 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOV-VG: A Benchmark for Open-Vocabulary Visual Grounding
Oct 22, 2023



Open-vocabulary learning has emerged as a cutting-edge research area, particularly in light of the widespread adoption of vision-based foundational models. Its primary objective is to comprehend novel concepts that are not encompassed within a predefined vocabulary. One key facet of this endeavor is Visual Grounding, which entails locating a specific region within an image based on a corresponding language description. While current foundational models excel at various visual language tasks, there's a noticeable absence of models specifically tailored for open-vocabulary visual grounding. This research endeavor introduces novel and challenging OV tasks, namely Open-Vocabulary Visual Grounding and Open-Vocabulary Phrase Localization. The overarching aim is to establish connections between language descriptions and the localization of novel objects. To facilitate this, we have curated a comprehensive annotated benchmark, encompassing 7,272 OV-VG images and 1,000 OV-PL images. In our pursuit of addressing these challenges, we delved into various baseline methodologies rooted in existing open-vocabulary object detection, VG, and phrase localization frameworks. Surprisingly, we discovered that state-of-the-art methods often falter in diverse scenarios. Consequently, we developed a novel framework that integrates two critical components: Text-Image Query Selection and Language-Guided Feature Attention. These modules are designed to bolster the recognition of novel categories and enhance the alignment between visual and linguistic information. Extensive experiments demonstrate the efficacy of our proposed framework, which consistently attains SOTA performance across the OV-VG task. Additionally, ablation studies provide further evidence of the effectiveness of our innovative models. Codes and datasets will be made publicly available at https://github.com/cv516Buaa/OV-VG.
Iterative Robust Visual Grounding with Masked Reference based Centerpoint Supervision
Jul 23, 2023



Visual Grounding (VG) aims at localizing target objects from an image based on given expressions and has made significant progress with the development of detection and vision transformer. However, existing VG methods tend to generate false-alarm objects when presented with inaccurate or irrelevant descriptions, which commonly occur in practical applications. Moreover, existing methods fail to capture fine-grained features, accurate localization, and sufficient context comprehension from the whole image and textual descriptions. To address both issues, we propose an Iterative Robust Visual Grounding (IR-VG) framework with Masked Reference based Centerpoint Supervision (MRCS). The framework introduces iterative multi-level vision-language fusion (IMVF) for better alignment. We use MRCS to ahieve more accurate localization with point-wised feature supervision. Then, to improve the robustness of VG, we also present a multi-stage false-alarm sensitive decoder (MFSD) to prevent the generation of false-alarm objects when presented with inaccurate expressions. The proposed framework is evaluated on five regular VG datasets and two newly constructed robust VG datasets. Extensive experiments demonstrate that IR-VG achieves new state-of-the-art (SOTA) results, with improvements of 25\% and 10\% compared to existing SOTA approaches on the two newly proposed robust VG datasets. Moreover, the proposed framework is also verified effective on five regular VG datasets. Codes and models will be publicly at https://github.com/cv516Buaa/IR-VG.
Self-Training Guided Disentangled Adaptation for Cross-Domain Remote Sensing Image Semantic Segmentation
Jan 13, 2023Deep convolutional neural networks (DCNNs) based remote sensing (RS) image semantic segmentation technology has achieved great success used in many real-world applications such as geographic element analysis. However, strong dependency on annotated data of specific scene makes it hard for DCNNs to fit different RS scenes. To solve this problem, recent works gradually focus on cross-domain RS image semantic segmentation task. In this task, different ground sampling distance, remote sensing sensor variation and different geographical landscapes are three main factors causing dramatic domain shift between source and target images. To decrease the negative influence of domain shift, we propose a self-training guided disentangled adaptation network (ST-DASegNet). We first propose source student backbone and target student backbone to respectively extract the source-style and target-style feature for both source and target images. Towards the intermediate output feature maps of each backbone, we adopt adversarial learning for alignment. Then, we propose a domain disentangled module to extract the universal feature and purify the distinct feature of source-style and target-style features. Finally, these two features are fused and served as input of source student decoder and target student decoder to generate final predictions. Based on our proposed domain disentangled module, we further propose exponential moving average (EMA) based cross-domain separated self-training mechanism to ease the instability and disadvantageous effect during adversarial optimization. Extensive experiments and analysis on benchmark RS datasets show that ST-DASegNet outperforms previous methods on cross-domain RS image semantic segmentation task and achieves state-of-the-art (SOTA) results. Our code is available at https://github.com/cv516Buaa/ST-DASegNet.
Learnable Distribution Calibration for Few-Shot Class-Incremental Learning
Oct 01, 2022



Few-shot class-incremental learning (FSCIL) faces challenges of memorizing old class distributions and estimating new class distributions given few training samples. In this study, we propose a learnable distribution calibration (LDC) approach, with the aim to systematically solve these two challenges using a unified framework. LDC is built upon a parameterized calibration unit (PCU), which initializes biased distributions for all classes based on classifier vectors (memory-free) and a single covariance matrix. The covariance matrix is shared by all classes, so that the memory costs are fixed. During base training, PCU is endowed with the ability to calibrate biased distributions by recurrently updating sampled features under the supervision of real distributions. During incremental learning, PCU recovers distributions for old classes to avoid `forgetting', as well as estimating distributions and augmenting samples for new classes to alleviate `over-fitting' caused by the biased distributions of few-shot samples. LDC is theoretically plausible by formatting a variational inference procedure. It improves FSCIL's flexibility as the training procedure requires no class similarity priori. Experiments on CUB200, CIFAR100, and mini-ImageNet datasets show that LDC outperforms the state-of-the-arts by 4.64%, 1.98%, and 3.97%, respectively. LDC's effectiveness is also validated on few-shot learning scenarios.
A Multi-Modality Ovarian Tumor Ultrasound Image Dataset for Unsupervised Cross-Domain Semantic Segmentation
Jul 14, 2022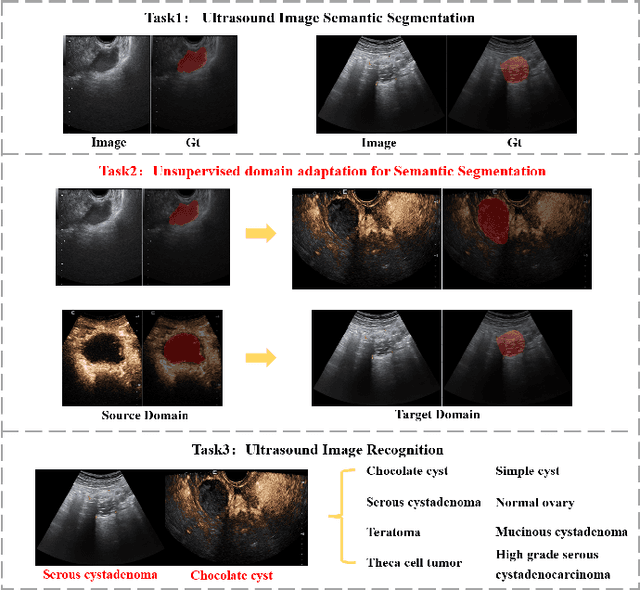
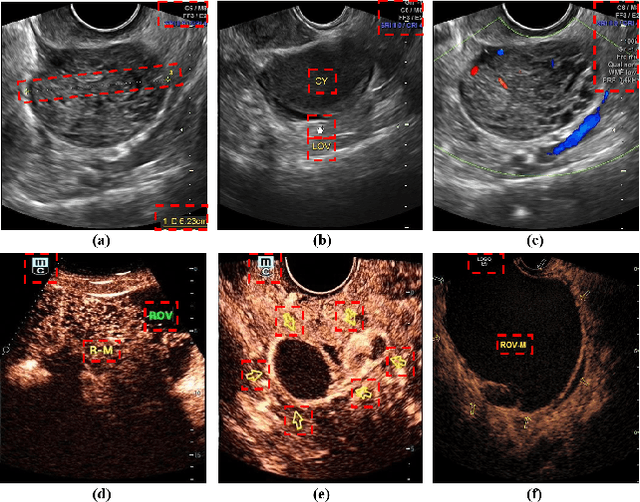
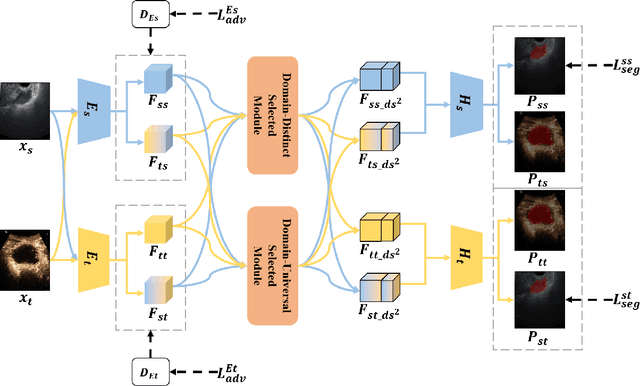
Ovarian cancer is one of the most harmful gynecological diseases. Detecting ovarian tumors in early stage with computer-aided techniques can efficiently decrease the mortality rate. With the improvement of medical treatment standard, ultrasound images are widely applied in clinical treatment. However, recent notable methods mainly focus on single-modality ultrasound ovarian tumor segmentation or recognition, which means there still lacks of researches on exploring the representation capability of multi-modality ultrasound ovarian tumor images. To solve this problem, we propose a Multi-Modality Ovarian Tumor Ultrasound (MMOTU) image dataset containing 1469 2d ultrasound images and 170 contrast enhanced ultrasonography (CEUS) images with pixel-wise and global-wise annotations. Based on MMOTU, we mainly focus on unsupervised cross-domain semantic segmentation task. To solve the domain shift problem, we propose a feature alignment based architecture named Dual-Scheme Domain-Selected Network (DS$^2$Net). Specifically, we first design source-encoder and target-encoder to extract two-style features of source and target images. Then, we propose Domain-Distinct Selected Module (DDSM) and Domain-Universal Selected Module (DUSM) to extract the distinct and universal features in two styles (source-style or target-style). Finally, we fuse these two kinds of features and feed them into the source-decoder and target-decoder to generate final predictions. Extensive comparison experiments and analysis on MMOTU image dataset show that DS$^2$Net can boost the segmentation performance for bidirectional cross-domain adaptation of 2d ultrasound images and CEUS images.
A Feature Consistency Driven Attention Erasing Network for Fine-Grained Image Retrieval
Oct 09, 2021
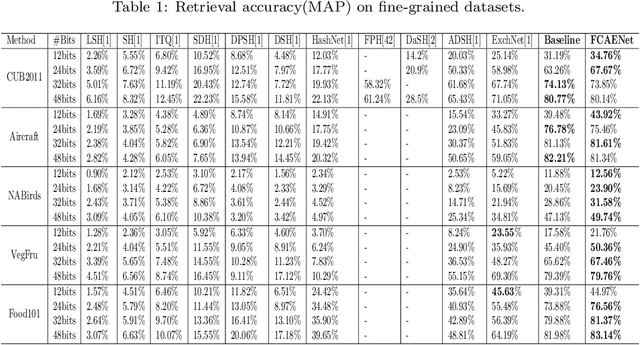
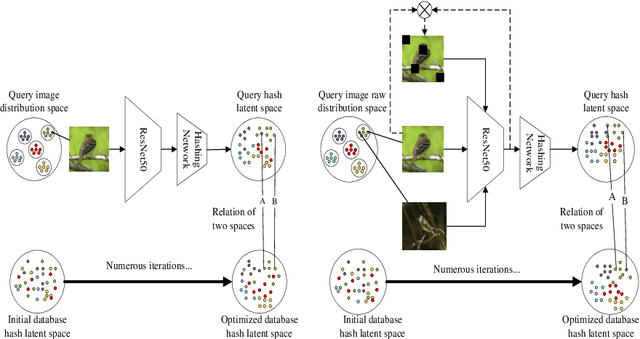
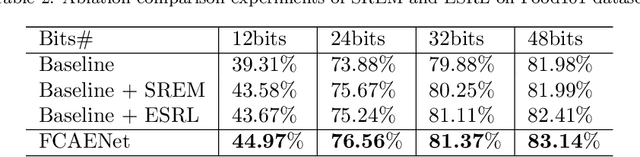
Large-scale fine-grained image retrieval has two main problems. First, low dimensional feature embedding can fasten the retrieval process but bring accuracy reduce due to overlooking the feature of significant attention regions of images in fine-grained datasets. Second, fine-grained images lead to the same category query hash codes mapping into the different cluster in database hash latent space. To handle these two issues, we propose a feature consistency driven attention erasing network (FCAENet) for fine-grained image retrieval. For the first issue, we propose an adaptive augmentation module in FCAENet, which is selective region erasing module (SREM). SREM makes the network more robust on subtle differences of fine-grained task by adaptively covering some regions of raw images. The feature extractor and hash layer can learn more representative hash code for fine-grained images by SREM. With regard to the second issue, we fully exploit the pair-wise similarity information and add the enhancing space relation loss (ESRL) in FCAENet to make the vulnerable relation stabler between the query hash code and database hash code. We conduct extensive experiments on five fine-grained benchmark datasets (CUB2011, Aircraft, NABirds, VegFru, Food101) for 12bits, 24bits, 32bits, 48bits hash code. The results show that FCAENet achieves the state-of-the-art (SOTA) fine-grained retrieval performance compared with other methods.
A Self-Distillation Embedded Supervised Affinity Attention Model for Few-Shot Segmentation
Aug 14, 2021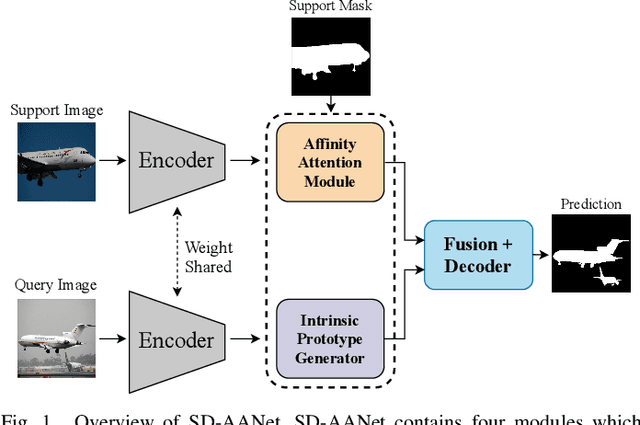



Few-shot semantic segmentation is a challenging task of predicting object categories in pixel-wise with only few annotated samples. However, existing approaches still face two main challenges. First, huge feature distinction between support and query images causes knowledge transferring barrier, which harms the segmentation performance. Second, few support samples cause unrepresentative of support features, hardly to guide high-quality query segmentation. To deal with the above two issues, we propose self-distillation embedded supervised affinity attention model (SD-AANet) to improve the performance of few-shot segmentation task. Specifically, the self-distillation guided prototype module (SDPM) extracts intrinsic prototype by self-distillation between support and query to capture representative features. The supervised affinity attention module (SAAM) adopts support ground truth to guide the production of high quality query attention map, which can learn affinity information to focus on whole area of query target. Extensive experiments prove that our SD-AANet significantly improves the performance comparing with existing methods. Comprehensive ablation experiments and visualization studies also show the significant effect of SDPM and SAAM for few-shot segmentation task. On benchmark datasets, PASCAL-5i and COCO-20i, our proposed SD-AANet both achieve state-of-the-art results. Our code will be publicly available soon.
Anti-aliasing Semantic Reconstruction for Few-Shot Semantic Segmentation
Jun 01, 2021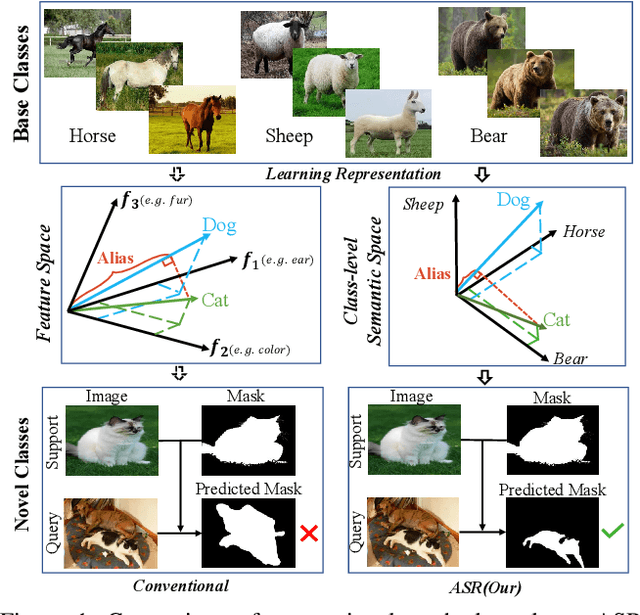

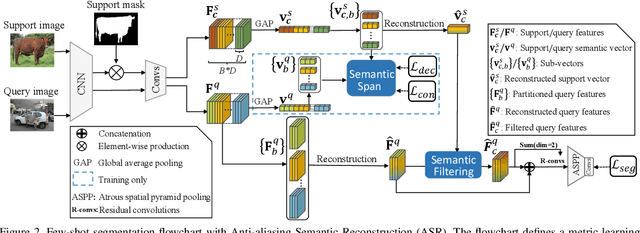

Encouraging progress in few-shot semantic segmentation has been made by leveraging features learned upon base classes with sufficient training data to represent novel classes with few-shot examples. However, this feature sharing mechanism inevitably causes semantic aliasing between novel classes when they have similar compositions of semantic concepts. In this paper, we reformulate few-shot segmentation as a semantic reconstruction problem, and convert base class features into a series of basis vectors which span a class-level semantic space for novel class reconstruction. By introducing contrastive loss, we maximize the orthogonality of basis vectors while minimizing semantic aliasing between classes. Within the reconstructed representation space, we further suppress interference from other classes by projecting query features to the support vector for precise semantic activation. Our proposed approach, referred to as anti-aliasing semantic reconstruction (ASR), provides a systematic yet interpretable solution for few-shot learning problems. Extensive experiments on PASCAL VOC and MS COCO datasets show that ASR achieves strong results compared with the prior works.
Learnable Expansion-and-Compression Network for Few-shot Class-Incremental Learning
Apr 06, 2021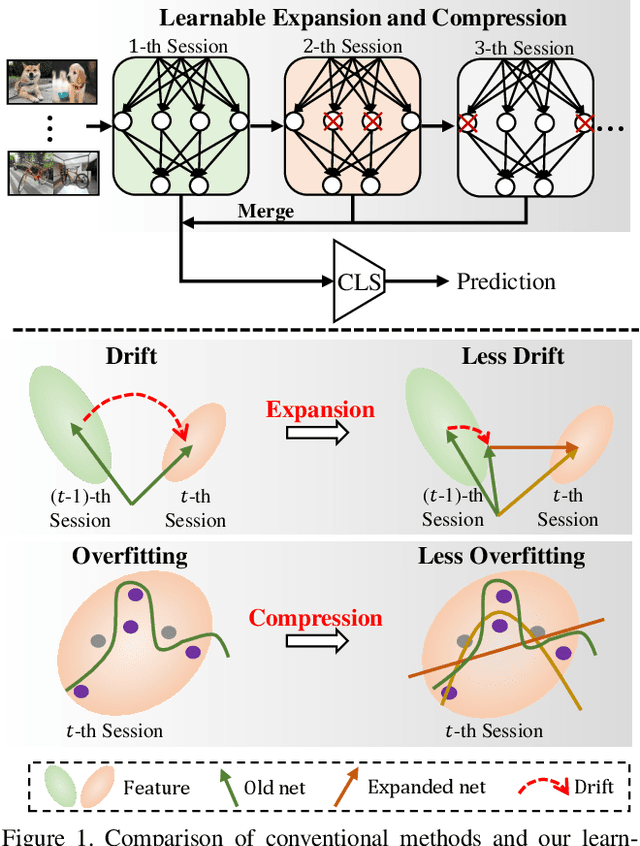
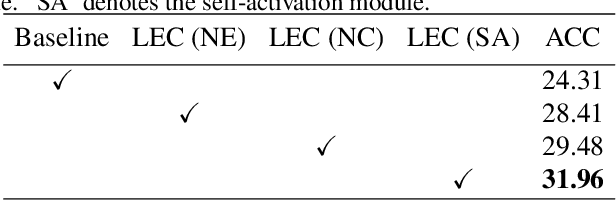

Few-shot class-incremental learning (FSCIL), which targets at continuously expanding model's representation capacity under few supervisions, is an important yet challenging problem. On the one hand, when fitting new tasks (novel classes), features trained on old tasks (old classes) could significantly drift, causing catastrophic forgetting. On the other hand, training the large amount of model parameters with few-shot novel-class examples leads to model over-fitting. In this paper, we propose a learnable expansion-and-compression network (LEC-Net), with the aim to simultaneously solve catastrophic forgetting and model over-fitting problems in a unified framework. By tentatively expanding network nodes, LEC-Net enlarges the representation capacity of features, alleviating feature drift of old network from the perspective of model regularization. By compressing the expanded network nodes, LEC-Net purses minimal increase of model parameters, alleviating over-fitting of the expanded network from a perspective of compact representation. Experiments on the CUB/CIFAR-100 datasets show that LEC-Net improves the baseline by 5~7% while outperforms the state-of-the-art by 5~6%. LEC-Net also demonstrates the potential to be a general incremental learning approach with dynamic model expansion capability.