 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Agent Memory: Taxonomy, Techniques, and Applications
Feb 05, 2026Memory emerges as the core module in the Large Language Model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. Among diverse paradigms, graph stands out as a powerful structure for agent memory due to the intrinsic capabilities to model relational dependencies, organize hierarchical information, and support efficient retrieval. This survey presents a comprehensive review of agent memory from the graph-based perspective. First, we introduce a taxonomy of agent memory, including short-term vs. long-term memory, knowledge vs. experience memory, non-structural vs. structural memory, with an implementation view of graph-based memory. Second, according to the life cycle of agent memory, we systematically analyze the key techniques in graph-based agent memory, covering memory extraction for transforming the data into the contents, storage for organizing the data efficiently, retrieval for retrieving the relevant contents from memory to support reasoning, and evolution for updating the contents in the memory. Third, we summarize the open-sourced libraries and benchmarks that support the development and evaluation of self-evolving agent memory. We also explore diverse application scenarios. Finally, we identify critical challenges and future research directions. This survey aims to offer actionable insights to advance the development of more efficient and reliable graph-based agent memory systems. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/DEEP-PolyU/Awesome-GraphMemory.
History Is Not Enough: An Adaptive Dataflow System for Financial Time-Series Synthesis
Jan 15, 2026In quantitative finance, the gap between training and real-world performance-driven by concept drift and distributional non-stationarity-remains a critical obstacle for building reliable data-driven systems. Models trained on static historical data often overfit, resulting in poor generalization in dynamic markets. The mantra "History Is Not Enough" underscores the need for adaptive data generation that learns to evolve with the market rather than relying solely on past observations. We present a drift-aware dataflow system that integrates machine learning-based adaptive control into the data curation process. The system couples a parameterized data manipulation module comprising single-stock transformations, multi-stock mix-ups, and curation operations, with an adaptive planner-scheduler that employs gradient-based bi-level optimization to control the system. This design unifies data augmentation, curriculum learning, and data workflow management under a single differentiable framework, enabling provenance-aware replay and continuous data quality monitoring. Extensive experiments on forecasting and reinforcement learning trading tasks demonstrate that our framework enhances model robustness and improves risk-adjusted returns. The system provides a generalizable approach to adaptive data management and learning-guided workflow automation for financial data.
SCALER:Synthetic Scalable Adaptive Learning Environment for Reasoning
Jan 08, 2026Reinforcement learning (RL) offers a principled way to enhance the reasoning capabilities of large language models, yet its effectiveness hinges on training signals that remain informative as models evolve. In practice, RL progress often slows when task difficulty becomes poorly aligned with model capability, or when training is dominated by a narrow set of recurring problem patterns. To jointly address these issues, we propose SCALER (Synthetic sCalable Adaptive Learning Environment for Reasoning), a framework that sustains effective learning signals through adaptive environment design. SCALER introduces a scalable synthesis pipeline that converts real-world programming problems into verifiable reasoning environments with controllable difficulty and unbounded instance generation, enabling RL training beyond finite datasets while preserving strong correctness guarantees. Building on this, SCALER further employs an adaptive multi-environment RL strategy that dynamically adjusts instance difficulty and curates the active set of environments to track the model's capability frontier and maintain distributional diversity. This co-adaptation prevents reward sparsity, mitigates overfitting to narrow task patterns, and supports sustained improvement throughout training. Extensive experiments show that SCALER consistently outperforms dataset-based RL baselines across diverse reasoning benchmarks and exhibits more stable, long-horizon training dynamics.
FineFT: Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading
Dec 29, 2025Futures are contracts obligating the exchange of an asset at a predetermined date and price, notable for their high leverage and liquidity and, therefore, thrive in the Crypto market. RL has been widely applied in various quantitative tasks. However, most methods focus on the spot and could not be directly applied to the futures market with high leverage because of 2 challenges. First, high leverage amplifies reward fluctuations, making training stochastic and difficult to converge. Second, prior works lacked self-awareness of capability boundaries, exposing them to the risk of significant loss when encountering new market state (e.g.,a black swan event like COVID-19). To tackle these challenges, we propose the Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading (FineFT), a novel three-stage ensemble RL framework with stable training and proper risk management. In stage I, ensemble Q learners are selectively updated by ensemble TD errors to improve convergence. In stage II, we filter the Q-learners based on their profitabilities and train VAEs on market states to identify the capability boundaries of the learners. In stage III, we choose from the filtered ensemble and a conservative policy, guided by trained VAEs, to maintain profitability and mitigate risk with new market states. Through extensive experiments on crypto futures in a high-frequency trading environment with high fidelity and 5x leverage, we demonstrate that FineFT outperforms 12 SOTA baselines in 6 financial metrics, reducing risk by more than 40% while achieving superior profitability compared to the runner-up. Visualization of the selective update mechanism shows that different agents specialize in distinct market dynamics, and ablation studies certify routing with VAEs reduces maximum drawdown effectively, and selective update improves convergence and performance.
MATAI: A Generalist Machine Learning Framework for Property Prediction and Inverse Design of Advanced Alloys
Nov 13, 2025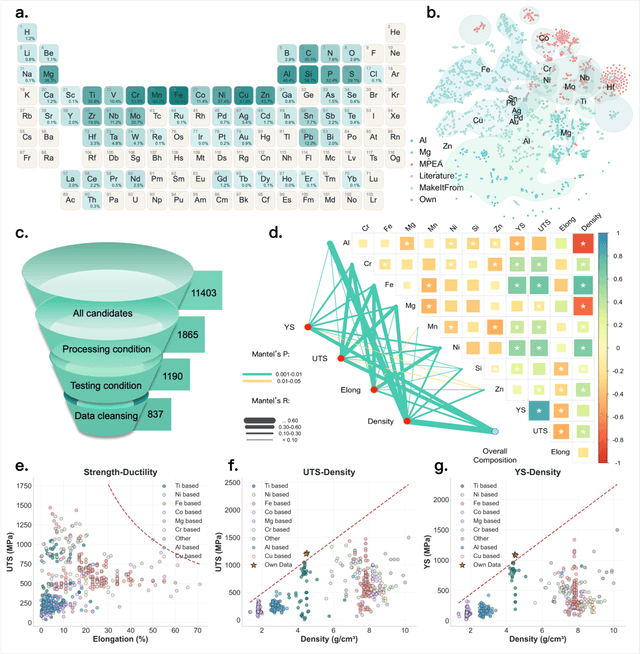
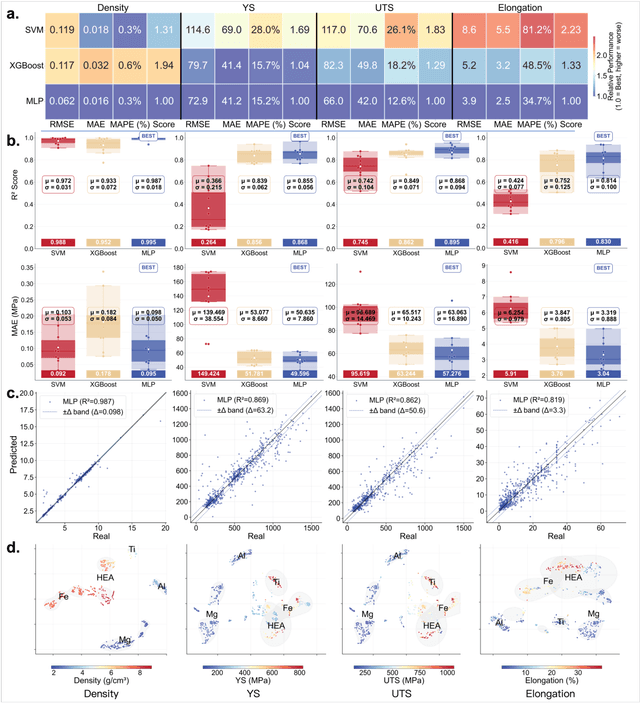
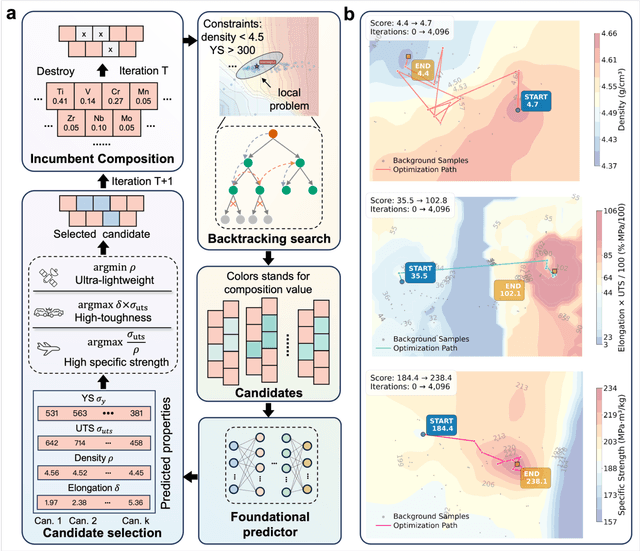
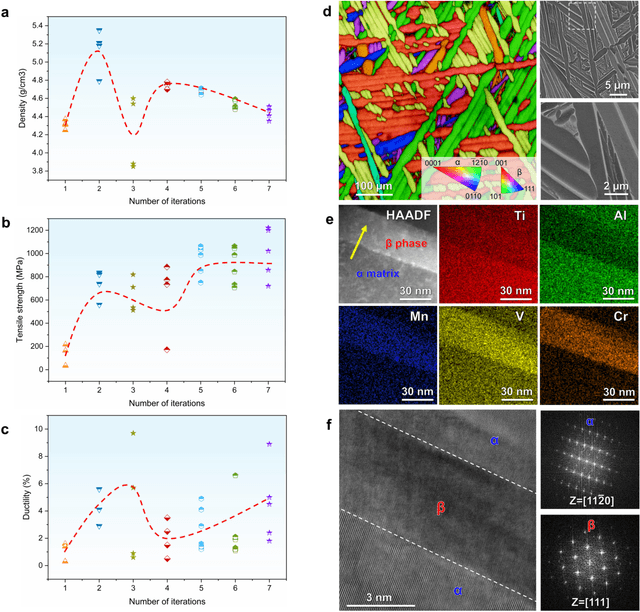
The discovery of advanced metallic alloys is hindered by vast composition spaces, competing property objectives, and real-world constraints on manufacturability. Here we introduce MATAI, a generalist machine learning framework for property prediction and inverse design of as-cast alloys. MATAI integrates a curated alloy database, deep neural network-based property predictors, a constraint-aware optimization engine, and an iterative AI-experiment feedback loop. The framework estimates key mechanical propertie, sincluding density, yield strength, ultimate tensile strength, and elongation, directly from composition, using multi-task learning and physics-informed inductive biases. Alloy design is framed as a constrained optimization problem and solved using a bi-level approach that combines local search with symbolic constraint programming. We demonstrate MATAI's capabilities on the Ti-based alloy system, a canonical class of lightweight structural materials, where it rapidly identifies candidates that simultaneously achieve lower density (<4.45 g/cm3), higher strength (>1000 MPa) and appreciable ductility (>5%) through only seven iterations. Experimental validation confirms that MATAI-designed alloys outperform commercial references such as TC4, highlighting the framework's potential to accelerate the discovery of lightweight, high-performance materials under real-world design constraints.
GDBA Revisited: Unleashing the Power of Guided Local Search for Distributed Constraint Optimization
Aug 09, 2025Local search is an important class of incomplete algorithms for solving Distributed Constraint Optimization Problems (DCOPs) but it often converges to poor local optima. While GDBA provides a comprehensive rule set to escape premature convergence, its empirical benefits remain marginal on general-valued problems. In this work, we systematically examine GDBA and identify three factors that potentially lead to its inferior performance, i.e., over-aggressive constraint violation conditions, unbounded penalty accumulation, and uncoordinated penalty updates. To address these issues, we propose Distributed Guided Local Search (DGLS), a novel GLS framework for DCOPs that incorporates an adaptive violation condition to selectively penalize constraints with high cost, a penalty evaporation mechanism to control the magnitude of penalization, and a synchronization scheme for coordinated penalty updates. We theoretically show that the penalty values are bounded, and agents play a potential game in our DGLS. Our extensive empirical results on various standard benchmarks demonstrate the great superiority of DGLS over state-of-the-art baselines. Particularly, compared to Damped Max-sum with high damping factors (e.g., 0.7 or 0.9), our DGLS achieves competitive performance on general-valued problems, and outperforms it by significant margins (\textbf{3.77\%--66.3\%}) on structured problems in terms of anytime results.
StarDojo: Benchmarking Open-Ended Behaviors of Agentic Multimodal LLMs in Production-Living Simulations with Stardew Valley
Jul 10, 2025Autonomous agents navigating human society must master both production activities and social interactions, yet existing benchmarks rarely evaluate these skills simultaneously. To bridge this gap, we introduce StarDojo, a novel benchmark based on Stardew Valley, designed to assess AI agents in open-ended production-living simulations. In StarDojo, agents are tasked to perform essential livelihood activities such as farming and crafting, while simultaneously engaging in social interactions to establish relationships within a vibrant community. StarDojo features 1,000 meticulously curated tasks across five key domains: farming, crafting, exploration, combat, and social interactions. Additionally, we provide a compact subset of 100 representative tasks for efficient model evaluation. The benchmark offers a unified, user-friendly interface that eliminates the need for keyboard and mouse control, supports all major operating systems, and enables the parallel execution of multiple environment instances, making it particularly well-suited for evaluating the most capable foundation agents, powered by multimodal large language models (MLLMs). Extensive evaluations of state-of-the-art MLLMs agents demonstrate substantial limitations, with the best-performing model, GPT-4.1, achieving only a 12.7% success rate, primarily due to challenges in visual understanding, multimodal reasoning and low-level manipulation. As a user-friendly environment and benchmark, StarDojo aims to facilitate further research towards robust, open-ended agents in complex production-living environments.
FaithfulRAG: Fact-Level Conflict Modeling for Context-Faithful Retrieval-Augmented Generation
Jun 10, 2025



Large language models (LLMs) augmented with retrieval systems have demonstrated significant potential in handling knowledge-intensive tasks. However, these models often struggle with unfaithfulness issues, generating outputs that either ignore the retrieved context or inconsistently blend it with the LLM`s parametric knowledge. This issue is particularly severe in cases of knowledge conflict, where the retrieved context conflicts with the model`s parametric knowledge. While existing faithful RAG approaches enforce strict context adherence through well-designed prompts or modified decoding strategies, our analysis reveals a critical limitation: they achieve faithfulness by forcibly suppressing the model`s parametric knowledge, which undermines the model`s internal knowledge structure and increases the risk of misinterpreting the context. To this end, this paper proposes FaithfulRAG, a novel framework that resolves knowledge conflicts by explicitly modeling discrepancies between the model`s parametric knowledge and retrieved context. Specifically, FaithfulRAG identifies conflicting knowledge at the fact level and designs a self-thinking process, allowing LLMs to reason about and integrate conflicting facts before generating responses. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. The code is available at https:// github.com/DeepLearnXMU/Faithful-RAG
The Avengers: A Simple Recipe for Uniting Smaller Language Models to Challenge Proprietary Giants
May 26, 2025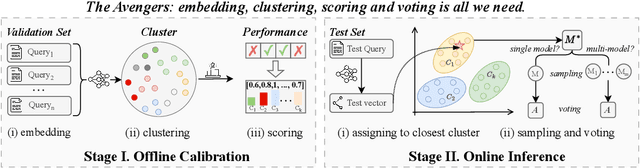
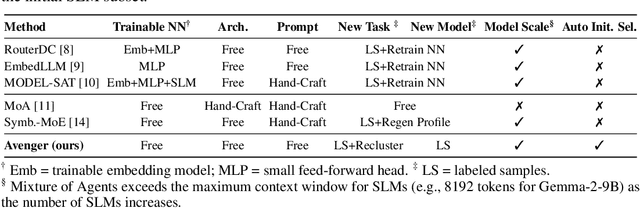
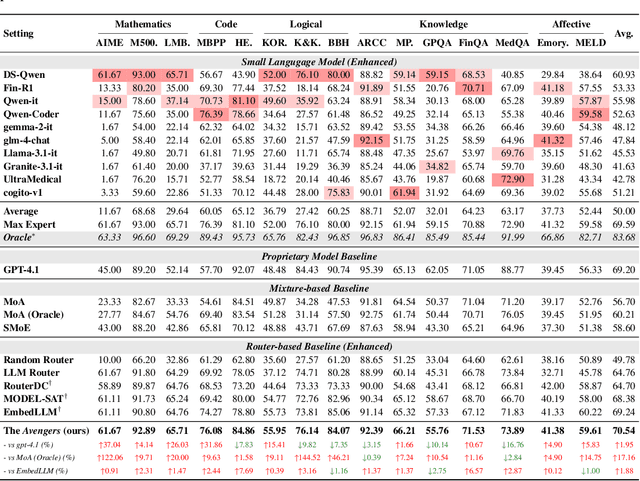
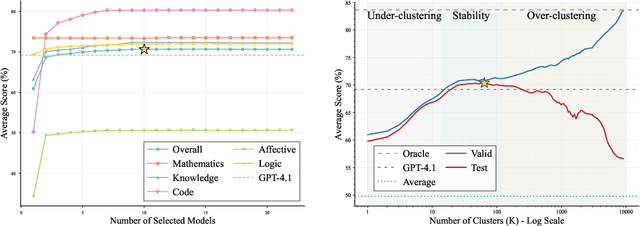
As proprietary giants increasingly dominate the race for ever-larger language models, a pressing question arises for the open-source community: can smaller models remain competitive across a broad range of tasks? In this paper, we present the Avengers--a simple recipe that effectively leverages the collective intelligence of open-source, smaller language models. Our framework is built upon four lightweight operations: (i) embedding: encode queries using a text embedding model; (ii) clustering: group queries based on their semantic similarity; (iii) scoring: scores each model's performance within each cluster; and (iv) voting: improve outputs via repeated sampling and voting. At inference time, each query is embedded and assigned to its nearest cluster. The top-performing model(s) within that cluster are selected to generate the response using the Self-Consistency or its multi-model variant. Remarkably, with 10 open-source models (~7B parameters each), the Avengers collectively outperforms GPT-4.1 on 10 out of 15 datasets (spanning mathematics, code, logic, knowledge, and affective tasks). In particular, it surpasses GPT-4.1 on mathematics tasks by 18.21% and on code tasks by 7.46%. Furthermore, the Avengers delivers superior out-of-distribution generalization, and remains robust across various embedding models, clustering algorithms, ensemble strategies, and values of its sole parameter--the number of clusters. We have open-sourced the code on GitHub: https://github.com/ZhangYiqun018/Avengers
Resolving Latency and Inventory Risk in Market Making with Reinforcement Learning
May 18, 2025The latency of the exchanges in Market Making (MM) is inevitable due to hardware limitations, system processing times, delays in receiving data from exchanges, the time required for order transmission to reach the market, etc. Existing reinforcement learning (RL) methods for Market Making (MM) overlook the impact of these latency, which can lead to unintended order cancellations due to price discrepancies between decision and execution times and result in undesired inventory accumulation, exposing MM traders to increased market risk. Therefore, these methods cannot be applied in real MM scenarios. To address these issues, we first build a realistic MM environment with random delays of 30-100 milliseconds for order placement and market information reception, and implement a batch matching mechanism that collects orders within every 500 milliseconds before matching them all at once, simulating the batch auction mechanisms adopted by some exchanges. Then, we propose Relaver, an RL-based method for MM to tackle the latency and inventory risk issues. The three main contributions of Relaver are: i) we introduce an augmented state-action space that incorporates order hold time alongside price and volume, enabling Relaver to optimize execution strategies under latency constraints and time-priority matching mechanisms, ii) we leverage dynamic programming (DP) to guide the exploration of RL training for better policies, iii) we train a market trend predictor, which can guide the agent to intelligently adjust the inventory to reduce the risk. Extensive experiments and ablation studies on four real-world datasets demonstrate that \textsc{Relaver} significantly improves the performance of state-of-the-art RL-based MM strategies across multiple metrics.