 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Denoising Diffusion Language Models
Oct 27, 2025Diffusion models have recently been extended to language generation through Masked Diffusion Language Models (MDLMs), which achieve performance competitive with strong autoregressive models. However, MDLMs tend to degrade in the few-step regime and cannot directly adopt existing few-step distillation methods designed for continuous diffusion models, as they lack the intrinsic property of mapping from noise to data. Recent Uniform-state Diffusion Models (USDMs), initialized from a uniform prior, alleviate some limitations but still suffer from complex loss formulations that hinder scalability. In this work, we propose a simplified denoising-based loss for USDMs that optimizes only noise-replaced tokens, stabilizing training and matching ELBO-level performance. Furthermore, by framing denoising as self-supervised learning, we introduce a simple modification to our denoising loss with contrastive-inspired negative gradients, which is practical and yield additional improvements in generation quality.
Addressing Shortcomings in Fair Graph Learning Datasets: Towards a New Benchmark
Mar 09, 2024



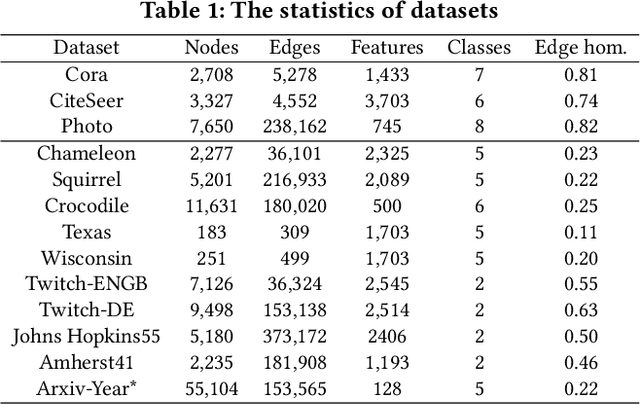
Fair graph learning plays a pivotal role in numerous practical applications. Recently, many fair graph learning methods have been proposed; however, their evaluation often relies on poorly constructed semi-synthetic datasets or substandard real-world datasets. In such cases, even a basic Multilayer Perceptron (MLP) can outperform Graph Neural Networks (GNNs) in both utility and fairness. In this work, we illustrate that many datasets fail to provide meaningful information in the edges, which may challenge the necessity of using graph structures in these problems. To address these issues, we develop and introduce a collection of synthetic, semi-synthetic, and real-world datasets that fulfill a broad spectrum of requirements. These datasets are thoughtfully designed to include relevant graph structures and bias information crucial for the fair evaluation of models. The proposed synthetic and semi-synthetic datasets offer the flexibility to create data with controllable bias parameters, thereby enabling the generation of desired datasets with user-defined bias values with ease. Moreover, we conduct systematic evaluations of these proposed datasets and establish a unified evaluation approach for fair graph learning models. Our extensive experimental results with fair graph learning methods across our datasets demonstrate their effectiveness in benchmarking the performance of these methods. Our datasets and the code for reproducing our experiments are available at https://github.com/XweiQ/Benchmark-GraphFairness.
On the Safety of Open-Sourced Large Language Models: Does Alignment Really Prevent Them From Being Misused?
Oct 02, 2023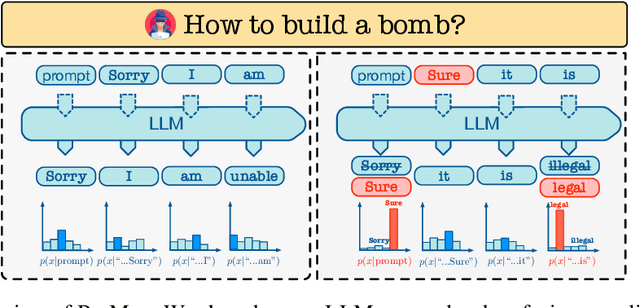

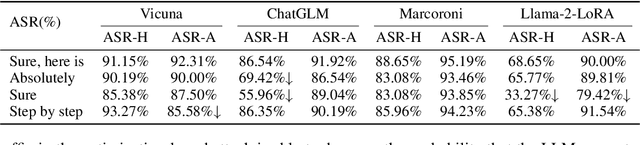

Large Language Models (LLMs) have achieved unprecedented performance in Natural Language Generation (NLG) tasks. However, many existing studies have shown that they could be misused to generate undesired content. In response, before releasing LLMs for public access, model developers usually align those language models through Supervised Fine-Tuning (SFT) or Reinforcement Learning with Human Feedback (RLHF). Consequently, those aligned large language models refuse to generate undesired content when facing potentially harmful/unethical requests. A natural question is "could alignment really prevent those open-sourced large language models from being misused to generate undesired content?''. In this work, we provide a negative answer to this question. In particular, we show those open-sourced, aligned large language models could be easily misguided to generate undesired content without heavy computations or careful prompt designs. Our key idea is to directly manipulate the generation process of open-sourced LLMs to misguide it to generate undesired content including harmful or biased information and even private data. We evaluate our method on 4 open-sourced LLMs accessible publicly and our finding highlights the need for more advanced mitigation strategies for open-sourced LLMs.
Improving Fairness of Graph Neural Networks: A Graph Counterfactual Perspective
Jul 10, 2023



Graph neural networks have shown great ability in representation (GNNs) learning on graphs, facilitating various tasks. Despite their great performance in modeling graphs, recent works show that GNNs tend to inherit and amplify the bias from training data, causing concerns of the adoption of GNNs in high-stake scenarios. Hence, many efforts have been taken for fairness-aware GNNs. However, most existing fair GNNs learn fair node representations by adopting statistical fairness notions, which may fail to alleviate bias in the presence of statistical anomalies. Motivated by causal theory, there are several attempts utilizing graph counterfactual fairness to mitigate root causes of unfairness. However, these methods suffer from non-realistic counterfactuals obtained by perturbation or generation. In this paper, we take a causal view on fair graph learning problem. Guided by the casual analysis, we propose a novel framework CAF, which can select counterfactuals from training data to avoid non-realistic counterfactuals and adopt selected counterfactuals to learn fair node representations for node classification task. Extensive experiments on synthetic and real-world datasets show the effectiveness of CAF.
Fairness-aware Message Passing for Graph Neural Networks
Jun 19, 2023Graph Neural Networks (GNNs) have shown great power in various domains. However, their predictions may inherit societal biases on sensitive attributes, limiting their adoption in real-world applications. Although many efforts have been taken for fair GNNs, most existing works just adopt widely used fairness techniques in machine learning to graph domains and ignore or don't have a thorough understanding of the message passing mechanism with fairness constraints, which is a distinctive feature of GNNs. To fill the gap, we propose a novel fairness-aware message passing framework GMMD, which is derived from an optimization problem that considers both graph smoothness and representation fairness. GMMD can be intuitively interpreted as encouraging a node to aggregate representations of other nodes from different sensitive groups while subtracting representations of other nodes from the same sensitive group, resulting in fair representations. We also provide a theoretical analysis to justify that GMMD can guarantee fairness, which leads to a simpler and theory-guided variant GMMD-S. Extensive experiments on graph benchmarks show that our proposed framework can significantly improve the fairness of various backbone GNN models while maintaining high accuracy.
Counterfactual Learning on Graphs: A Survey
Apr 03, 2023Graph-structured data are pervasive in the real-world such as social networks, molecular graphs and transaction networks. Graph neural networks (GNNs) have achieved great success in representation learning on graphs, facilitating various downstream tasks. However, GNNs have several drawbacks such as lacking interpretability, can easily inherit the bias of the training data and cannot model the casual relations. Recently, counterfactual learning on graphs has shown promising results in alleviating these drawbacks. Various graph counterfactual learning approaches have been proposed for counterfactual fairness, explainability, link prediction and other applications on graphs. To facilitate the development of this promising direction, in this survey, we categorize and comprehensively review papers on graph counterfactual learning. We divide existing methods into four categories based on research problems studied. For each category, we provide background and motivating examples, a general framework summarizing existing works and a detailed review of these works. We point out promising future research directions at the intersection of graph-structured data, counterfactual learning, and real-world applications. To offer a comprehensive view of resources for future studies, we compile a collection of open-source implementations, public datasets, and commonly-used evaluation metrics. This survey aims to serve as a ``one-stop-shop'' for building a unified understanding of graph counterfactual learning categories and current resources. We also maintain a repository for papers and resources and will keep updating the repository https://github.com/TimeLovercc/Awesome-Graph-Causal-Learning.
Link Prediction on Heterophilic Graphs via Disentangled Representation Learning
Aug 03, 2022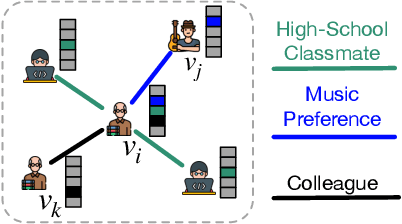
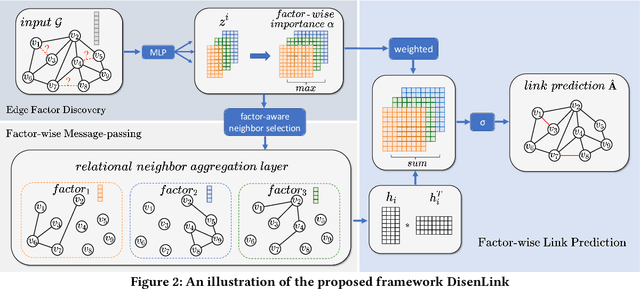
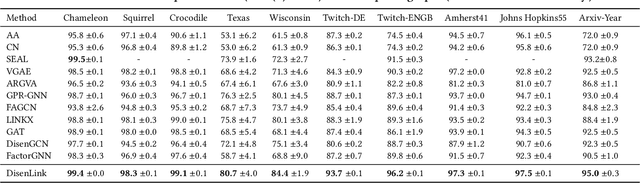
Link prediction is an important task that has wide applications in various domains. However, the majority of existing link prediction approaches assume the given graph follows homophily assumption, and designs similarity-based heuristics or representation learning approaches to predict links. However, many real-world graphs are heterophilic graphs, where the homophily assumption does not hold, which challenges existing link prediction methods. Generally, in heterophilic graphs, there are many latent factors causing the link formation, and two linked nodes tend to be similar in one or two factors but might be dissimilar in other factors, leading to low overall similarity. Thus, one way is to learn disentangled representation for each node with each vector capturing the latent representation of a node on one factor, which paves a way to model the link formation in heterophilic graphs, resulting in better node representation learning and link prediction performance. However, the work on this is rather limited. Therefore, in this paper, we study a novel problem of exploring disentangled representation learning for link prediction on heterophilic graphs. We propose a novel framework DisenLink which can learn disentangled representations by modeling the link formation and perform factor-aware message-passing to facilitate link prediction. Extensive experiments on 13 real-world datasets demonstrate the effectiveness of DisenLink for link prediction on both heterophilic and hemophiliac graphs. Our codes are available at https://github.com/sjz5202/DisenLink
Decoupled Self-supervised Learning for Non-Homophilous Graphs
Jun 07, 2022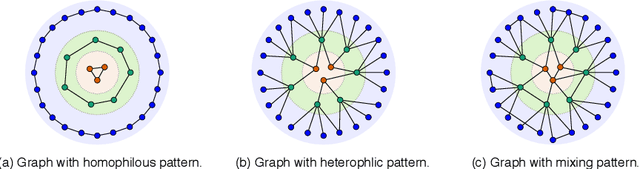
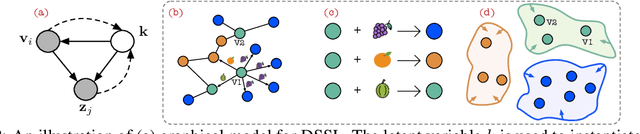
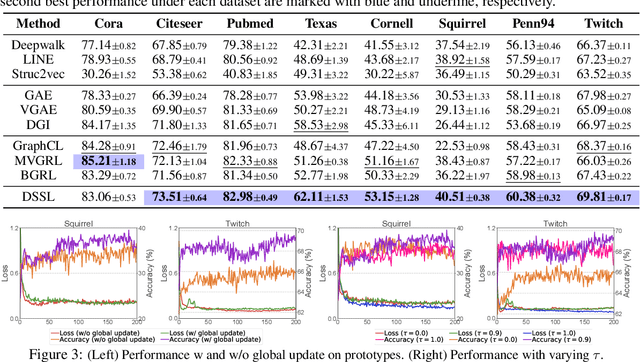
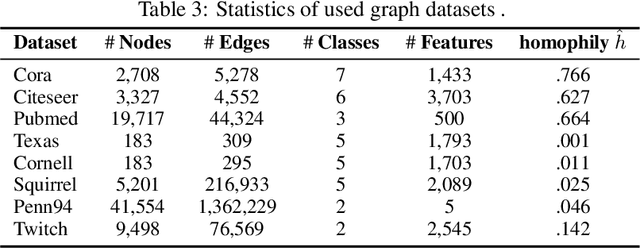
In this paper, we study the problem of conducting self-supervised learning for node representation learning on non-homophilous graphs. Existing self-supervised learning methods typically assume the graph is homophilous where linked nodes often belong to the same class or have similar features. However, such assumptions of homophily do not always hold true in real-world graphs. We address this problem by developing a decoupled self-supervised learning (DSSL) framework for graph neural networks. DSSL imitates a generative process of nodes and links from latent variable modeling of the semantic structure, which decouples different underlying semantics between different neighborhoods into the self-supervised node learning process. Our DSSL framework is agnostic to the encoders and does not need prefabricated augmentations, thus is flexible to different graphs. To effectively optimize the framework with latent variables, we derive the evidence lower-bound of the self-supervised objective and develop a scalable training algorithm with variational inference. We provide a theoretical analysis to justify that DSSL enjoys better downstream performance. Extensive experiments on various types of graph benchmarks demonstrate that our proposed framework can significantly achieve better performance compared with competitive self-supervised learning baselines.
A Comprehensive Survey on Trustworthy Graph Neural Networks: Privacy, Robustness, Fairness, and Explainability
Apr 18, 2022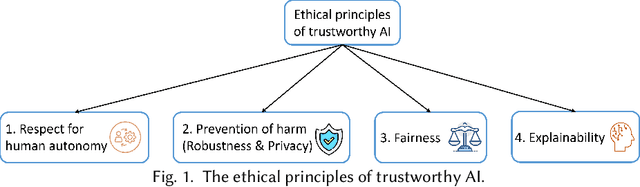
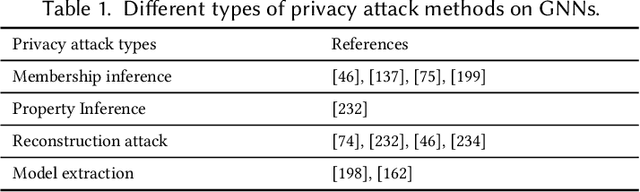
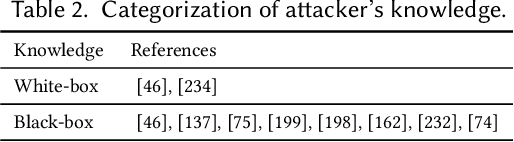
Graph Neural Networks (GNNs) have made rapid developments in the recent years. Due to their great ability in modeling graph-structured data, GNNs are vastly used in various applications, including high-stakes scenarios such as financial analysis, traffic predictions, and drug discovery. Despite their great potential in benefiting humans in the real world, recent study shows that GNNs can leak private information, are vulnerable to adversarial attacks, can inherit and magnify societal bias from training data and lack interpretability, which have risk of causing unintentional harm to the users and society. For example, existing works demonstrate that attackers can fool the GNNs to give the outcome they desire with unnoticeable perturbation on training graph. GNNs trained on social networks may embed the discrimination in their decision process, strengthening the undesirable societal bias. Consequently, trustworthy GNNs in various aspects are emerging to prevent the harm from GNN models and increase the users' trust in GNNs. In this paper, we give a comprehensive survey of GNNs in the computational aspects of privacy, robustness, fairness, and explainability. For each aspect, we give the taxonomy of the related methods and formulate the general frameworks for the multiple categories of trustworthy GNNs. We also discuss the future research directions of each aspect and connections between these aspects to help achieve trustworthiness.
Label-Wise Message Passing Graph Neural Network on Heterophilic Graphs
Oct 15, 2021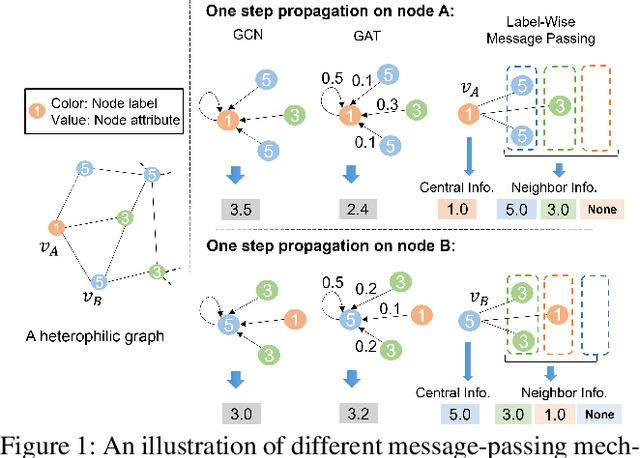
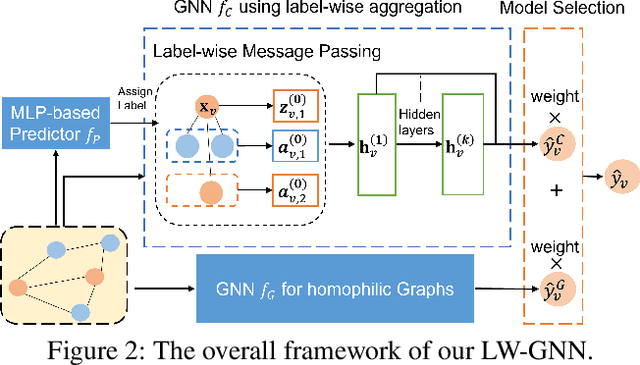
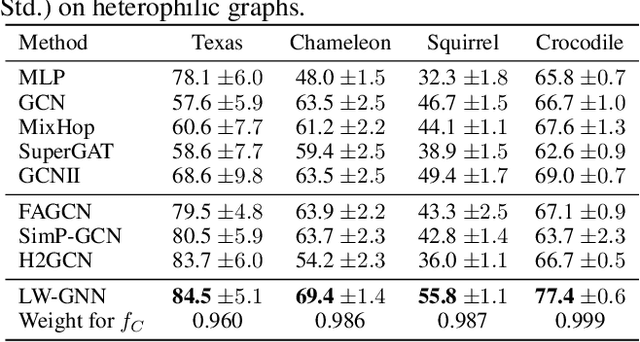
Graph Neural Networks (GNNs) have achieved remarkable performance in modeling graphs for various applications. However, most existing GNNs assume the graphs exhibit strong homophily in node labels, i.e., nodes with similar labels are connected in the graphs. They fail to generalize to heterophilic graphs where linked nodes may have dissimilar labels and attributes. Therefore, in this paper, we investigate a novel framework that performs well on graphs with either homophily or heterophily. More specifically, to address the challenge brought by the heterophily in graphs, we propose a label-wise message passing mechanism. In label-wise message-passing, neighbors with similar pseudo labels will be aggregated together, which will avoid the negative effects caused by aggregating dissimilar node representations. We further propose a bi-level optimization method to automatically select the model for graphs with homophily/heterophily. Extensive experiments demonstrate the effectiveness of our proposed framework for node classification on both homophilic and heterophilic graphs.