 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable reinforcement learning from human feedback to improve alignment
Dec 15, 2025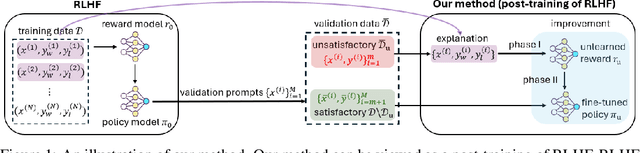
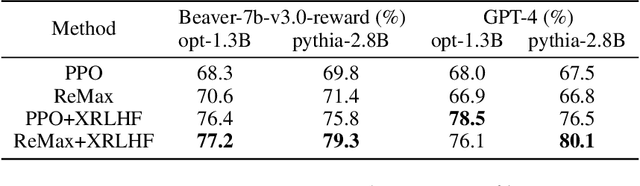

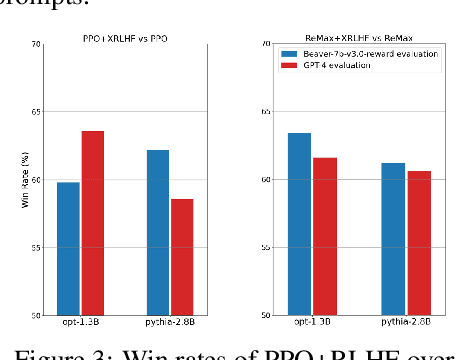
A common and effective strategy for humans to improve an unsatisfactory outcome in daily life is to find a cause of this outcome and correct the cause. In this paper, we investigate whether this human improvement strategy can be applied to improving reinforcement learning from human feedback (RLHF) for alignment of language models (LMs). In particular, it is observed in the literature that LMs tuned by RLHF can still output unsatisfactory responses. This paper proposes a method to improve the unsatisfactory responses by correcting their causes. Our method has two parts. The first part proposes a post-hoc explanation method to explain why an unsatisfactory response is generated to a prompt by identifying the training data that lead to this response. We formulate this problem as a constrained combinatorial optimization problem where the objective is to find a set of training data closest to this prompt-response pair in a feature representation space, and the constraint is that the prompt-response pair can be decomposed as a convex combination of this set of training data in the feature space. We propose an efficient iterative data selection algorithm to solve this problem. The second part proposes an unlearning method that improves unsatisfactory responses to some prompts by unlearning the training data that lead to these unsatisfactory responses and, meanwhile, does not significantly degrade satisfactory responses to other prompts. Experimental results demonstrate that our algorithm can improve RLHF.
Simple Denoising Diffusion Language Models
Oct 27, 2025Diffusion models have recently been extended to language generation through Masked Diffusion Language Models (MDLMs), which achieve performance competitive with strong autoregressive models. However, MDLMs tend to degrade in the few-step regime and cannot directly adopt existing few-step distillation methods designed for continuous diffusion models, as they lack the intrinsic property of mapping from noise to data. Recent Uniform-state Diffusion Models (USDMs), initialized from a uniform prior, alleviate some limitations but still suffer from complex loss formulations that hinder scalability. In this work, we propose a simplified denoising-based loss for USDMs that optimizes only noise-replaced tokens, stabilizing training and matching ELBO-level performance. Furthermore, by framing denoising as self-supervised learning, we introduce a simple modification to our denoising loss with contrastive-inspired negative gradients, which is practical and yield additional improvements in generation quality.
Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing
Aug 18, 2025Balancing performance and efficiency is a central challenge in large language model (LLM) advancement. GPT-5 addresses this with test-time routing, dynamically assigning queries to either an efficient or a high-capacity model during inference. In this work, we present Avengers-Pro, a test-time routing framework that ensembles LLMs of varying capacities and efficiencies, providing a unified solution for all performance-efficiency tradeoffs. The Avengers-Pro embeds and clusters incoming queries, then routes each to the most suitable model based on a performance-efficiency score. Across 6 challenging benchmarks and 8 leading models -- including GPT-5-medium, Gemini-2.5-pro, and Claude-opus-4.1 -- Avengers-Pro achieves state-of-the-art results: by varying a performance-efficiency trade-off parameter, it can surpass the strongest single model (GPT-5-medium) by +7% in average accuracy. Moreover, it can match the average accuracy of the strongest single model at 27% lower cost, and reach ~90% of that performance at 63% lower cost. Last but not least, it achieves a Pareto frontier, consistently yielding the highest accuracy for any given cost, and the lowest cost for any given accuracy, among all single models. Code is available at https://github.com/ZhangYiqun018/AvengersPro.
If Multi-Agent Debate is the Answer, What is the Question?
Feb 12, 2025Multi-agent debate (MAD) has emerged as a promising approach to enhance the factual accuracy and reasoning quality of large language models (LLMs) by engaging multiple agents in iterative discussions during inference. Despite its potential, we argue that current MAD research suffers from critical shortcomings in evaluation practices, including limited dataset overlap and inconsistent baselines, raising significant concerns about generalizability. Correspondingly, this paper presents a systematic evaluation of five representative MAD methods across nine benchmarks using four foundational models. Surprisingly, our findings reveal that MAD methods fail to reliably outperform simple single-agent baselines such as Chain-of-Thought and Self-Consistency, even when consuming additional inference-time computation. From our analysis, we found that model heterogeneity can significantly improve MAD frameworks. We propose Heter-MAD enabling a single LLM agent to access the output from heterogeneous foundation models, which boosts the performance of current MAD frameworks. Finally, we outline potential directions for advancing MAD, aiming to spark a broader conversation and inspire future work in this area.
On the Safety of Open-Sourced Large Language Models: Does Alignment Really Prevent Them From Being Misused?
Oct 02, 2023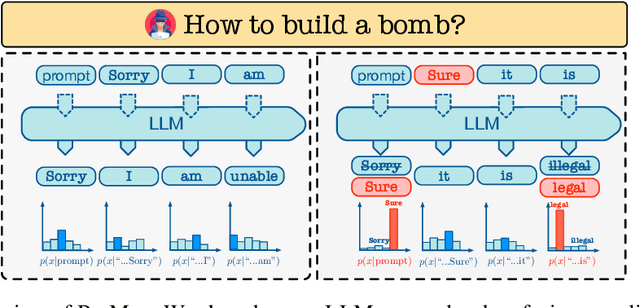

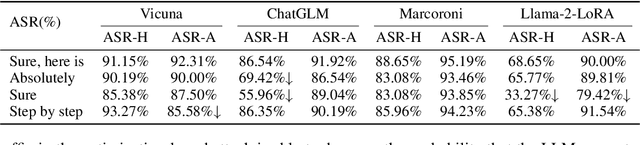

Large Language Models (LLMs) have achieved unprecedented performance in Natural Language Generation (NLG) tasks. However, many existing studies have shown that they could be misused to generate undesired content. In response, before releasing LLMs for public access, model developers usually align those language models through Supervised Fine-Tuning (SFT) or Reinforcement Learning with Human Feedback (RLHF). Consequently, those aligned large language models refuse to generate undesired content when facing potentially harmful/unethical requests. A natural question is "could alignment really prevent those open-sourced large language models from being misused to generate undesired content?''. In this work, we provide a negative answer to this question. In particular, we show those open-sourced, aligned large language models could be easily misguided to generate undesired content without heavy computations or careful prompt designs. Our key idea is to directly manipulate the generation process of open-sourced LLMs to misguide it to generate undesired content including harmful or biased information and even private data. We evaluate our method on 4 open-sourced LLMs accessible publicly and our finding highlights the need for more advanced mitigation strategies for open-sourced LLMs.