 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning and the rate of approximation by flows
Mar 16, 2026We investigate the dependence of the approximation capacity of deep residual networks on its depth in a continuous dynamical systems setting. This can be formulated as the general problem of quantifying the minimal time-horizon required to approximate a diffeomorphism by flows driven by a given family $\mathcal F$ of vector fields. We show that this minimal time can be identified as a geodesic distance on a sub-Finsler manifold of diffeomorphisms, where the local geometry is characterised by a variational principle involving $\mathcal F$. This connects the learning efficiency of target relationships to their compatibility with the learning architectural choice. Further, the results suggest that the key approximation mechanism in deep learning, namely the approximation of functions by composition or dynamics, differs in a fundamental way from linear approximation theory, where linear spaces and norm-based rate estimates are replaced by manifolds and geodesic distances.
Lightweight Spatial Modeling for Combinatorial Information Extraction From Documents
May 08, 2024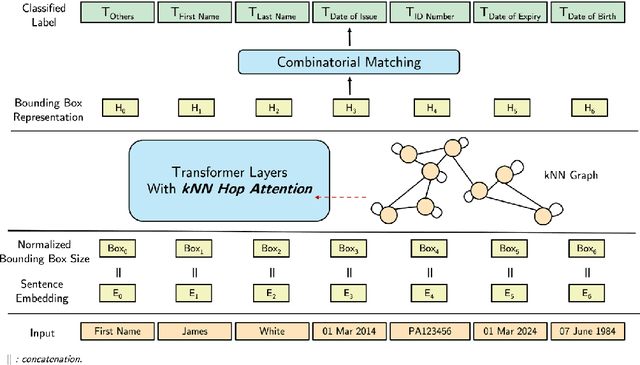



Documents that consist of diverse templates and exhibit complex spatial structures pose a challenge for document entity classification. We propose KNN-former, which incorporates a new kind of spatial bias in attention calculation based on the K-nearest-neighbor (KNN) graph of document entities. We limit entities' attention only to their local radius defined by the KNN graph. We also use combinatorial matching to address the one-to-one mapping property that exists in many documents, where one field has only one corresponding entity. Moreover, our method is highly parameter-efficient compared to existing approaches in terms of the number of trainable parameters. Despite this, experiments across various datasets show our method outperforms baselines in most entity types. Many real-world documents exhibit combinatorial properties which can be leveraged as inductive biases to improve extraction accuracy, but existing datasets do not cover these documents. To facilitate future research into these types of documents, we release a new ID document dataset that covers diverse templates and languages. We also release enhanced annotations for an existing dataset.
Interpolation, Approximation and Controllability of Deep Neural Networks
Sep 12, 2023We investigate the expressive power of deep residual neural networks idealized as continuous dynamical systems through control theory. Specifically, we consider two properties that arise from supervised learning, namely universal interpolation - the ability to match arbitrary input and target training samples - and the closely related notion of universal approximation - the ability to approximate input-target functional relationships via flow maps. Under the assumption of affine invariance of the control family, we give a characterisation of universal interpolation, showing that it holds for essentially any architecture with non-linearity. Furthermore, we elucidate the relationship between universal interpolation and universal approximation in the context of general control systems, showing that the two properties cannot be deduced from each other. At the same time, we identify conditions on the control family and the target function that ensures the equivalence of the two notions.
Computational Optics for Mobile Terminals in Mass Production
May 10, 2023



Correcting the optical aberrations and the manufacturing deviations of cameras is a challenging task. Due to the limitation on volume and the demand for mass production, existing mobile terminals cannot rectify optical degradation. In this work, we systematically construct the perturbed lens system model to illustrate the relationship between the deviated system parameters and the spatial frequency response measured from photographs. To further address this issue, an optimization framework is proposed based on this model to build proxy cameras from the machining samples' SFRs. Engaging with the proxy cameras, we synthetic data pairs, which encode the optical aberrations and the random manufacturing biases, for training the learning-based algorithms. In correcting aberration, although promising results have been shown recently with convolutional neural networks, they are hard to generalize to stochastic machining biases. Therefore, we propose a dilated Omni-dimensional dynamic convolution and implement it in post-processing to account for the manufacturing degradation. Extensive experiments which evaluate multiple samples of two representative devices demonstrate that the proposed optimization framework accurately constructs the proxy camera. And the dynamic processing model is well-adapted to manufacturing deviations of different cameras, realizing perfect computational photography. The evaluation shows that the proposed method bridges the gap between optical design, system machining, and post-processing pipeline, shedding light on the joint of image signal reception (lens and sensor) and image signal processing.
* Published in IEEE TPAMI, 15 pages, 13 figures
On the Universal Approximation Property of Deep Fully Convolutional Neural Networks
Nov 25, 2022
We study the approximation of shift-invariant or equivariant functions by deep fully convolutional networks from the dynamical systems perspective. We prove that deep residual fully convolutional networks and their continuous-layer counterpart can achieve universal approximation of these symmetric functions at constant channel width. Moreover, we show that the same can be achieved by non-residual variants with at least 2 channels in each layer and convolutional kernel size of at least 2. In addition, we show that these requirements are necessary, in the sense that networks with fewer channels or smaller kernels fail to be universal approximators.
Deep Neural Network Approximation of Invariant Functions through Dynamical Systems
Aug 18, 2022
We study the approximation of functions which are invariant with respect to certain permutations of the input indices using flow maps of dynamical systems. Such invariant functions includes the much studied translation-invariant ones involving image tasks, but also encompasses many permutation-invariant functions that finds emerging applications in science and engineering. We prove sufficient conditions for universal approximation of these functions by a controlled equivariant dynamical system, which can be viewed as a general abstraction of deep residual networks with symmetry constraints. These results not only imply the universal approximation for a variety of commonly employed neural network architectures for symmetric function approximation, but also guide the design of architectures with approximation guarantees for applications involving new symmetry requirements.
Aspect-based Sentiment Analysis through EDU-level Attentions
Feb 05, 2022
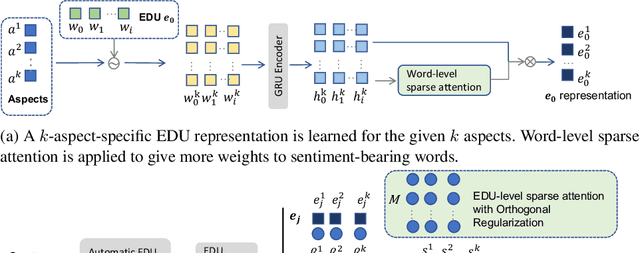
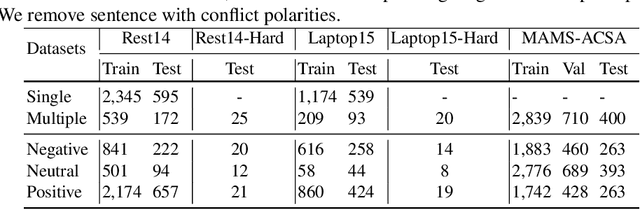

A sentence may express sentiments on multiple aspects. When these aspects are associated with different sentiment polarities, a model's accuracy is often adversely affected. We observe that multiple aspects in such hard sentences are mostly expressed through multiple clauses, or formally known as elementary discourse units (EDUs), and one EDU tends to express a single aspect with unitary sentiment towards that aspect. In this paper, we propose to consider EDU boundaries in sentence modeling, with attentions at both word and EDU levels. Specifically, we highlight sentiment-bearing words in EDU through word-level sparse attention. Then at EDU level, we force the model to attend to the right EDU for the right aspect, by using EDU-level sparse attention and orthogonal regularization. Experiments on three benchmark datasets show that our simple EDU-Attention model outperforms state-of-the-art baselines. Because EDU can be automatically segmented with high accuracy, our model can be applied to sentences directly without the need of manual EDU boundary annotation.
Deep Learning via Dynamical Systems: An Approximation Perspective
Dec 22, 2019We build on the dynamical systems approach to deep learning, where deep residual networks are idealized as continuous-time dynamical systems. Although theoretical foundations have been developed on the optimization side through mean-field optimal control theory, the function approximation properties of such models remain largely unexplored, especially when the dynamical systems are controlled by functions of low complexity. In this paper, we establish some basic results on the approximation capabilities of deep learning models in the form of dynamical systems. In particular, we derive general sufficient conditions for universal approximation of functions in $L^p$ using flow maps of dynamical systems, and we also deduce some results on their approximation rates for specific cases. Overall, these results reveal that composition function approximation through flow maps present a new paradigm in approximation theory and contributes to building a useful mathematical framework to investigate deep learning.