 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Linear Array Pushbroom Image Restoration: A Degradation Pipeline and Jitter-Aware Restoration Network
Jan 16, 2024



Linear Array Pushbroom (LAP) imaging technology is widely used in the realm of remote sensing. However, images acquired through LAP always suffer from distortion and blur because of camera jitter. Traditional methods for restoring LAP images, such as algorithms estimating the point spread function (PSF), exhibit limited performance. To tackle this issue, we propose a Jitter-Aware Restoration Network (JARNet), to remove the distortion and blur in two stages. In the first stage, we formulate an Optical Flow Correction (OFC) block to refine the optical flow of the degraded LAP images, resulting in pre-corrected images where most of the distortions are alleviated. In the second stage, for further enhancement of the pre-corrected images, we integrate two jitter-aware techniques within the Spatial and Frequency Residual (SFRes) block: 1) introducing Coordinate Attention (CoA) to the SFRes block in order to capture the jitter state in orthogonal direction; 2) manipulating image features in both spatial and frequency domains to leverage local and global priors. Additionally, we develop a data synthesis pipeline, which applies Continue Dynamic Shooting Model (CDSM) to simulate realistic degradation in LAP images. Both the proposed JARNet and LAP image synthesis pipeline establish a foundation for addressing this intricate challenge. Extensive experiments demonstrate that the proposed two-stage method outperforms state-of-the-art image restoration models. Code is available at https://github.com/JHW2000/JARNet.
Let Segment Anything Help Image Dehaze
Jun 28, 2023



The large language model and high-level vision model have achieved impressive performance improvements with large datasets and model sizes. However, low-level computer vision tasks, such as image dehaze and blur removal, still rely on a small number of datasets and small-sized models, which generally leads to overfitting and local optima. Therefore, we propose a framework to integrate large-model prior into low-level computer vision tasks. Just as with the task of image segmentation, the degradation of haze is also texture-related. So we propose to detect gray-scale coding, network channel expansion, and pre-dehaze structures to integrate large-model prior knowledge into any low-level dehazing network. We demonstrate the effectiveness and applicability of large models in guiding low-level visual tasks through different datasets and algorithms comparison experiments. Finally, we demonstrate the effect of grayscale coding, network channel expansion, and recurrent network structures through ablation experiments. Under the conditions where additional data and training resources are not required, we successfully prove that the integration of large-model prior knowledge will improve the dehaze performance and save training time for low-level visual tasks.
Toward Real Flare Removal: A Comprehensive Pipeline and A New Benchmark
Jun 28, 2023



Photographing in the under-illuminated scenes, the presence of complex light sources often leave strong flare artifacts in images, where the intensity, the spectrum, the reflection, and the aberration altogether contribute the deterioration. Besides the image quality, it also influence the performance of down-stream visual applications. Thus, removing the lens flare and ghosts is a challenge issue especially in low-light environment. However, existing methods for flare removal mainly restricted to the problems of inadequate simulation and real-world capture, where the categories of scattered flares are singular and the reflected ghosts are unavailable. Therefore, a comprehensive deterioration procedure is crucial for constructing the dataset of flare removal. Based on the theoretical analysis and real-world evaluation, we propose a well-developed methodology for generating the data-pairs with flare deterioration. The procedure is comprehensive, where the similarity of scattered flares and the symmetric effect of reflected ghosts are realized. Moreover, we also construct a real-shot pipeline that respectively processes the effects of scattering and reflective flares, aiming to directly generate the data for end-to-end methods. Experimental results show that the proposed methodology add diversity to the existing flare datasets and construct a comprehensive mapping procedure for flare data pairs. And our method facilities the data-driven model to realize better restoration in flare images and proposes a better evaluation system based on real shots, resulting promote progress in the area of real flare removal.
Computational Optics for Mobile Terminals in Mass Production
May 10, 2023



Correcting the optical aberrations and the manufacturing deviations of cameras is a challenging task. Due to the limitation on volume and the demand for mass production, existing mobile terminals cannot rectify optical degradation. In this work, we systematically construct the perturbed lens system model to illustrate the relationship between the deviated system parameters and the spatial frequency response measured from photographs. To further address this issue, an optimization framework is proposed based on this model to build proxy cameras from the machining samples' SFRs. Engaging with the proxy cameras, we synthetic data pairs, which encode the optical aberrations and the random manufacturing biases, for training the learning-based algorithms. In correcting aberration, although promising results have been shown recently with convolutional neural networks, they are hard to generalize to stochastic machining biases. Therefore, we propose a dilated Omni-dimensional dynamic convolution and implement it in post-processing to account for the manufacturing degradation. Extensive experiments which evaluate multiple samples of two representative devices demonstrate that the proposed optimization framework accurately constructs the proxy camera. And the dynamic processing model is well-adapted to manufacturing deviations of different cameras, realizing perfect computational photography. The evaluation shows that the proposed method bridges the gap between optical design, system machining, and post-processing pipeline, shedding light on the joint of image signal reception (lens and sensor) and image signal processing.
* Published in IEEE TPAMI, 15 pages, 13 figures
Optical Aberration Correction in Postprocessing using Imaging Simulation
May 10, 2023



As the popularity of mobile photography continues to grow, considerable effort is being invested in the reconstruction of degraded images. Due to the spatial variation in optical aberrations, which cannot be avoided during the lens design process, recent commercial cameras have shifted some of these correction tasks from optical design to postprocessing systems. However, without engaging with the optical parameters, these systems only achieve limited correction for aberrations.In this work, we propose a practical method for recovering the degradation caused by optical aberrations. Specifically, we establish an imaging simulation system based on our proposed optical point spread function model. Given the optical parameters of the camera, it generates the imaging results of these specific devices. To perform the restoration, we design a spatial-adaptive network model on synthetic data pairs generated by the imaging simulation system, eliminating the overhead of capturing training data by a large amount of shooting and registration. Moreover, we comprehensively evaluate the proposed method in simulations and experimentally with a customized digital-single-lens-reflex (DSLR) camera lens and HUAWEI HONOR 20, respectively. The experiments demonstrate that our solution successfully removes spatially variant blur and color dispersion. When compared with the state-of-the-art deblur methods, the proposed approach achieves better results with a lower computational overhead. Moreover, the reconstruction technique does not introduce artificial texture and is convenient to transfer to current commercial cameras. Project Page: \url{https://github.com/TanGeeGo/ImagingSimulation}.
* Published in ACM TOG. 15 pages, 13 figures
Reliable Image Dehazing by NeRF
Mar 16, 2023We present an image dehazing algorithm with high quality, wide application, and no data training or prior needed. We analyze the defects of the original dehazing model, and propose a new and reliable dehazing reconstruction and dehazing model based on the combination of optical scattering model and computer graphics lighting rendering model. Based on the new haze model and the images obtained by the cameras, we can reconstruct the three-dimensional space, accurately calculate the objects and haze in the space, and use the transparency relationship of haze to perform accurate haze removal. To obtain a 3D simulation dataset we used the Unreal 5 computer graphics rendering engine. In order to obtain real shot data in different scenes, we used fog generators, array cameras, mobile phones, underwater cameras and drones to obtain haze data. We use formula derivation, simulation data set and real shot data set result experimental results to prove the feasibility of the new method. Compared with various other methods, we are far ahead in terms of calculation indicators (4 dB higher quality average scene), color remains more natural, and the algorithm is more robust in different scenarios and best in the subjective perception.
Towards Balanced Learning for Instance Recognition
Aug 23, 2021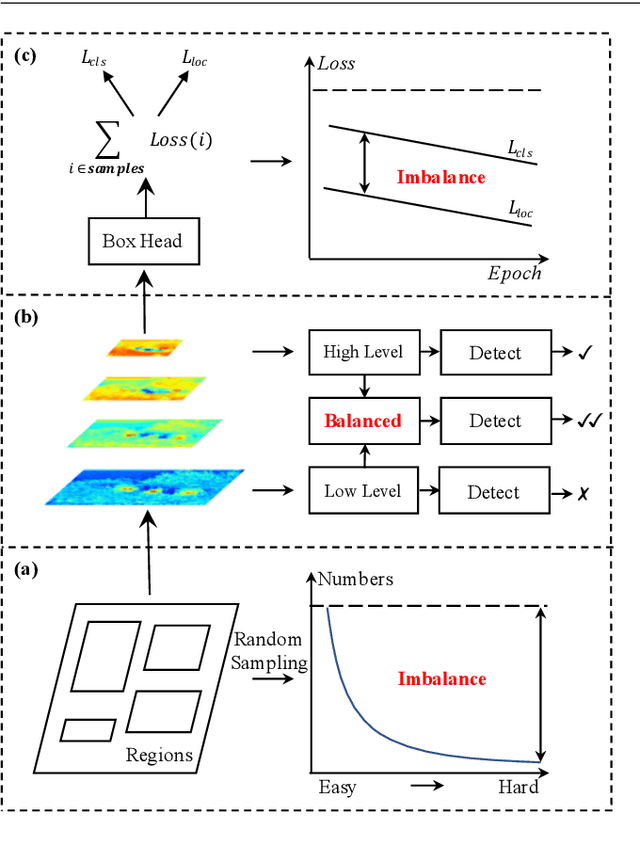
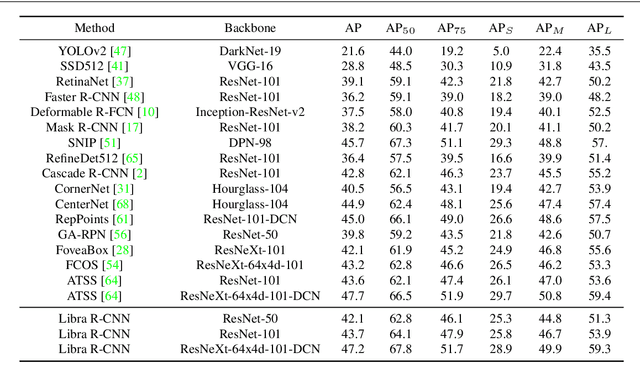
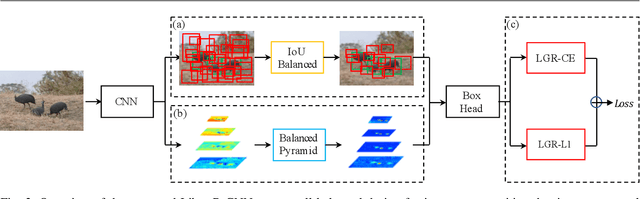
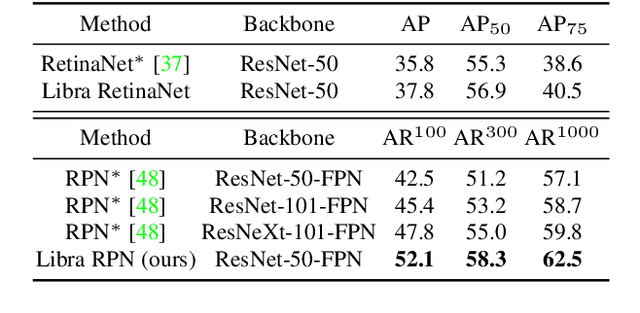
Instance recognition is rapidly advanced along with the developments of various deep convolutional neural networks. Compared to the architectures of networks, the training process, which is also crucial to the success of detectors, has received relatively less attention. In this work, we carefully revisit the standard training practice of detectors, and find that the detection performance is often limited by the imbalance during the training process, which generally consists in three levels - sample level, feature level, and objective level. To mitigate the adverse effects caused thereby, we propose Libra R-CNN, a simple yet effective framework towards balanced learning for instance recognition. It integrates IoU-balanced sampling, balanced feature pyramid, and objective re-weighting, respectively for reducing the imbalance at sample, feature, and objective level. Extensive experiments conducted on MS COCO, LVIS and Pascal VOC datasets prove the effectiveness of the overall balanced design.
Class agnostic moving target detection by color and location prediction of moving area
Jun 24, 2021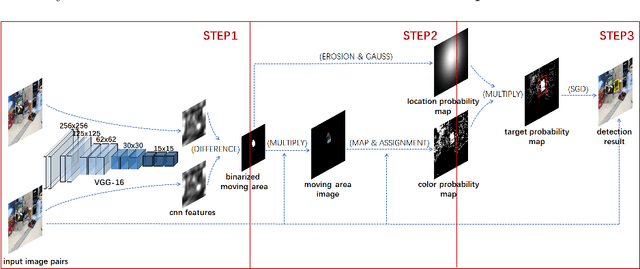
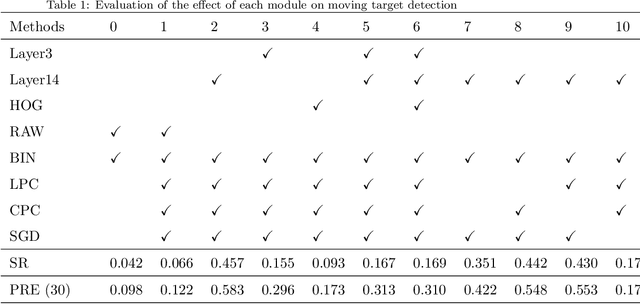
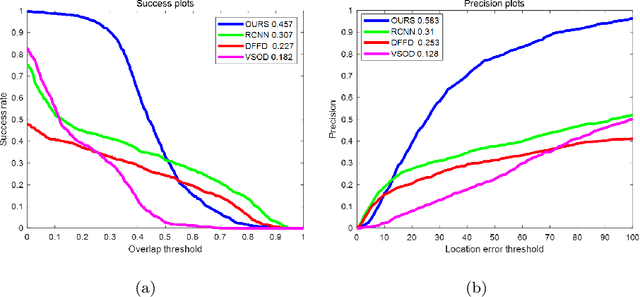

Moving target detection plays an important role in computer vision. However, traditional algorithms such as frame difference and optical flow usually suffer from low accuracy or heavy computation. Recent algorithms such as deep learning-based convolutional neural networks have achieved high accuracy and real-time performance, but they usually need to know the classes of targets in advance, which limits the practical applications. Therefore, we proposed a model free moving target detection algorithm. This algorithm extracts the moving area through the difference of image features. Then, the color and location probability map of the moving area will be calculated through maximum a posteriori probability. And the target probability map can be obtained through the dot multiply between the two maps. Finally, the optimal moving target area can be solved by stochastic gradient descent on the target probability map. Results show that the proposed algorithm achieves the highest accuracy compared with state-of-the-art algorithms, without needing to know the classes of targets. Furthermore, as the existing datasets are not suitable for moving target detection, we proposed a method for producing evaluation dataset. Besides, we also proved the proposed algorithm can be used to assist target tracking.
SRDiff: Single Image Super-Resolution with Diffusion Probabilistic Models
May 18, 2021
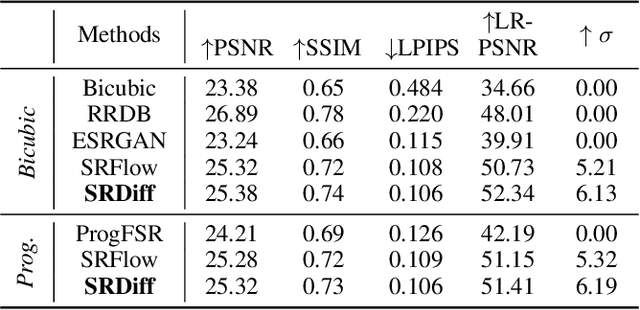
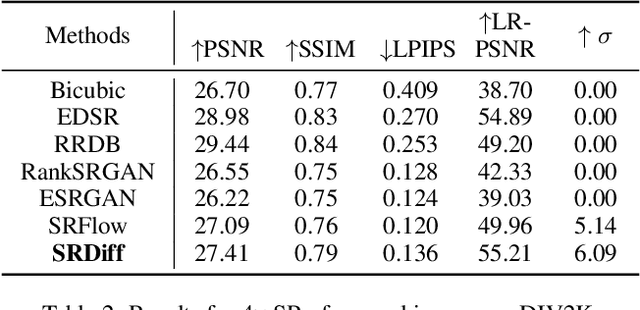
Single image super-resolution (SISR) aims to reconstruct high-resolution (HR) images from the given low-resolution (LR) ones, which is an ill-posed problem because one LR image corresponds to multiple HR images. Recently, learning-based SISR methods have greatly outperformed traditional ones, while suffering from over-smoothing, mode collapse or large model footprint issues for PSNR-oriented, GAN-driven and flow-based methods respectively. To solve these problems, we propose a novel single image super-resolution diffusion probabilistic model (SRDiff), which is the first diffusion-based model for SISR. SRDiff is optimized with a variant of the variational bound on the data likelihood and can provide diverse and realistic SR predictions by gradually transforming the Gaussian noise into a super-resolution (SR) image conditioned on an LR input through a Markov chain. In addition, we introduce residual prediction to the whole framework to speed up convergence. Our extensive experiments on facial and general benchmarks (CelebA and DIV2K datasets) show that 1) SRDiff can generate diverse SR results in rich details with state-of-the-art performance, given only one LR input; 2) SRDiff is easy to train with a small footprint; and 3) SRDiff can perform flexible image manipulation including latent space interpolation and content fusion.
Low-light Image Restoration with Short- and Long-exposure Raw Pairs
Jul 01, 2020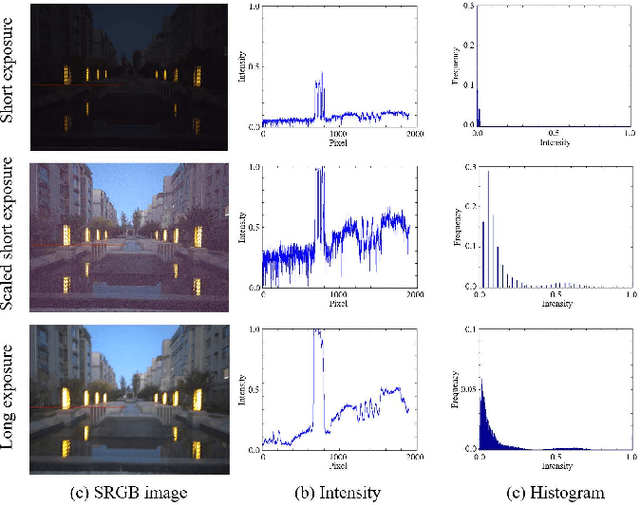



Low-light imaging with handheld mobile devices is a challenging issue. Limited by the existing models and training data, most existing methods cannot be effectively applied in real scenarios. In this paper, we propose a new low-light image restoration method by using the complementary information of short- and long-exposure images. We first propose a novel data generation method to synthesize realistic short- and longexposure raw images by simulating the imaging pipeline in lowlight environment. Then, we design a new long-short-exposure fusion network (LSFNet) to deal with the problems of low-light image fusion, including high noise, motion blur, color distortion and misalignment. The proposed LSFNet takes pairs of shortand long-exposure raw images as input, and outputs a clear RGB image. Using our data generation method and the proposed LSFNet, we can recover the details and color of the original scene, and improve the low-light image quality effectively. Experiments demonstrate that our method can outperform the state-of-the art methods.