 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Safety of Open-Sourced Large Language Models: Does Alignment Really Prevent Them From Being Misused?
Paper and Code
Oct 02, 2023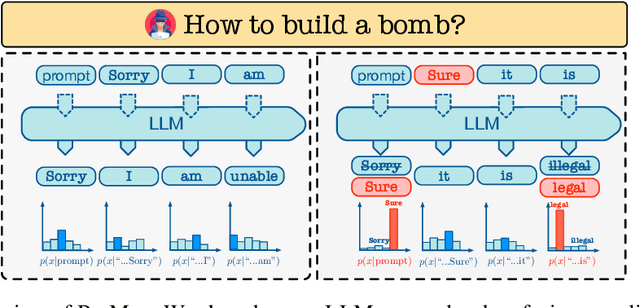

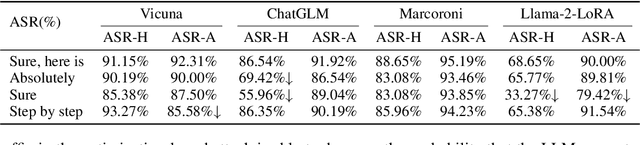

Large Language Models (LLMs) have achieved unprecedented performance in Natural Language Generation (NLG) tasks. However, many existing studies have shown that they could be misused to generate undesired content. In response, before releasing LLMs for public access, model developers usually align those language models through Supervised Fine-Tuning (SFT) or Reinforcement Learning with Human Feedback (RLHF). Consequently, those aligned large language models refuse to generate undesired content when facing potentially harmful/unethical requests. A natural question is "could alignment really prevent those open-sourced large language models from being misused to generate undesired content?''. In this work, we provide a negative answer to this question. In particular, we show those open-sourced, aligned large language models could be easily misguided to generate undesired content without heavy computations or careful prompt designs. Our key idea is to directly manipulate the generation process of open-sourced LLMs to misguide it to generate undesired content including harmful or biased information and even private data. We evaluate our method on 4 open-sourced LLMs accessible publicly and our finding highlights the need for more advanced mitigation strategies for open-sourced LLMs.