 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration by Random Reward Perturbation
Jun 10, 2025We introduce Random Reward Perturbation (RRP), a novel exploration strategy for reinforcement learning (RL). Our theoretical analyses demonstrate that adding zero-mean noise to environmental rewards effectively enhances policy diversity during training, thereby expanding the range of exploration. RRP is fully compatible with the action-perturbation-based exploration strategies, such as $\epsilon$-greedy, stochastic policies, and entropy regularization, providing additive improvements to exploration effects. It is general, lightweight, and can be integrated into existing RL algorithms with minimal implementation effort and negligible computational overhead. RRP establishes a theoretical connection between reward shaping and noise-driven exploration, highlighting their complementary potential. Experiments show that RRP significantly boosts the performance of Proximal Policy Optimization and Soft Actor-Critic, achieving higher sample efficiency and escaping local optima across various tasks, under both sparse and dense reward scenarios.
Approximation and Generalization Abilities of Score-based Neural Network Generative Models for Sub-Gaussian Distributions
May 16, 2025This paper studies the approximation and generalization abilities of score-based neural network generative models (SGMs) in estimating an unknown distribution $P_0$ from $n$ i.i.d. observations in $d$ dimensions. Assuming merely that $P_0$ is $\alpha$-sub-Gaussian, we prove that for any time step $t \in [t_0, n^{O(1)}]$, where $t_0 \geq O(\alpha^2n^{-2/d}\log n)$, there exists a deep ReLU neural network with width $\leq O(\log^3n)$ and depth $\leq O(n^{3/d}\log_2n)$ that can approximate the scores with $\tilde{O}(n^{-1})$ mean square error and achieve a nearly optimal rate of $\tilde{O}(n^{-1}t_0^{-d/2})$ for score estimation, as measured by the score matching loss. Our framework is universal and can be used to establish convergence rates for SGMs under milder assumptions than previous work. For example, assuming further that the target density function $p_0$ lies in Sobolev or Besov classes, with an appropriately early stopping strategy, we demonstrate that neural network-based SGMs can attain nearly minimax convergence rates up to logarithmic factors. Our analysis removes several crucial assumptions, such as Lipschitz continuity of the score function or a strictly positive lower bound on the target density.
Constrained Layout Generation with Factor Graphs
Mar 30, 2024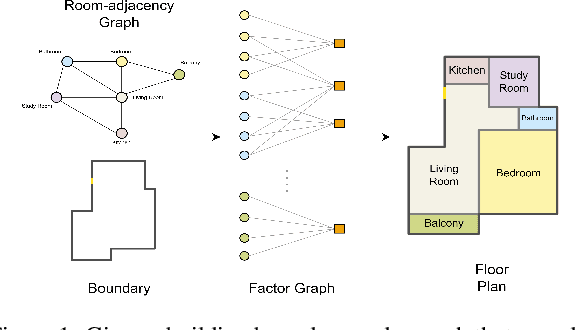

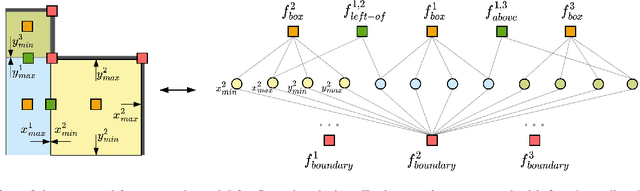
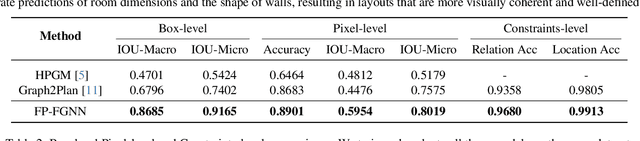
This paper addresses the challenge of object-centric layout generation under spatial constraints, seen in multiple domains including floorplan design process. The design process typically involves specifying a set of spatial constraints that include object attributes like size and inter-object relations such as relative positioning. Existing works, which typically represent objects as single nodes, lack the granularity to accurately model complex interactions between objects. For instance, often only certain parts of an object, like a room's right wall, interact with adjacent objects. To address this gap, we introduce a factor graph based approach with four latent variable nodes for each room, and a factor node for each constraint. The factor nodes represent dependencies among the variables to which they are connected, effectively capturing constraints that are potentially of a higher order. We then develop message-passing on the bipartite graph, forming a factor graph neural network that is trained to produce a floorplan that aligns with the desired requirements. Our approach is simple and generates layouts faithful to the user requirements, demonstrated by a large improvement in IOU scores over existing methods. Additionally, our approach, being inferential and accurate, is well-suited to the practical human-in-the-loop design process where specifications evolve iteratively, offering a practical and powerful tool for AI-guided design.
Implicit Graph Neural Diffusion Based on Constrained Dirichlet Energy Minimization
Aug 07, 2023Implicit graph neural networks (GNNs) have emerged as a potential approach to enable GNNs to capture long-range dependencies effectively. However, poorly designed implicit GNN layers can experience over-smoothing or may have limited adaptability to learn data geometry, potentially hindering their performance in graph learning problems. To address these issues, we introduce a geometric framework to design implicit graph diffusion layers based on a parameterized graph Laplacian operator. Our framework allows learning the geometry of vertex and edge spaces, as well as the graph gradient operator from data. We further show how implicit GNN layers can be viewed as the fixed-point solution of a Dirichlet energy minimization problem and give conditions under which it may suffer from over-smoothing. To overcome the over-smoothing problem, we design our implicit graph diffusion layer as the solution of a Dirichlet energy minimization problem with constraints on vertex features, enabling it to trade off smoothing with the preservation of node feature information. With an appropriate hyperparameter set to be larger than the largest eigenvalue of the parameterized graph Laplacian, our framework guarantees a unique equilibrium and quick convergence. Our models demonstrate better performance than leading implicit and explicit GNNs on benchmark datasets for node and graph classification tasks, with substantial accuracy improvements observed for some datasets.
Fairness-aware Message Passing for Graph Neural Networks
Jun 19, 2023Graph Neural Networks (GNNs) have shown great power in various domains. However, their predictions may inherit societal biases on sensitive attributes, limiting their adoption in real-world applications. Although many efforts have been taken for fair GNNs, most existing works just adopt widely used fairness techniques in machine learning to graph domains and ignore or don't have a thorough understanding of the message passing mechanism with fairness constraints, which is a distinctive feature of GNNs. To fill the gap, we propose a novel fairness-aware message passing framework GMMD, which is derived from an optimization problem that considers both graph smoothness and representation fairness. GMMD can be intuitively interpreted as encouraging a node to aggregate representations of other nodes from different sensitive groups while subtracting representations of other nodes from the same sensitive group, resulting in fair representations. We also provide a theoretical analysis to justify that GMMD can guarantee fairness, which leads to a simpler and theory-guided variant GMMD-S. Extensive experiments on graph benchmarks show that our proposed framework can significantly improve the fairness of various backbone GNN models while maintaining high accuracy.
SyNDock: N Rigid Protein Docking via Learnable Group Synchronization
May 25, 2023The regulation of various cellular processes heavily relies on the protein complexes within a living cell, necessitating a comprehensive understanding of their three-dimensional structures to elucidate the underlying mechanisms. While neural docking techniques have exhibited promising outcomes in binary protein docking, the application of advanced neural architectures to multimeric protein docking remains uncertain. This study introduces SyNDock, an automated framework that swiftly assembles precise multimeric complexes within seconds, showcasing performance that can potentially surpass or be on par with recent advanced approaches. SyNDock possesses several appealing advantages not present in previous approaches. Firstly, SyNDock formulates multimeric protein docking as a problem of learning global transformations to holistically depict the placement of chain units of a complex, enabling a learning-centric solution. Secondly, SyNDock proposes a trainable two-step SE(3) algorithm, involving initial pairwise transformation and confidence estimation, followed by global transformation synchronization. This enables effective learning for assembling the complex in a globally consistent manner. Lastly, extensive experiments conducted on our proposed benchmark dataset demonstrate that SyNDock outperforms existing docking software in crucial performance metrics, including accuracy and runtime. For instance, it achieves a 4.5% improvement in performance and a remarkable millionfold acceleration in speed.
A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection
May 23, 2022



Deep graph learning has achieved remarkable progresses in both business and scientific areas ranging from finance and e-commerce, to drug and advanced material discovery. Despite these progresses, how to ensure various deep graph learning algorithms behave in a socially responsible manner and meet regulatory compliance requirements becomes an emerging problem, especially in risk-sensitive domains. Trustworthy graph learning (TwGL) aims to solve the above problems from a technical viewpoint. In contrast to conventional graph learning research which mainly cares about model performance, TwGL considers various reliability and safety aspects of the graph learning framework including but not limited to robustness, explainability, and privacy. In this survey, we provide a comprehensive review of recent leading approaches in the TwGL field from three dimensions, namely, reliability, explainability, and privacy protection. We give a general categorization for existing work and review typical work for each category. To give further insights for TwGL research, we provide a unified view to inspect previous works and build the connection between them. We also point out some important open problems remaining to be solved in the future developments of TwGL.
Understanding Knowledge Integration in Language Models with Graph Convolutions
Feb 15, 2022



Pretrained language models (LMs) do not capture factual knowledge very well. This has led to the development of a number of knowledge integration (KI) methods which aim to incorporate external knowledge into pretrained LMs. Even though KI methods show some performance gains over vanilla LMs, the inner-workings of these methods are not well-understood. For instance, it is unclear how and what kind of knowledge is effectively integrated into these models and if such integration may lead to catastrophic forgetting of already learned knowledge. This paper revisits the KI process in these models with an information-theoretic view and shows that KI can be interpreted using a graph convolution operation. We propose a probe model called \textit{Graph Convolution Simulator} (GCS) for interpreting knowledge-enhanced LMs and exposing what kind of knowledge is integrated into these models. We conduct experiments to verify that our GCS can indeed be used to correctly interpret the KI process, and we use it to analyze two well-known knowledge-enhanced LMs: ERNIE and K-Adapter, and find that only a small amount of factual knowledge is integrated in them. We stratify knowledge in terms of various relation types and find that ERNIE and K-Adapter integrate different kinds of knowledge to different extent. Our analysis also shows that simply increasing the size of the KI corpus may not lead to better KI; fundamental advances may be needed.
Recent Advances in Reliable Deep Graph Learning: Adversarial Attack, Inherent Noise, and Distribution Shift
Feb 15, 2022


Deep graph learning (DGL) has achieved remarkable progress in both business and scientific areas ranging from finance and e-commerce to drug and advanced material discovery. Despite the progress, applying DGL to real-world applications faces a series of reliability threats including adversarial attacks, inherent noise, and distribution shift. This survey aims to provide a comprehensive review of recent advances for improving the reliability of DGL algorithms against the above threats. In contrast to prior related surveys which mainly focus on adversarial attacks and defense, our survey covers more reliability-related aspects of DGL, i.e., inherent noise and distribution shift. Additionally, we discuss the relationships among above aspects and highlight some important issues to be explored in future research.
$p$-Laplacian Based Graph Neural Networks
Nov 14, 2021
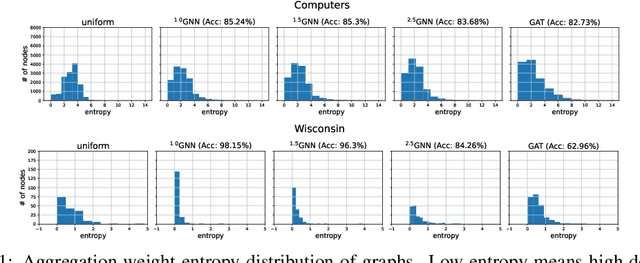
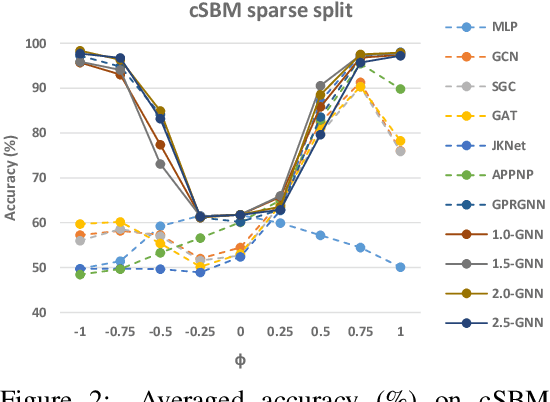

Graph neural networks (GNNs) have demonstrated superior performance for semi-supervised node classification on graphs, as a result of their ability to exploit node features and topological information simultaneously. However, most GNNs implicitly assume that the labels of nodes and their neighbors in a graph are the same or consistent, which does not hold in heterophilic graphs, where the labels of linked nodes are likely to differ. Hence, when the topology is non-informative for label prediction, ordinary GNNs may work significantly worse than simply applying multi-layer perceptrons (MLPs) on each node. To tackle the above problem, we propose a new $p$-Laplacian based GNN model, termed as $^p$GNN, whose message passing mechanism is derived from a discrete regularization framework and could be theoretically explained as an approximation of a polynomial graph filter defined on the spectral domain of $p$-Laplacians. The spectral analysis shows that the new message passing mechanism works simultaneously as low-pass and high-pass filters, thus making $^p$GNNs are effective on both homophilic and heterophilic graphs. Empirical studies on real-world and synthetic datasets validate our findings and demonstrate that $^p$GNNs significantly outperform several state-of-the-art GNN architectures on heterophilic benchmarks while achieving competitive performance on homophilic benchmarks. Moreover, $^p$GNNs can adaptively learn aggregation weights and are robust to noisy edges.