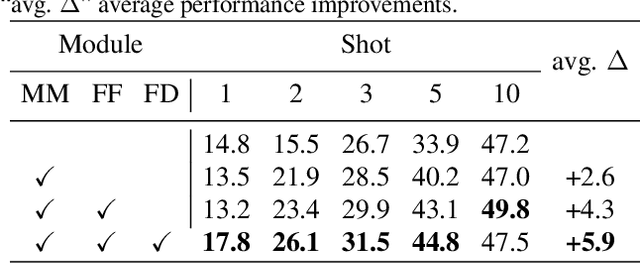


Few-shot object detection has made substantial progressby representing novel class objects using the feature representation learned upon a set of base class objects. However,an implicit contradiction between novel class classification and representation is unfortunately ignored. On the one hand, to achieve accurate novel class classification, the distributions of either two base classes must be far away fromeach other (max-margin). On the other hand, to precisely represent novel classes, the distributions of base classes should be close to each other to reduce the intra-class distance of novel classes (min-margin). In this paper, we propose a class margin equilibrium (CME) approach, with the aim to optimize both feature space partition and novel class reconstruction in a systematic way. CME first converts the few-shot detection problem to the few-shot classification problem by using a fully connected layer to decouple localization features. CME then reserves adequate margin space for novel classes by introducing simple-yet-effective class margin loss during feature learning. Finally, CME pursues margin equilibrium by disturbing the features of novel class instances in an adversarial min-max fashion. Experiments on Pascal VOC and MS-COCO datasets show that CME significantly improves upon two baseline detectors (up to 3 ∼ 5% in average), achieving state-of-the-art performance. Code is available at https://github.com/Bohao-Lee/CME .