 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconsciously Forget: Mitigating Memorization; Without Knowing What is being Memorized
Dec 12, 2025Recent advances in generative models have demonstrated an exceptional ability to produce highly realistic images. However, previous studies show that generated images often resemble the training data, and this problem becomes more severe as the model size increases. Memorizing training data can lead to legal challenges, including copyright infringement, violations of portrait rights, and trademark violations. Existing approaches to mitigating memorization mainly focus on manipulating the denoising sampling process to steer image embeddings away from the memorized embedding space or employ unlearning methods that require training on datasets containing specific sets of memorized concepts. However, existing methods often incur substantial computational overhead during sampling, or focus narrowly on removing one or more groups of target concepts, imposing a significant limitation on their scalability. To understand and mitigate these problems, our work, UniForget, offers a new perspective on understanding the root cause of memorization. Our work demonstrates that specific parts of the model are responsible for copyrighted content generation. By applying model pruning, we can effectively suppress the probability of generating copyrighted content without targeting specific concepts while preserving the general generative capabilities of the model. Additionally, we show that our approach is both orthogonal and complementary to existing unlearning methods, thereby highlighting its potential to improve current unlearning and de-memorization techniques.
Effortless Efficiency: Low-Cost Pruning of Diffusion Models
Dec 03, 2024Diffusion models have achieved impressive advancements in various vision tasks. However, these gains often rely on increasing model size, which escalates computational complexity and memory demands, complicating deployment, raising inference costs, and causing environmental impact. While some studies have explored pruning techniques to improve the memory efficiency of diffusion models, most existing methods require extensive retraining to retain the model performance. Retraining a modern large diffusion model is extremely costly and resource-intensive, which limits the practicality of these methods. In this work, we achieve low-cost diffusion pruning without retraining by proposing a model-agnostic structural pruning framework for diffusion models that learns a differentiable mask to sparsify the model. To ensure effective pruning that preserves the quality of the final denoised latent, we design a novel end-to-end pruning objective that spans the entire diffusion process. As end-to-end pruning is memory-intensive, we further propose time step gradient checkpointing, a technique that significantly reduces memory usage during optimization, enabling end-to-end pruning within a limited memory budget. Results on state-of-the-art U-Net diffusion models SDXL and diffusion transformers (FLUX) demonstrate that our method can effectively prune up to 20% parameters with minimal perceptible performance degradation, and notably, without the need for model retraining. We also showcase that our method can still prune on top of time step distilled diffusion models.
Investigating Layer Importance in Large Language Models
Sep 22, 2024Large language models (LLMs) have gained increasing attention due to their prominent ability to understand and process texts. Nevertheless, LLMs largely remain opaque. The lack of understanding of LLMs has obstructed the deployment in safety-critical scenarios and hindered the development of better models. In this study, we advance the understanding of LLM by investigating the significance of individual layers in LLMs. We propose an efficient sampling method to faithfully evaluate the importance of layers using Shapley values, a widely used explanation framework in feature attribution and data valuation. In addition, we conduct layer ablation experiments to assess the performance degradation resulting from the exclusion of specific layers. Our findings reveal the existence of cornerstone layers, wherein certain early layers can exhibit a dominant contribution over others. Removing one cornerstone layer leads to a drastic collapse of the model performance, often reducing it to random guessing. Conversely, removing non-cornerstone layers results in only marginal performance changes. This study identifies cornerstone layers in LLMs and underscores their critical role for future research.
Hierarchical Neural Constructive Solver for Real-world TSP Scenarios
Aug 07, 2024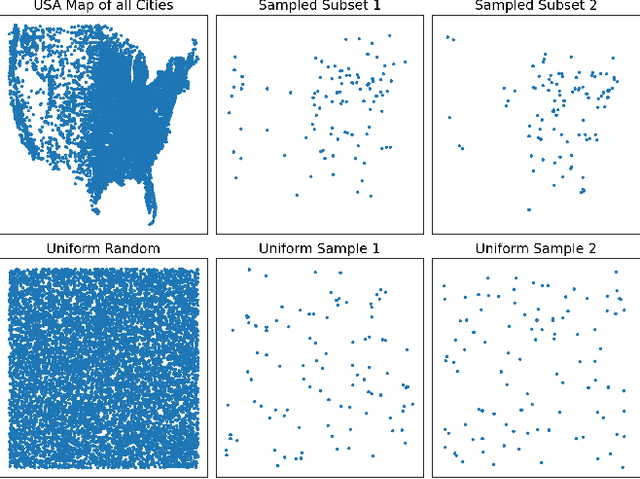
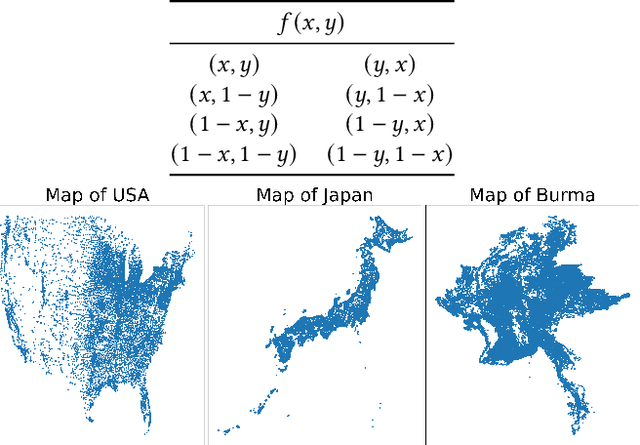
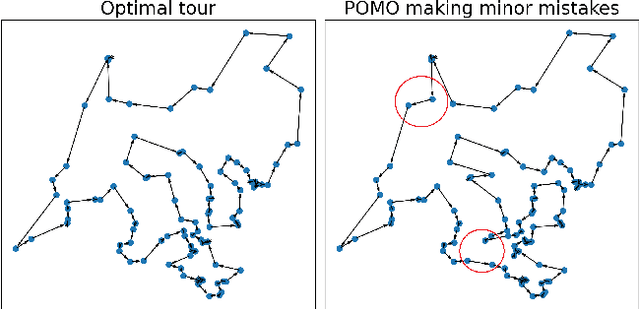
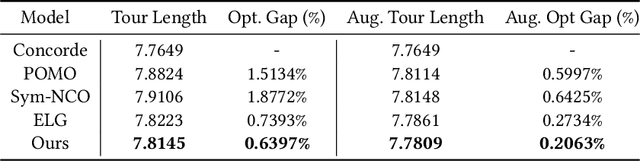
Existing neural constructive solvers for routing problems have predominantly employed transformer architectures, conceptualizing the route construction as a set-to-sequence learning task. However, their efficacy has primarily been demonstrated on entirely random problem instances that inadequately capture real-world scenarios. In this paper, we introduce realistic Traveling Salesman Problem (TSP) scenarios relevant to industrial settings and derive the following insights: (1) The optimal next node (or city) to visit often lies within proximity to the current node, suggesting the potential benefits of biasing choices based on current locations. (2) Effectively solving the TSP requires robust tracking of unvisited nodes and warrants succinct grouping strategies. Building upon these insights, we propose integrating a learnable choice layer inspired by Hypernetworks to prioritize choices based on the current location, and a learnable approximate clustering algorithm inspired by the Expectation-Maximization algorithm to facilitate grouping the unvisited cities. Together, these two contributions form a hierarchical approach towards solving the realistic TSP by considering both immediate local neighbourhoods and learning an intermediate set of node representations. Our hierarchical approach yields superior performance compared to both classical and recent transformer models, showcasing the efficacy of the key designs.
Differentiable Cluster Graph Neural Network
May 25, 2024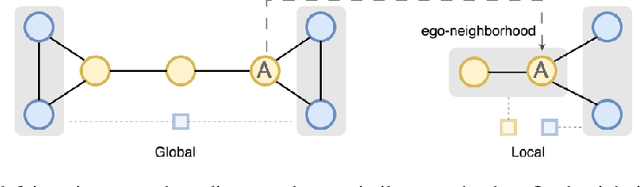



Graph Neural Networks often struggle with long-range information propagation and in the presence of heterophilous neighborhoods. We address both challenges with a unified framework that incorporates a clustering inductive bias into the message passing mechanism, using additional cluster-nodes. Central to our approach is the formulation of an optimal transport based implicit clustering objective function. However, the algorithm for solving the implicit objective function needs to be differentiable to enable end-to-end learning of the GNN. To facilitate this, we adopt an entropy regularized objective function and propose an iterative optimization process, alternating between solving for the cluster assignments and updating the node/cluster-node embeddings. Notably, our derived closed-form optimization steps are themselves simple yet elegant message passing steps operating seamlessly on a bipartite graph of nodes and cluster-nodes. Our clustering-based approach can effectively capture both local and global information, demonstrated by extensive experiments on both heterophilous and homophilous datasets.
Enabling Roll-up and Drill-down Operations in News Exploration with Knowledge Graphs for Due Diligence and Risk Management
May 08, 2024

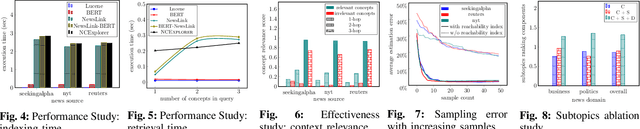

Efficient news exploration is crucial in real-world applications, particularly within the financial sector, where numerous control and risk assessment tasks rely on the analysis of public news reports. The current processes in this domain predominantly rely on manual efforts, often involving keywordbased searches and the compilation of extensive keyword lists. In this paper, we introduce NCEXPLORER, a framework designed with OLAP-like operations to enhance the news exploration experience. NCEXPLORER empowers users to use roll-up operations for a broader content overview and drill-down operations for detailed insights. These operations are achieved through integration with external knowledge graphs (KGs), encompassing both fact-based and ontology-based structures. This integration significantly augments exploration capabilities, offering a more comprehensive and efficient approach to unveiling the underlying structures and nuances embedded in news content. Extensive empirical studies through master-qualified evaluators on Amazon Mechanical Turk demonstrate NCEXPLORER's superiority over existing state-of-the-art news search methodologies across an array of topic domains, using real-world news datasets.
Lightweight Spatial Modeling for Combinatorial Information Extraction From Documents
May 08, 2024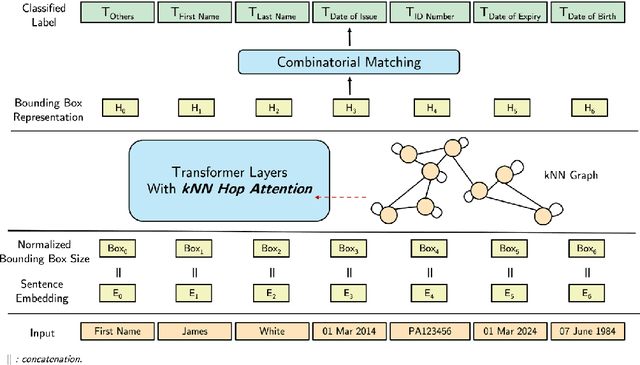



Documents that consist of diverse templates and exhibit complex spatial structures pose a challenge for document entity classification. We propose KNN-former, which incorporates a new kind of spatial bias in attention calculation based on the K-nearest-neighbor (KNN) graph of document entities. We limit entities' attention only to their local radius defined by the KNN graph. We also use combinatorial matching to address the one-to-one mapping property that exists in many documents, where one field has only one corresponding entity. Moreover, our method is highly parameter-efficient compared to existing approaches in terms of the number of trainable parameters. Despite this, experiments across various datasets show our method outperforms baselines in most entity types. Many real-world documents exhibit combinatorial properties which can be leveraged as inductive biases to improve extraction accuracy, but existing datasets do not cover these documents. To facilitate future research into these types of documents, we release a new ID document dataset that covers diverse templates and languages. We also release enhanced annotations for an existing dataset.
Constrained Layout Generation with Factor Graphs
Mar 30, 2024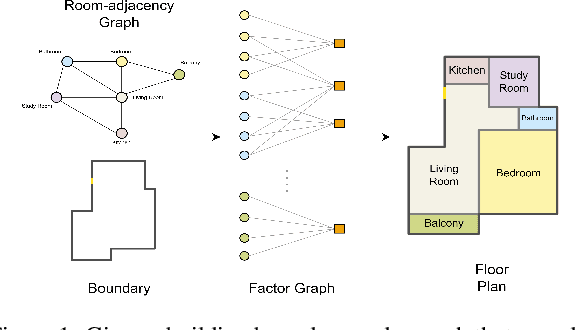

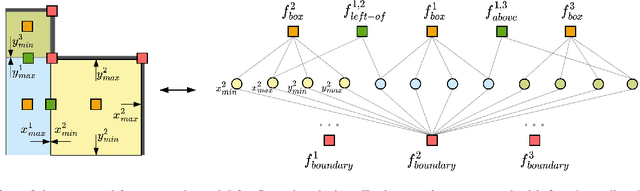
This paper addresses the challenge of object-centric layout generation under spatial constraints, seen in multiple domains including floorplan design process. The design process typically involves specifying a set of spatial constraints that include object attributes like size and inter-object relations such as relative positioning. Existing works, which typically represent objects as single nodes, lack the granularity to accurately model complex interactions between objects. For instance, often only certain parts of an object, like a room's right wall, interact with adjacent objects. To address this gap, we introduce a factor graph based approach with four latent variable nodes for each room, and a factor node for each constraint. The factor nodes represent dependencies among the variables to which they are connected, effectively capturing constraints that are potentially of a higher order. We then develop message-passing on the bipartite graph, forming a factor graph neural network that is trained to produce a floorplan that aligns with the desired requirements. Our approach is simple and generates layouts faithful to the user requirements, demonstrated by a large improvement in IOU scores over existing methods. Additionally, our approach, being inferential and accurate, is well-suited to the practical human-in-the-loop design process where specifications evolve iteratively, offering a practical and powerful tool for AI-guided design.
PF-GNN: Differentiable particle filtering based approximation of universal graph representations
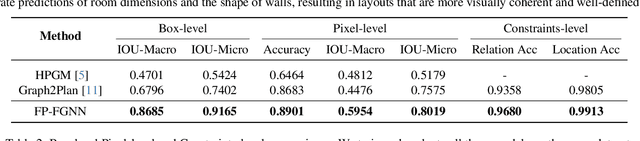
Jan 31, 2024Message passing Graph Neural Networks (GNNs) are known to be limited in expressive power by the 1-WL color-refinement test for graph isomorphism. Other more expressive models either are computationally expensive or need preprocessing to extract structural features from the graph. In this work, we propose to make GNNs universal by guiding the learning process with exact isomorphism solver techniques which operate on the paradigm of Individualization and Refinement (IR), a method to artificially introduce asymmetry and further refine the coloring when 1-WL stops. Isomorphism solvers generate a search tree of colorings whose leaves uniquely identify the graph. However, the tree grows exponentially large and needs hand-crafted pruning techniques which are not desirable from a learning perspective. We take a probabilistic view and approximate the search tree of colorings (i.e. embeddings) by sampling multiple paths from root to leaves of the search tree. To learn more discriminative representations, we guide the sampling process with particle filter updates, a principled approach for sequential state estimation. Our algorithm is end-to-end differentiable, can be applied with any GNN as backbone and learns richer graph representations with only linear increase in runtime. Experimental evaluation shows that our approach consistently outperforms leading GNN models on both synthetic benchmarks for isomorphism detection as well as real-world datasets.
Web News Timeline Generation with Extended Task Prompting
Nov 20, 2023


The creation of news timeline is essential for a comprehensive and contextual understanding of events as they unfold over time. This approach aids in discerning patterns and trends that might be obscured when news is viewed in isolation. By organizing news in a chronological sequence, it becomes easier to track the development of stories, understand the interrelation of events, and grasp the broader implications of news items. This is particularly helpful in sectors like finance and insurance, where timely understanding of the event development-ranging from extreme weather to political upheavals and health crises-is indispensable for effective risk management. While traditional natural language processing (NLP) techniques have had some success, they often fail to capture the news with nuanced relevance that are readily apparent to domain experts, hindering broader industry integration. The advance of Large Language Models (LLMs) offers a renewed opportunity to tackle this challenge. However, direct prompting LLMs for this task is often ineffective. Our study investigates the application of an extended task prompting technique to assess past news relevance. We demonstrate that enhancing conventional prompts with additional tasks boosts their effectiveness on various news dataset, rendering news timeline generation practical for professional use. This work has been deployed as a publicly accessible browser extension which is adopted within our network.