 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf Multi-Agent Debate is the Answer, What is the Question?
Feb 12, 2025Multi-agent debate (MAD) has emerged as a promising approach to enhance the factual accuracy and reasoning quality of large language models (LLMs) by engaging multiple agents in iterative discussions during inference. Despite its potential, we argue that current MAD research suffers from critical shortcomings in evaluation practices, including limited dataset overlap and inconsistent baselines, raising significant concerns about generalizability. Correspondingly, this paper presents a systematic evaluation of five representative MAD methods across nine benchmarks using four foundational models. Surprisingly, our findings reveal that MAD methods fail to reliably outperform simple single-agent baselines such as Chain-of-Thought and Self-Consistency, even when consuming additional inference-time computation. From our analysis, we found that model heterogeneity can significantly improve MAD frameworks. We propose Heter-MAD enabling a single LLM agent to access the output from heterogeneous foundation models, which boosts the performance of current MAD frameworks. Finally, we outline potential directions for advancing MAD, aiming to spark a broader conversation and inspire future work in this area.
Graph Adversarial Diffusion Convolution
Jun 04, 2024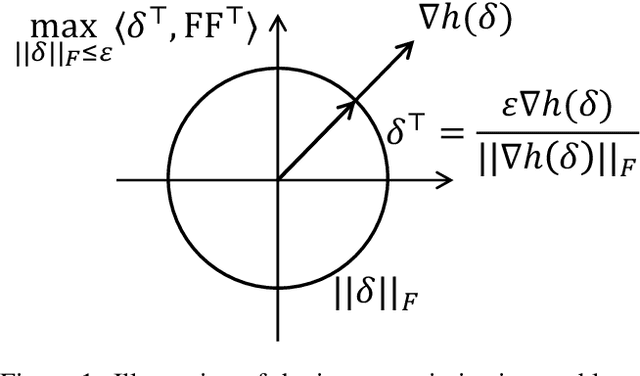
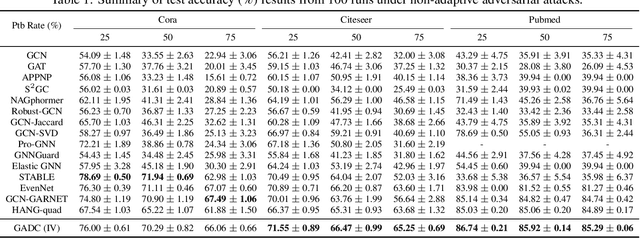

This paper introduces a min-max optimization formulation for the Graph Signal Denoising (GSD) problem. In this formulation, we first maximize the second term of GSD by introducing perturbations to the graph structure based on Laplacian distance and then minimize the overall loss of the GSD. By solving the min-max optimization problem, we derive a new variant of the Graph Diffusion Convolution (GDC) architecture, called Graph Adversarial Diffusion Convolution (GADC). GADC differs from GDC by incorporating an additional term that enhances robustness against adversarial attacks on the graph structure and noise in node features. Moreover, GADC improves the performance of GDC on heterophilic graphs. Extensive experiments demonstrate the effectiveness of GADC across various datasets. Code is available at https://github.com/SongtaoLiu0823/GADC.
On the Safety of Open-Sourced Large Language Models: Does Alignment Really Prevent Them From Being Misused?
Oct 02, 2023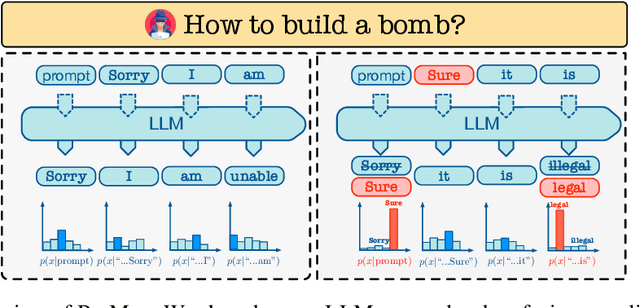

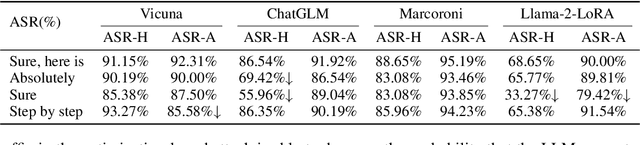

Large Language Models (LLMs) have achieved unprecedented performance in Natural Language Generation (NLG) tasks. However, many existing studies have shown that they could be misused to generate undesired content. In response, before releasing LLMs for public access, model developers usually align those language models through Supervised Fine-Tuning (SFT) or Reinforcement Learning with Human Feedback (RLHF). Consequently, those aligned large language models refuse to generate undesired content when facing potentially harmful/unethical requests. A natural question is "could alignment really prevent those open-sourced large language models from being misused to generate undesired content?''. In this work, we provide a negative answer to this question. In particular, we show those open-sourced, aligned large language models could be easily misguided to generate undesired content without heavy computations or careful prompt designs. Our key idea is to directly manipulate the generation process of open-sourced LLMs to misguide it to generate undesired content including harmful or biased information and even private data. We evaluate our method on 4 open-sourced LLMs accessible publicly and our finding highlights the need for more advanced mitigation strategies for open-sourced LLMs.
Adversary for Social Good: Leveraging Adversarial Attacks to Protect Personal Attribute Privacy
Jun 04, 2023



Social media has drastically reshaped the world that allows billions of people to engage in such interactive environments to conveniently create and share content with the public. Among them, text data (e.g., tweets, blogs) maintains the basic yet important social activities and generates a rich source of user-oriented information. While those explicit sensitive user data like credentials has been significantly protected by all means, personal private attribute (e.g., age, gender, location) disclosure due to inference attacks is somehow challenging to avoid, especially when powerful natural language processing (NLP) techniques have been effectively deployed to automate attribute inferences from implicit text data. This puts users' attribute privacy at risk. To address this challenge, in this paper, we leverage the inherent vulnerability of machine learning to adversarial attacks, and design a novel text-space Adversarial attack for Social Good, called Adv4SG. In other words, we cast the problem of protecting personal attribute privacy as an adversarial attack formulation problem over the social media text data to defend against NLP-based attribute inference attacks. More specifically, Adv4SG proceeds with a sequence of word perturbations under given constraints such that the probed attribute cannot be identified correctly. Different from the prior works, we advance Adv4SG by considering social media property, and introducing cost-effective mechanisms to expedite attribute obfuscation over text data under the black-box setting. Extensive experiments on real-world social media datasets have demonstrated that our method can effectively degrade the inference accuracy with less computational cost over different attribute settings, which substantially helps mitigate the impacts of inference attacks and thus achieve high performance in user attribute privacy protection.
Metro: Memory-Enhanced Transformer for Retrosynthetic Planning via Reaction Tree
Sep 30, 2022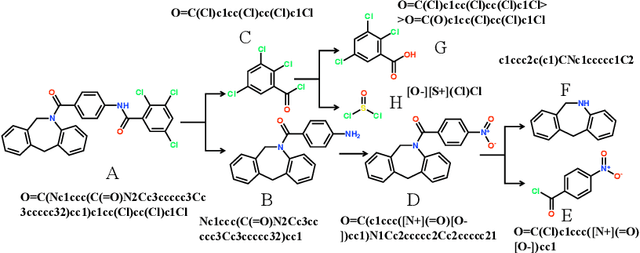
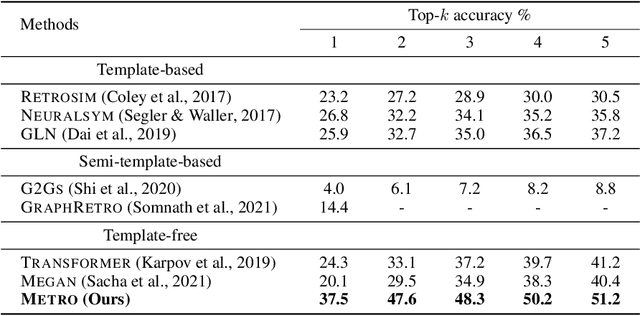
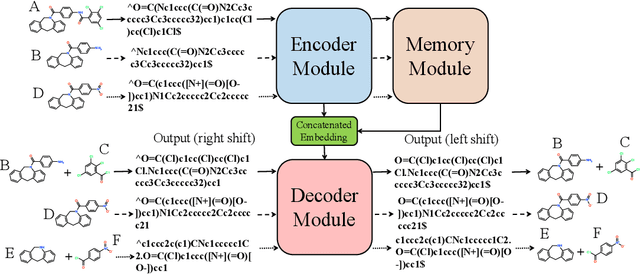

Retrosynthetic planning plays a critical role in drug discovery and organic chemistry. Starting from a target molecule as the root node, it aims to find a complete reaction tree subject to the constraint that all leaf nodes belong to a set of starting materials. The multi-step reactions are crucial because they determine the flow chart in the production of the Organic Chemical Industry. However, existing datasets lack curation of tree-structured multi-step reactions, and fail to provide such reaction trees, limiting models' understanding of organic molecule transformations. In this work, we first develop a benchmark curated for the retrosynthetic planning task, which consists of 124,869 reaction trees retrieved from the public USPTO-full dataset. On top of that, we propose Metro: Memory-Enhanced Transformer for RetrOsynthetic planning. Specifically, the dependency among molecules in the reaction tree is captured as context information for multi-step retrosynthesis predictions through transformers with a memory module. Extensive experiments show that Metro dramatically outperforms existing single-step retrosynthesis models by at least 10.7% in top-1 accuracy. The experiments demonstrate the superiority of exploiting context information in the retrosynthetic planning task. Moreover, the proposed model can be directly used for synthetic accessibility analysis, as it is trained on reaction trees with the shortest depths. Our work is the first step towards a brand new formulation for retrosynthetic planning in the aspects of data construction, model design, and evaluation. Code is available at https://github.com/SongtaoLiu0823/metro.
How Powerful is Implicit Denoising in Graph Neural Networks
Sep 29, 2022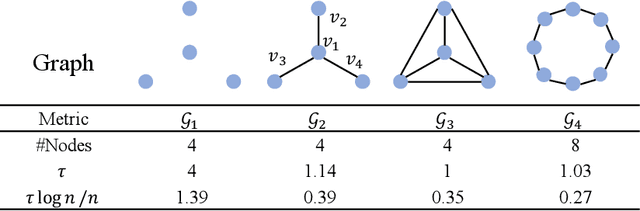
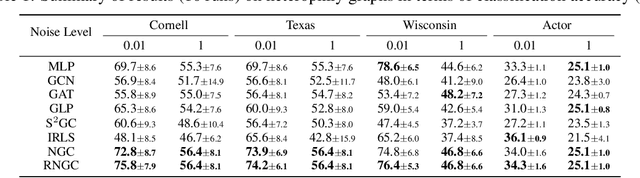
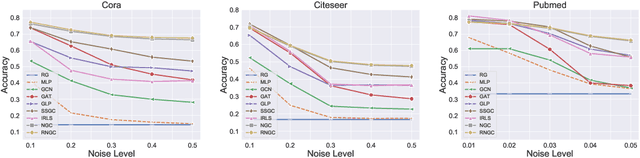
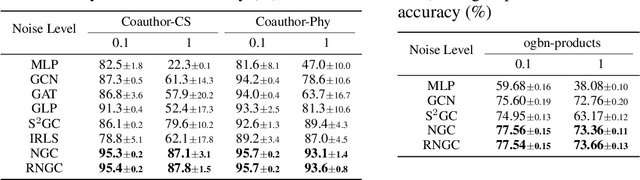
Graph Neural Networks (GNNs), which aggregate features from neighbors, are widely used for graph-structured data processing due to their powerful representation learning capabilities. It is generally believed that GNNs can implicitly remove the non-predictive noises. However, the analysis of implicit denoising effect in graph neural networks remains open. In this work, we conduct a comprehensive theoretical study and analyze when and why the implicit denoising happens in GNNs. Specifically, we study the convergence properties of noise matrix. Our theoretical analysis suggests that the implicit denoising largely depends on the connectivity, the graph size, and GNN architectures. Moreover, we formally define and propose the adversarial graph signal denoising (AGSD) problem by extending graph signal denoising problem. By solving such a problem, we derive a robust graph convolution, where the smoothness of the node representations and the implicit denoising effect can be enhanced. Extensive empirical evaluations verify our theoretical analyses and the effectiveness of our proposed model.
Local Augmentation for Graph Neural Networks
Sep 08, 2021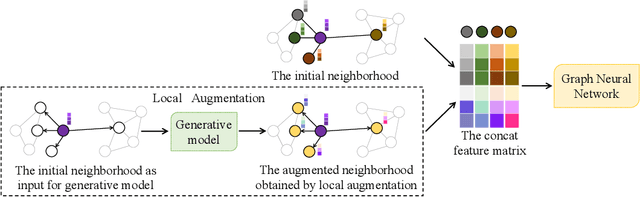
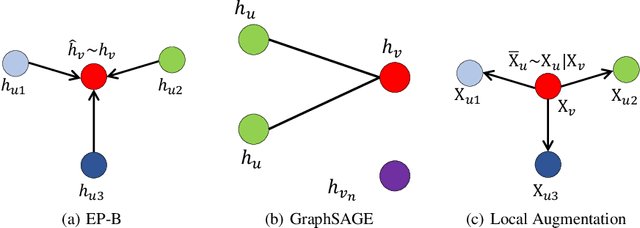

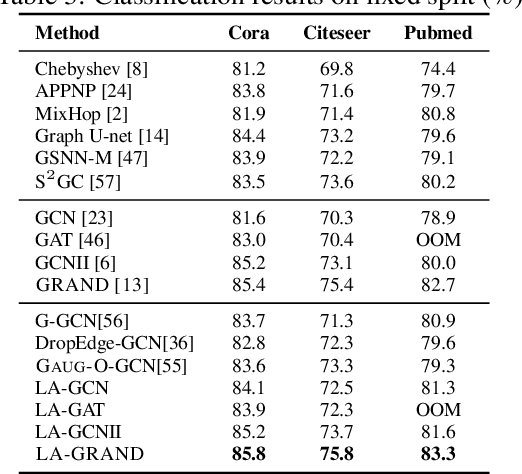
Data augmentation has been widely used in image data and linguistic data but remains under-explored on graph-structured data. Existing methods focus on augmenting the graph data from a global perspective and largely fall into two genres: structural manipulation and adversarial training with feature noise injection. However, the structural manipulation approach suffers information loss issues while the adversarial training approach may downgrade the feature quality by injecting noise. In this work, we introduce the local augmentation, which enhances node features by its local subgraph structures. Specifically, we model the data argumentation as a feature generation process. Given the central node's feature, our local augmentation approach learns the conditional distribution of its neighbors' features and generates the neighbors' optimal feature to boost the performance of downstream tasks. Based on the local augmentation, we further design a novel framework: LA-GNN, which can apply to any GNN models in a plug-and-play manner. Extensive experiments and analyses show that local augmentation consistently yields performance improvement for various GNN architectures across a diverse set of benchmarks. Code is available at https://github.com/Soughing0823/LAGNN.
Zooming Into the Darknet: Characterizing Internet Background Radiation and its Structural Changes
Aug 05, 2021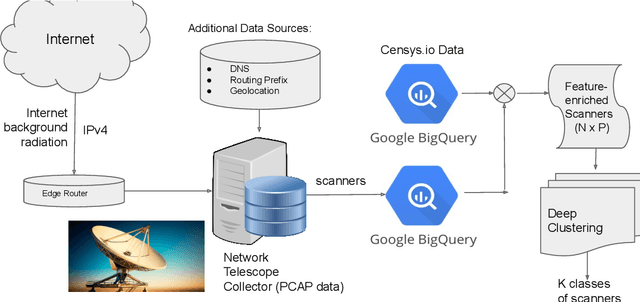

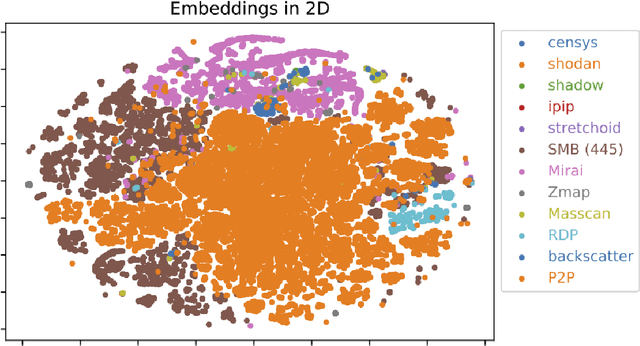

Network telescopes or "Darknets" provide a unique window into Internet-wide malicious activities associated with malware propagation, denial of service attacks, scanning performed for network reconnaissance, and others. Analyses of the resulting data can provide actionable insights to security analysts that can be used to prevent or mitigate cyber-threats. Large Darknets, however, observe millions of nefarious events on a daily basis which makes the transformation of the captured information into meaningful insights challenging. We present a novel framework for characterizing Darknet behavior and its temporal evolution aiming to address this challenge. The proposed framework: (i) Extracts a high dimensional representation of Darknet events composed of features distilled from Darknet data and other external sources; (ii) Learns, in an unsupervised fashion, an information-preserving low-dimensional representation of these events (using deep representation learning) that is amenable to clustering; (iv) Performs clustering of the scanner data in the resulting representation space and provides interpretable insights using optimal decision trees; and (v) Utilizes the clustering outcomes as "signatures" that can be used to detect structural changes in the Darknet activities. We evaluate the proposed system on a large operational Network Telescope and demonstrate its ability to detect real-world, high-impact cybersecurity incidents.
Higher-order Weighted Graph Convolutional Networks
Nov 12, 2019
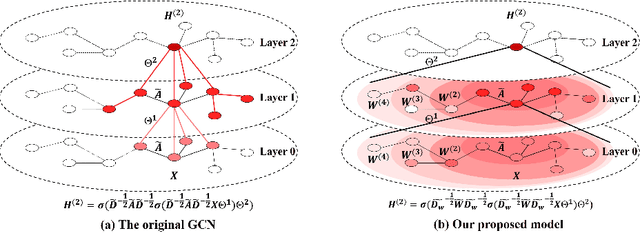

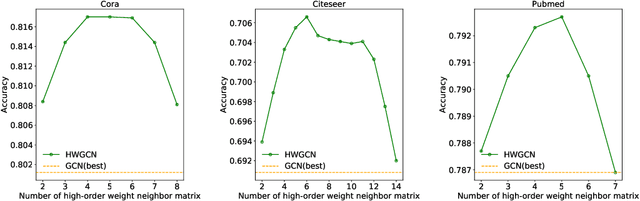
Graph Convolution Network (GCN) has been recognized as one of the most effective graph models for semi-supervised learning, but it extracts merely the first-order or few-order neighborhood information through information propagation, which suffers performance drop-off for deeper structure. Existing approaches that deal with the higher-order neighbors tend to take advantage of adjacency matrix power. In this paper, we assume a seemly trivial condition that the higher-order neighborhood information may be similar to that of the first-order neighbors. Accordingly, we present an unsupervised approach to describe such similarities and learn the weight matrices of higher-order neighbors automatically through Lasso that minimizes the feature loss between the first-order and higher-order neighbors, based on which we formulate the new convolutional filter for GCN to learn the better node representations. Our model, called higher-order weighted GCN(HWGCN), has achieved the state-of-the-art results on a number of node classification tasks over Cora, Citeseer and Pubmed datasets.