 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative3D: End-to-End 3D Scene Generation via Unified Mesh-Texture Modeling and Semantic Alignment
Jun 05, 2026This paper presents Native3D, the first end-to-end 3D scene generation framework that completely bypasses 2D intermediate representations. Traditional approaches typically require adapting 3D representations to the 2D domain to leverage pre-trained diffusion models, which inevitably introduces domain adaptation issues including geometric structural distortion and texture detail degradation. To address these limitations, we design a unified mesh-texture joint representation that simultaneously models both geometric structures and texture features through a Transformer-based scene encoder, effectively maintaining spatial relationships and visual consistency among objects within scenes. We further propose the 3D Representation Alignment Loss (3D REPA Loss), which employs an improved contrastive learning mechanism to align multi-level semantic representations in the latent space, significantly enhancing geometric and textural fidelity. Experimental results demonstrate that Native3D outperforms existing methods in both generation quality and editing flexibility, providing a novel solution for 3D scene editing.
Beyond Semantic Organization: Memory as Execution State Management for Long-Horizon Agents
Jun 04, 2026LLM-based agents increasingly tackle long-horizon tasks with interdependent decisions, where each action reshapes future constraints and intermediate errors can cascade. Existing RAG and agent memory systems organize histories by semantic similarity, retrieving content-relevant entries at decision time. We argue that this design mismatches execution-state dependencies: it fragments decision trajectories and mixes valid and erroneous traces, hindering coherent state reconstruction and error isolation. We propose MAGE (Memory as Agent-Guided Exploration), an active execution-state manager that stores interactions in a hierarchical state tree. The agent derives its state from the active root-to-current path, combining subgoal summaries, recent traces, and hints from prior branches. Four coupled operations maintain the tree: Grow records new traces, Compress summarizes completed subgoals, Maintain validates summaries, and Revise restores a target boundary and resumes on a new branch. This design bounds context growth while preserving state integrity and isolating flawed segments from the active path. Experiments on MemoryArena show that MAGE improves the average task success rate by 7.8--20.4 pp over baselines, while reducing token consumption by 55.1%.
Tora: Trajectory-oriented Diffusion Transformer for Video Generation
Jul 31, 2024Recent advancements in Diffusion Transformer (DiT) have demonstrated remarkable proficiency in producing high-quality video content. Nonetheless, the potential of transformer-based diffusion models for effectively generating videos with controllable motion remains an area of limited exploration. This paper introduces Tora, the first trajectory-oriented DiT framework that integrates textual, visual, and trajectory conditions concurrently for video generation. Specifically, Tora consists of a Trajectory Extractor~(TE), a Spatial-Temporal DiT, and a Motion-guidance Fuser~(MGF). The TE encodes arbitrary trajectories into hierarchical spacetime motion patches with a 3D video compression network. The MGF integrates the motion patches into the DiT blocks to generate consistent videos following trajectories. Our design aligns seamlessly with DiT's scalability, allowing precise control of video content's dynamics with diverse durations, aspect ratios, and resolutions. Extensive experiments demonstrate Tora's excellence in achieving high motion fidelity, while also meticulously simulating the movement of the physical world. Page can be found at https://ali-videoai.github.io/tora_video.
Deep Linear Array Pushbroom Image Restoration: A Degradation Pipeline and Jitter-Aware Restoration Network
Jan 16, 2024



Linear Array Pushbroom (LAP) imaging technology is widely used in the realm of remote sensing. However, images acquired through LAP always suffer from distortion and blur because of camera jitter. Traditional methods for restoring LAP images, such as algorithms estimating the point spread function (PSF), exhibit limited performance. To tackle this issue, we propose a Jitter-Aware Restoration Network (JARNet), to remove the distortion and blur in two stages. In the first stage, we formulate an Optical Flow Correction (OFC) block to refine the optical flow of the degraded LAP images, resulting in pre-corrected images where most of the distortions are alleviated. In the second stage, for further enhancement of the pre-corrected images, we integrate two jitter-aware techniques within the Spatial and Frequency Residual (SFRes) block: 1) introducing Coordinate Attention (CoA) to the SFRes block in order to capture the jitter state in orthogonal direction; 2) manipulating image features in both spatial and frequency domains to leverage local and global priors. Additionally, we develop a data synthesis pipeline, which applies Continue Dynamic Shooting Model (CDSM) to simulate realistic degradation in LAP images. Both the proposed JARNet and LAP image synthesis pipeline establish a foundation for addressing this intricate challenge. Extensive experiments demonstrate that the proposed two-stage method outperforms state-of-the-art image restoration models. Code is available at https://github.com/JHW2000/JARNet.
Iterative Robust Visual Grounding with Masked Reference based Centerpoint Supervision
Jul 23, 2023



Visual Grounding (VG) aims at localizing target objects from an image based on given expressions and has made significant progress with the development of detection and vision transformer. However, existing VG methods tend to generate false-alarm objects when presented with inaccurate or irrelevant descriptions, which commonly occur in practical applications. Moreover, existing methods fail to capture fine-grained features, accurate localization, and sufficient context comprehension from the whole image and textual descriptions. To address both issues, we propose an Iterative Robust Visual Grounding (IR-VG) framework with Masked Reference based Centerpoint Supervision (MRCS). The framework introduces iterative multi-level vision-language fusion (IMVF) for better alignment. We use MRCS to ahieve more accurate localization with point-wised feature supervision. Then, to improve the robustness of VG, we also present a multi-stage false-alarm sensitive decoder (MFSD) to prevent the generation of false-alarm objects when presented with inaccurate expressions. The proposed framework is evaluated on five regular VG datasets and two newly constructed robust VG datasets. Extensive experiments demonstrate that IR-VG achieves new state-of-the-art (SOTA) results, with improvements of 25\% and 10\% compared to existing SOTA approaches on the two newly proposed robust VG datasets. Moreover, the proposed framework is also verified effective on five regular VG datasets. Codes and models will be publicly at https://github.com/cv516Buaa/IR-VG.
Mobile Image Restoration via Prior Quantization
May 10, 2023



In digital images, the performance of optical aberration is a multivariate degradation, where the spectral of the scene, the lens imperfections, and the field of view together contribute to the results. Besides eliminating it at the hardware level, the post-processing system, which utilizes various prior information, is significant for correction. However, due to the content differences among priors, the pipeline that aligns these factors shows limited efficiency and unoptimized restoration. Here, we propose a prior quantization model to correct the optical aberrations in image processing systems. To integrate these messages, we encode various priors into a latent space and quantify them by the learnable codebooks. After quantization, the prior codes are fused with the image restoration branch to realize targeted optical aberration correction. Comprehensive experiments demonstrate the flexibility of the proposed method and validate its potential to accomplish targeted restoration for a specific camera. Furthermore, our model promises to analyze the correlation between the various priors and the optical aberration of devices, which is helpful for joint soft-hardware design.
Look in Different Views: Multi-Scheme Regression Guided Cell Instance Segmentation
Aug 17, 2022
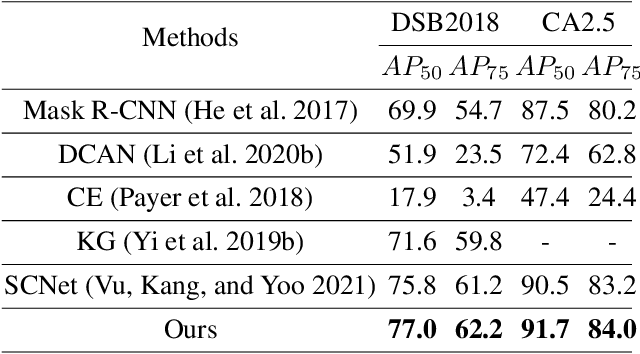
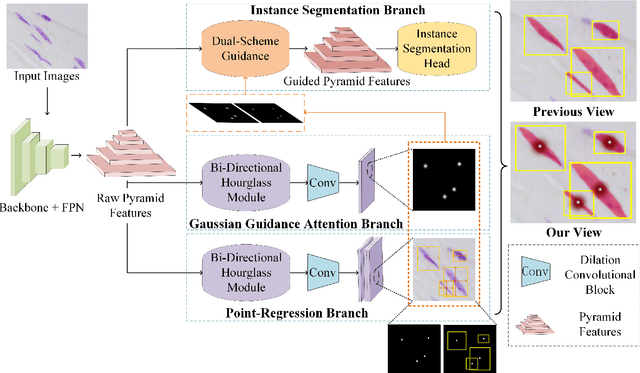
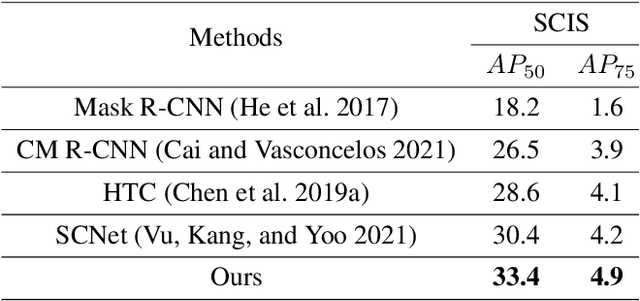
Cell instance segmentation is a new and challenging task aiming at joint detection and segmentation of every cell in an image. Recently, many instance segmentation methods have applied in this task. Despite their great success, there still exists two main weaknesses caused by uncertainty of localizing cell center points. First, densely packed cells can easily be recognized into one cell. Second, elongated cell can easily be recognized into two cells. To overcome these two weaknesses, we propose a novel cell instance segmentation network based on multi-scheme regression guidance. With multi-scheme regression guidance, the network has the ability to look each cell in different views. Specifically, we first propose a gaussian guidance attention mechanism to use gaussian labels for guiding the network's attention. We then propose a point-regression module for assisting the regression of cell center. Finally, we utilize the output of the above two modules to further guide the instance segmentation. With multi-scheme regression guidance, we can take full advantage of the characteristics of different regions, especially the central region of the cell. We conduct extensive experiments on benchmark datasets, DSB2018, CA2.5 and SCIS. The encouraging results show that our network achieves SOTA (state-of-the-art) performance. On the DSB2018 and CA2.5, our network surpasses previous methods by 1.2% (AP50). Particularly on SCIS dataset, our network performs stronger by large margin (3.0% higher AP50). Visualization and analysis further prove that our proposed method is interpretable.