 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEARD: Benchmarking the Adversarial Robustness for Dataset Distillation
Nov 14, 2024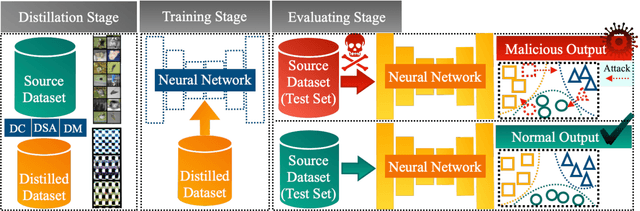
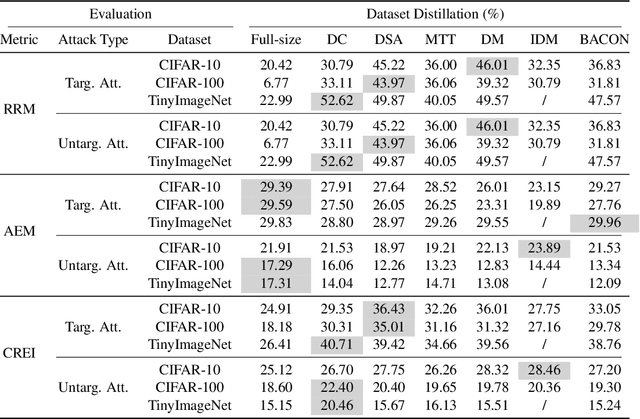
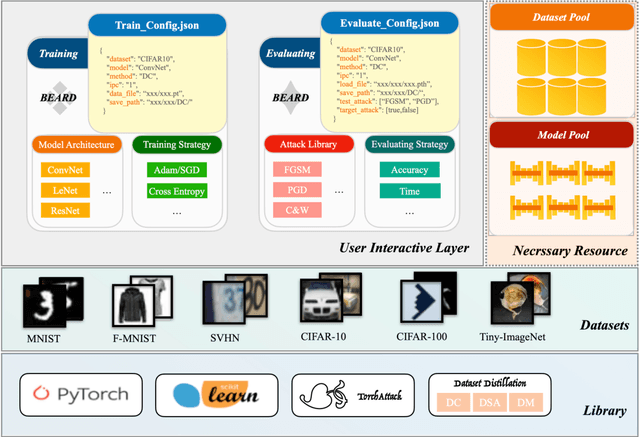
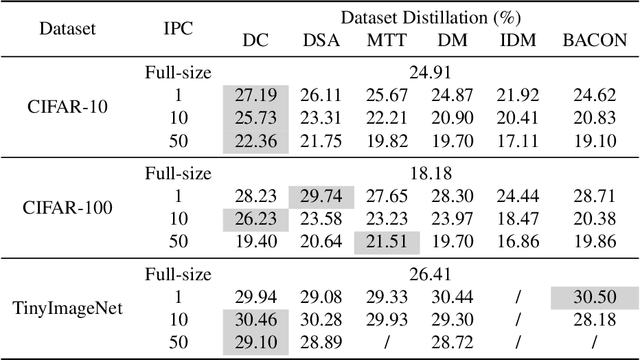
Dataset Distillation (DD) is an emerging technique that compresses large-scale datasets into significantly smaller synthesized datasets while preserving high test performance and enabling the efficient training of large models. However, current research primarily focuses on enhancing evaluation accuracy under limited compression ratios, often overlooking critical security concerns such as adversarial robustness. A key challenge in evaluating this robustness lies in the complex interactions between distillation methods, model architectures, and adversarial attack strategies, which complicate standardized assessments. To address this, we introduce BEARD, an open and unified benchmark designed to systematically assess the adversarial robustness of DD methods, including DM, IDM, and BACON. BEARD encompasses a variety of adversarial attacks (e.g., FGSM, PGD, C&W) on distilled datasets like CIFAR-10/100 and TinyImageNet. Utilizing an adversarial game framework, it introduces three key metrics: Robustness Ratio (RR), Attack Efficiency Ratio (AE), and Comprehensive Robustness-Efficiency Index (CREI). Our analysis includes unified benchmarks, various Images Per Class (IPC) settings, and the effects of adversarial training. Results are available on the BEARD Leaderboard, along with a library providing model and dataset pools to support reproducible research. Access the code at BEARD.
BACON: Bayesian Optimal Condensation Framework for Dataset Distillation
Jun 03, 2024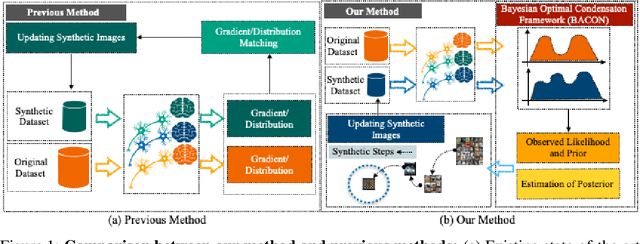
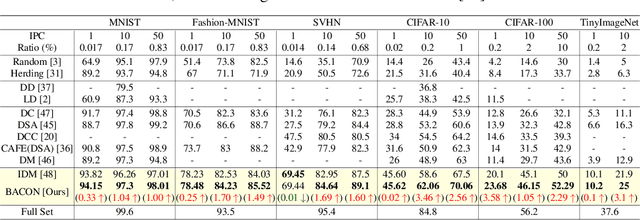
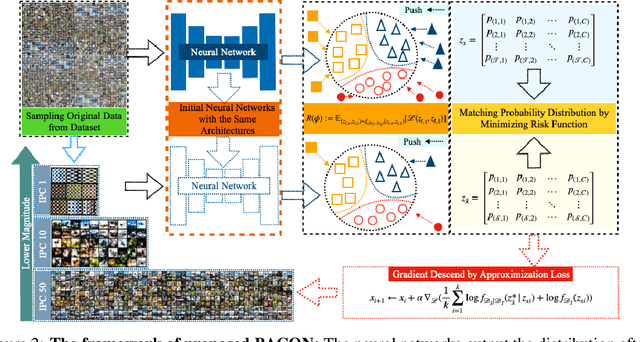
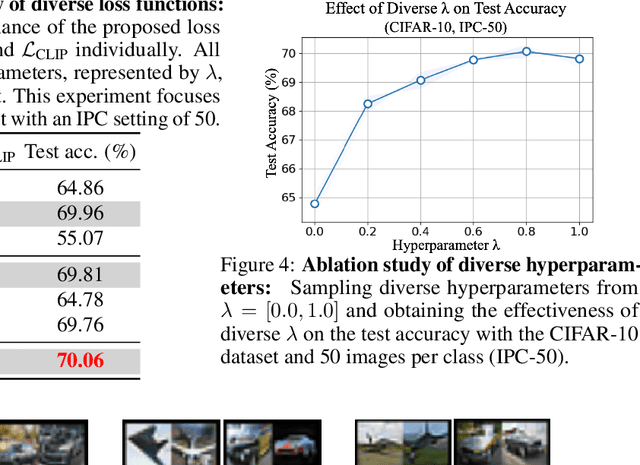
Dataset Distillation (DD) aims to distill knowledge from extensive datasets into more compact ones while preserving performance on the test set, thereby reducing storage costs and training expenses. However, existing methods often suffer from computational intensity, particularly exhibiting suboptimal performance with large dataset sizes due to the lack of a robust theoretical framework for analyzing the DD problem. To address these challenges, we propose the BAyesian optimal CONdensation framework (BACON), which is the first work to introduce the Bayesian theoretical framework to the literature of DD. This framework provides theoretical support for enhancing the performance of DD. Furthermore, BACON formulates the DD problem as the minimization of the expected risk function in joint probability distributions using the Bayesian framework. Additionally, by analyzing the expected risk function for optimal condensation, we derive a numerically feasible lower bound based on specific assumptions, providing an approximate solution for BACON. We validate BACON across several datasets, demonstrating its superior performance compared to existing state-of-the-art methods. For instance, under the IPC-10 setting, BACON achieves a 3.46% accuracy gain over the IDM method on the CIFAR-10 dataset and a 3.10% gain on the TinyImageNet dataset. Our extensive experiments confirm the effectiveness of BACON and its seamless integration with existing methods, thereby enhancing their performance for the DD task. Code and distilled datasets are available at BACON.
MVPatch: More Vivid Patch for Adversarial Camouflaged Attacks on Object Detectors in the Physical World
Jan 12, 2024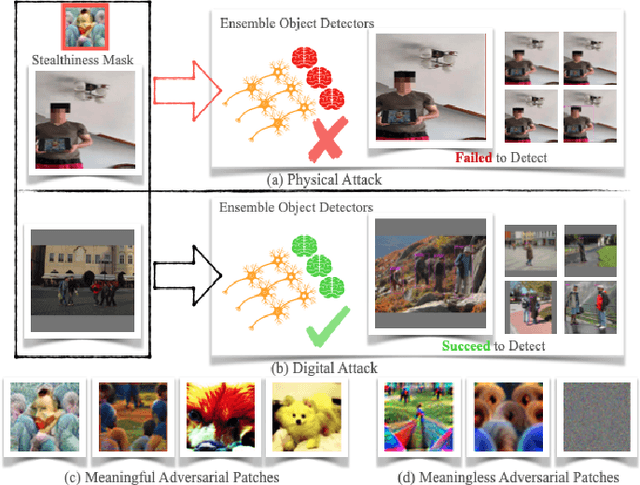
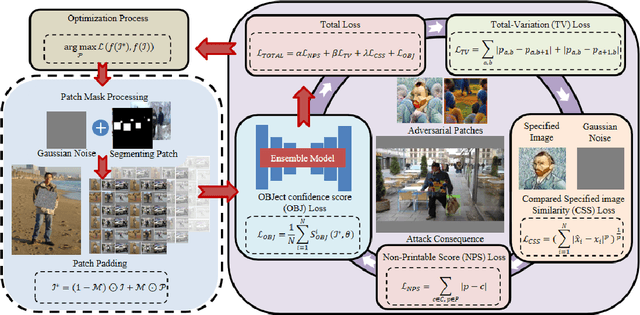


Recent investigations demonstrate that adversarial patches can be utilized to manipulate the result of object detection models. However, the conspicuous patterns on these patches may draw more attention and raise suspicions among humans. Moreover, existing works have primarily focused on enhancing the efficacy of attacks in the physical domain, rather than seeking to optimize their stealth attributes and transferability potential. To address these issues, we introduce a dual-perception-based attack framework that generates an adversarial patch known as the More Vivid Patch (MVPatch). The framework consists of a model-perception degradation method and a human-perception improvement method. To derive the MVPatch, we formulate an iterative process that simultaneously constrains the efficacy of multiple object detectors and refines the visual correlation between the generated adversarial patch and a realistic image. Our method employs a model-perception-based approach that reduces the object confidence scores of several object detectors to boost the transferability of adversarial patches. Further, within the human-perception-based framework, we put forward a lightweight technique for visual similarity measurement that facilitates the development of inconspicuous and natural adversarial patches and eliminates the reliance on additional generative models. Additionally, we introduce the naturalness score and transferability score as metrics for an unbiased assessment of various adversarial patches' natural appearance and transferability capacity. Extensive experiments demonstrate that the proposed MVPatch algorithm achieves superior attack transferability compared to similar algorithms in both digital and physical domains while also exhibiting a more natural appearance. These findings emphasize the remarkable stealthiness and transferability of the proposed MVPatch attack algorithm.
OV-VG: A Benchmark for Open-Vocabulary Visual Grounding
Oct 22, 2023



Open-vocabulary learning has emerged as a cutting-edge research area, particularly in light of the widespread adoption of vision-based foundational models. Its primary objective is to comprehend novel concepts that are not encompassed within a predefined vocabulary. One key facet of this endeavor is Visual Grounding, which entails locating a specific region within an image based on a corresponding language description. While current foundational models excel at various visual language tasks, there's a noticeable absence of models specifically tailored for open-vocabulary visual grounding. This research endeavor introduces novel and challenging OV tasks, namely Open-Vocabulary Visual Grounding and Open-Vocabulary Phrase Localization. The overarching aim is to establish connections between language descriptions and the localization of novel objects. To facilitate this, we have curated a comprehensive annotated benchmark, encompassing 7,272 OV-VG images and 1,000 OV-PL images. In our pursuit of addressing these challenges, we delved into various baseline methodologies rooted in existing open-vocabulary object detection, VG, and phrase localization frameworks. Surprisingly, we discovered that state-of-the-art methods often falter in diverse scenarios. Consequently, we developed a novel framework that integrates two critical components: Text-Image Query Selection and Language-Guided Feature Attention. These modules are designed to bolster the recognition of novel categories and enhance the alignment between visual and linguistic information. Extensive experiments demonstrate the efficacy of our proposed framework, which consistently attains SOTA performance across the OV-VG task. Additionally, ablation studies provide further evidence of the effectiveness of our innovative models. Codes and datasets will be made publicly available at https://github.com/cv516Buaa/OV-VG.
Iterative Robust Visual Grounding with Masked Reference based Centerpoint Supervision
Jul 23, 2023



Visual Grounding (VG) aims at localizing target objects from an image based on given expressions and has made significant progress with the development of detection and vision transformer. However, existing VG methods tend to generate false-alarm objects when presented with inaccurate or irrelevant descriptions, which commonly occur in practical applications. Moreover, existing methods fail to capture fine-grained features, accurate localization, and sufficient context comprehension from the whole image and textual descriptions. To address both issues, we propose an Iterative Robust Visual Grounding (IR-VG) framework with Masked Reference based Centerpoint Supervision (MRCS). The framework introduces iterative multi-level vision-language fusion (IMVF) for better alignment. We use MRCS to ahieve more accurate localization with point-wised feature supervision. Then, to improve the robustness of VG, we also present a multi-stage false-alarm sensitive decoder (MFSD) to prevent the generation of false-alarm objects when presented with inaccurate expressions. The proposed framework is evaluated on five regular VG datasets and two newly constructed robust VG datasets. Extensive experiments demonstrate that IR-VG achieves new state-of-the-art (SOTA) results, with improvements of 25\% and 10\% compared to existing SOTA approaches on the two newly proposed robust VG datasets. Moreover, the proposed framework is also verified effective on five regular VG datasets. Codes and models will be publicly at https://github.com/cv516Buaa/IR-VG.
Look in Different Views: Multi-Scheme Regression Guided Cell Instance Segmentation
Aug 17, 2022
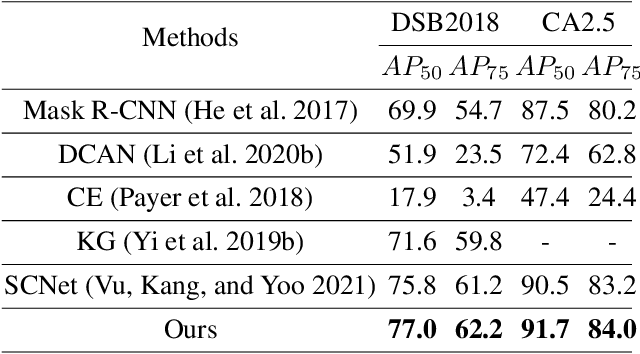
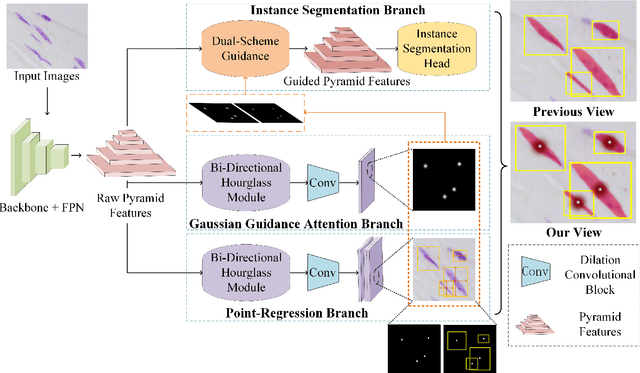
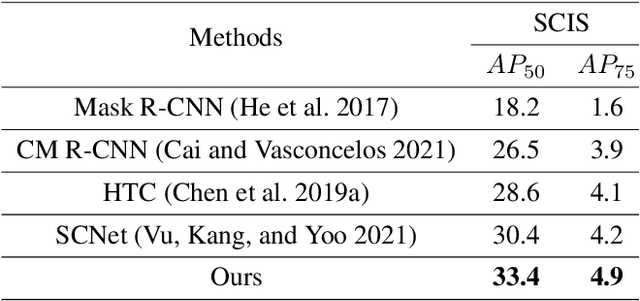
Cell instance segmentation is a new and challenging task aiming at joint detection and segmentation of every cell in an image. Recently, many instance segmentation methods have applied in this task. Despite their great success, there still exists two main weaknesses caused by uncertainty of localizing cell center points. First, densely packed cells can easily be recognized into one cell. Second, elongated cell can easily be recognized into two cells. To overcome these two weaknesses, we propose a novel cell instance segmentation network based on multi-scheme regression guidance. With multi-scheme regression guidance, the network has the ability to look each cell in different views. Specifically, we first propose a gaussian guidance attention mechanism to use gaussian labels for guiding the network's attention. We then propose a point-regression module for assisting the regression of cell center. Finally, we utilize the output of the above two modules to further guide the instance segmentation. With multi-scheme regression guidance, we can take full advantage of the characteristics of different regions, especially the central region of the cell. We conduct extensive experiments on benchmark datasets, DSB2018, CA2.5 and SCIS. The encouraging results show that our network achieves SOTA (state-of-the-art) performance. On the DSB2018 and CA2.5, our network surpasses previous methods by 1.2% (AP50). Particularly on SCIS dataset, our network performs stronger by large margin (3.0% higher AP50). Visualization and analysis further prove that our proposed method is interpretable.
PGGANet: Pose Guided Graph Attention Network for Person Re-identification
Nov 29, 2021

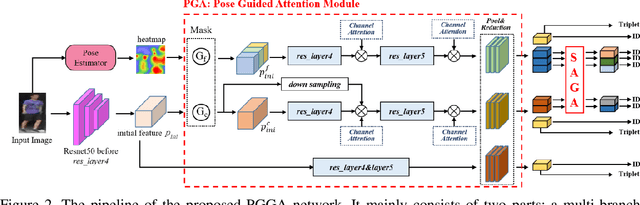
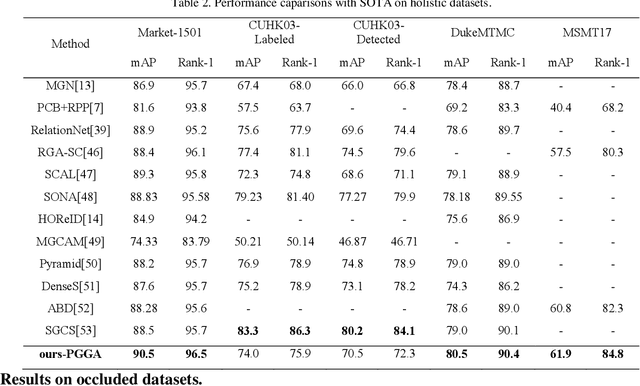
Person re-identification (ReID) aims at retrieving a person from images captured by different cameras. For deep-learning-based ReID methods, it has been proved that using local features together with global feature of person image could help to give robust feature representations for person retrieval. Human pose information could provide the locations of human skeleton to effectively guide the network to pay more attention on these key areas and could also help to reduce the noise distractions from background or occlusions. However, methods proposed by previous pose-related works might not be able to fully exploit the benefits of pose information and did not take into consideration the different contributions of different local features. In this paper, we propose a pose guided graph attention network, a multi-branch architecture consisting of one branch for global feature, one branch for mid-granular body features and one branch for fine-granular key point features. We use a pre-trained pose estimator to generate the key-point heatmap for local feature learning and carefully design a graph attention convolution layer to re-evaluate the contribution weights of extracted local features by modeling the similarities relations. Experiments results demonstrate the effectiveness of our approach on discriminative feature learning and we show that our model achieves state-of-the-art performances on several mainstream evaluation datasets. We also conduct a plenty of ablation studies and design different kinds of comparison experiments for our network to prove its effectiveness and robustness, including holistic datasets, partial datasets, occluded datasets and cross-domain tests.
MM-FSOD: Meta and metric integrated few-shot object detection
Dec 30, 2020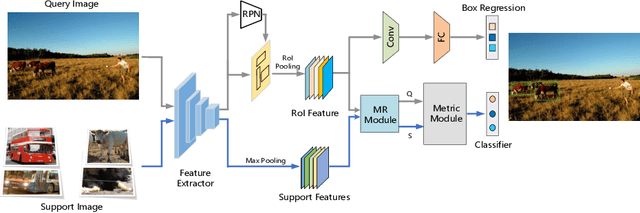

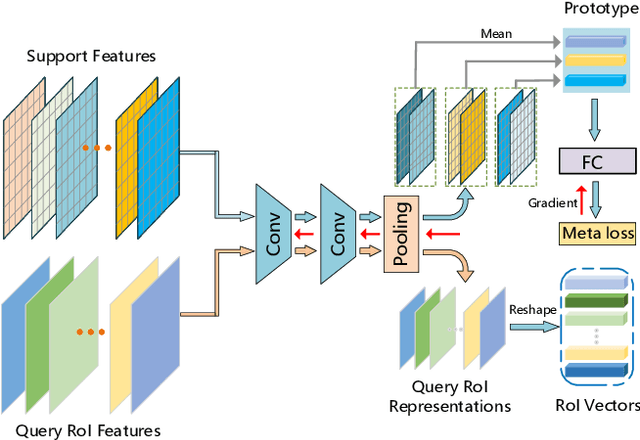
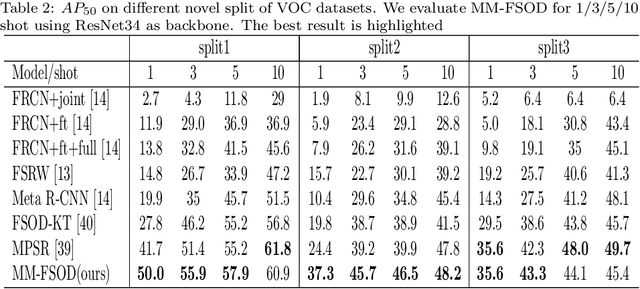
In the object detection task, CNN (Convolutional neural networks) models always need a large amount of annotated examples in the training process. To reduce the dependency of expensive annotations, few-shot object detection has become an increasing research focus. In this paper, we present an effective object detection framework (MM-FSOD) that integrates metric learning and meta-learning to tackle the few-shot object detection task. Our model is a class-agnostic detection model that can accurately recognize new categories, which are not appearing in training samples. Specifically, to fast learn the features of new categories without a fine-tuning process, we propose a meta-representation module (MR module) to learn intra-class mean prototypes. MR module is trained with a meta-learning method to obtain the ability to reconstruct high-level features. To further conduct similarity of features between support prototype with query RoIs features, we propose a Pearson metric module (PR module) which serves as a classifier. Compared to the previous commonly used metric method, cosine distance metric. PR module enables the model to align features into discriminative embedding space. We conduct extensive experiments on benchmark datasets FSOD, MS COCO, and PASCAL VOC to demonstrate the feasibility and efficiency of our model. Comparing with the previous method, MM-FSOD achieves state-of-the-art (SOTA) results.