 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
Aug 27, 2025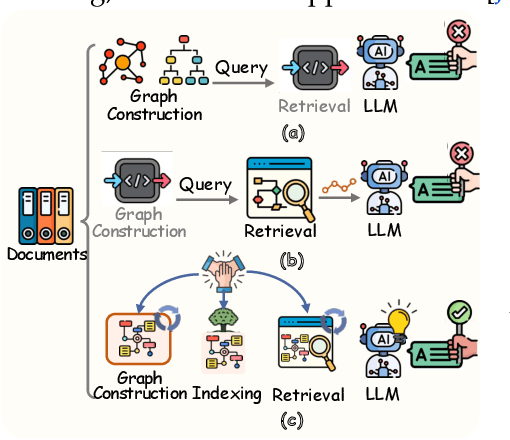
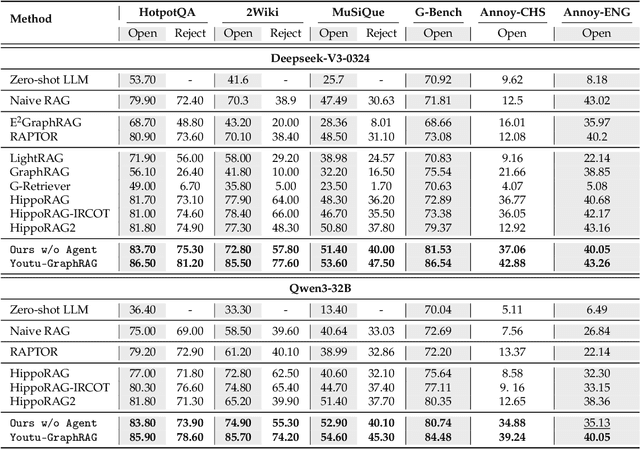

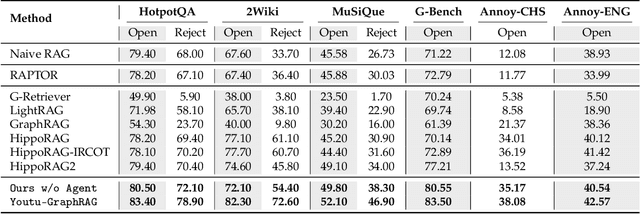
Graph retrieval-augmented generation (GraphRAG) has effectively enhanced large language models in complex reasoning by organizing fragmented knowledge into explicitly structured graphs. Prior efforts have been made to improve either graph construction or graph retrieval in isolation, yielding suboptimal performance, especially when domain shifts occur. In this paper, we propose a vertically unified agentic paradigm, Youtu-GraphRAG, to jointly connect the entire framework as an intricate integration. Specifically, (i) a seed graph schema is introduced to bound the automatic extraction agent with targeted entity types, relations and attribute types, also continuously expanded for scalability over unseen domains; (ii) To obtain higher-level knowledge upon the schema, we develop novel dually-perceived community detection, fusing structural topology with subgraph semantics for comprehensive knowledge organization. This naturally yields a hierarchical knowledge tree that supports both top-down filtering and bottom-up reasoning with community summaries; (iii) An agentic retriever is designed to interpret the same graph schema to transform complex queries into tractable and parallel sub-queries. It iteratively performs reflection for more advanced reasoning; (iv) To alleviate the knowledge leaking problem in pre-trained LLM, we propose a tailored anonymous dataset and a novel 'Anonymity Reversion' task that deeply measures the real performance of the GraphRAG frameworks. Extensive experiments across six challenging benchmarks demonstrate the robustness of Youtu-GraphRAG, remarkably moving the Pareto frontier with up to 90.71% saving of token costs and 16.62% higher accuracy over state-of-the-art baselines. The results indicate our adaptability, allowing seamless domain transfer with minimal intervention on schema.
Benchmarking Large Language Models via Random Variables
Jan 20, 2025With the continuous advancement of large language models (LLMs) in mathematical reasoning, evaluating their performance in this domain has become a prominent research focus. Recent studies have raised concerns about the reliability of current mathematical benchmarks, highlighting issues such as simplistic design and potential data leakage. Therefore, creating a reliable benchmark that effectively evaluates the genuine capabilities of LLMs in mathematical reasoning remains a significant challenge. To address this, we propose RV-Bench, a framework for Benchmarking LLMs via Random Variables in mathematical reasoning. Specifically, the background content of a random variable question (RV question) mirrors the original problem in existing standard benchmarks, but the variable combinations are randomized into different values. LLMs must fully understand the problem-solving process for the original problem to correctly answer RV questions with various combinations of variable values. As a result, the LLM's genuine capability in mathematical reasoning is reflected by its accuracy on RV-Bench. Extensive experiments are conducted with 29 representative LLMs across 900+ RV questions. A leaderboard for RV-Bench ranks the genuine capability of these LLMs. Further analysis of accuracy dropping indicates that current LLMs still struggle with complex mathematical reasoning problems.
CLR-Bench: Evaluating Large Language Models in College-level Reasoning
Oct 23, 2024



Large language models (LLMs) have demonstrated their remarkable performance across various language understanding tasks. While emerging benchmarks have been proposed to evaluate LLMs in various domains such as mathematics and computer science, they merely measure the accuracy in terms of the final prediction on multi-choice questions. However, it remains insufficient to verify the essential understanding of LLMs given a chosen choice. To fill this gap, we present CLR-Bench to comprehensively evaluate the LLMs in complex college-level reasoning. Specifically, (i) we prioritize 16 challenging college disciplines in computer science and artificial intelligence. The dataset contains 5 types of questions, while each question is associated with detailed explanations from experts. (ii) To quantify a fair evaluation of LLMs' reasoning ability, we formalize the criteria with two novel metrics. Q$\rightarrow$A is utilized to measure the performance of direct answer prediction, and Q$\rightarrow$AR effectively considers the joint ability to answer the question and provide rationale simultaneously. Extensive experiments are conducted with 40 LLMs over 1,018 discipline-specific questions. The results demonstrate the key insights that LLMs, even the best closed-source LLM, i.e., GPT-4 turbo, tend to `guess' the college-level answers. It shows a dramatic decrease in accuracy from 63.31% Q$\rightarrow$A to 39.00% Q$\rightarrow$AR, indicating an unsatisfactory reasoning ability.
Neuro-Symbolic Entity Alignment via Variational Inference
Oct 05, 2024



Entity alignment (EA) aims to merge two knowledge graphs (KGs) by identifying equivalent entity pairs. Existing methods can be categorized into symbolic and neural models. Symbolic models, while precise, struggle with substructure heterogeneity and sparsity, whereas neural models, although effective, generally lack interpretability and cannot handle uncertainty. We propose NeuSymEA, a probabilistic neuro-symbolic framework that combines the strengths of both methods. NeuSymEA models the joint probability of all possible pairs' truth scores in a Markov random field, regulated by a set of rules, and optimizes it with the variational EM algorithm. In the E-step, a neural model parameterizes the truth score distributions and infers missing alignments. In the M-step, the rule weights are updated based on the observed and inferred alignments. To facilitate interpretability, we further design a path-ranking-based explainer upon this framework that generates supporting rules for the inferred alignments. Experiments on benchmarks demonstrate that NeuSymEA not only significantly outperforms baselines in terms of effectiveness and robustness, but also provides interpretable results.
Graph Anomaly Detection with Noisy Labels by Reinforcement Learning
Jul 08, 2024



Graph anomaly detection (GAD) has been widely applied in many areas, e.g., fraud detection in finance and robot accounts in social networks. Existing methods are dedicated to identifying the outlier nodes that deviate from normal ones. While they heavily rely on high-quality annotation, which is hard to obtain in real-world scenarios, this could lead to severely degraded performance based on noisy labels. Thus, we are motivated to cut the edges of suspicious nodes to alleviate the impact of noise. However, it remains difficult to precisely identify the nodes with noisy labels. Moreover, it is hard to quantitatively evaluate the regret of cutting the edges, which may have either positive or negative influences. To this end, we propose a novel framework REGAD, i.e., REinforced Graph Anomaly Detector. Specifically, we aim to maximize the performance improvement (AUC) of a base detector by cutting noisy edges approximated through the nodes with high-confidence labels. (i) We design a tailored action and search space to train a policy network to carefully prune edges step by step, where only a few suspicious edges are prioritized in each step. (ii) We design a policy-in-the-loop mechanism to iteratively optimize the policy based on the feedback from base detector. The overall performance is evaluated by the cumulative rewards. Extensive experiments are conducted on three datasets under different anomaly ratios. The results indicate the superior performance of our proposed REGAD.
Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Jun 12, 2024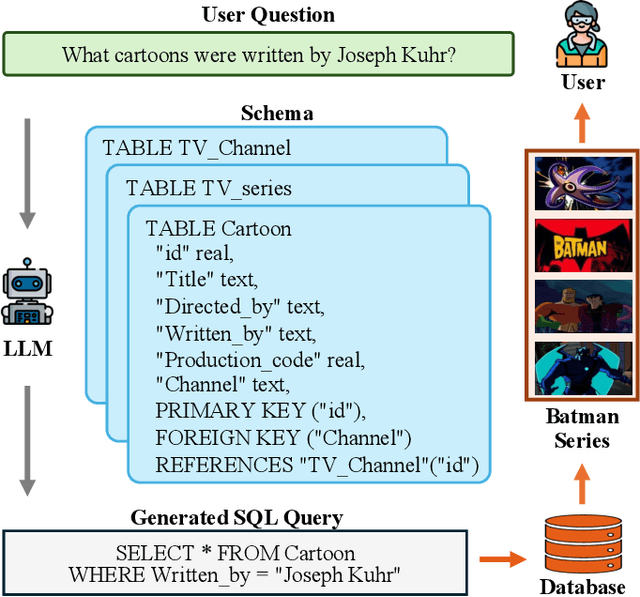

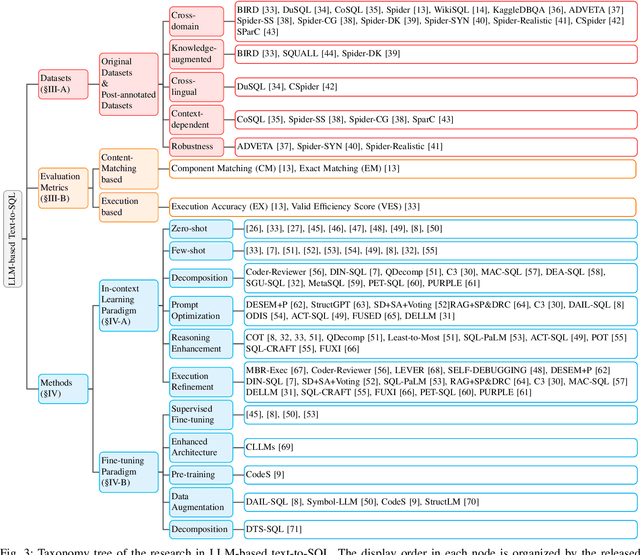
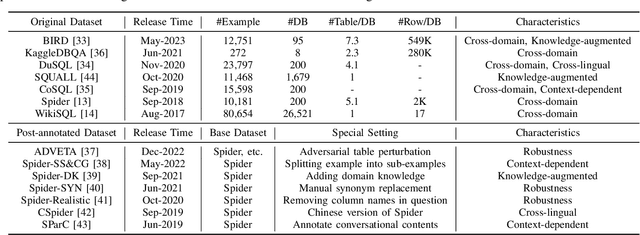
Generating accurate SQL according to natural language questions (text-to-SQL) is a long-standing problem since it is challenging in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems include human engineering and deep neural networks. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex and corresponding user questions more challenging, PLMs with limited comprehension capabilities can lead to incorrect SQL generation. This necessitates more sophisticated and tailored optimization methods, which, in turn, restricts the applications of PLM-based systems. Most recently, large language models (LLMs) have demonstrated significant abilities in natural language understanding as the model scale remains increasing. Therefore, integrating the LLM-based implementation can bring unique opportunities, challenges, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the current challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future directions.
Logical Reasoning with Relation Network for Inductive Knowledge Graph Completion
Jun 03, 2024



Inductive knowledge graph completion (KGC) aims to infer the missing relation for a set of newly-coming entities that never appeared in the training set. Such a setting is more in line with reality, as real-world KGs are constantly evolving and introducing new knowledge. Recent studies have shown promising results using message passing over subgraphs to embed newly-coming entities for inductive KGC. However, the inductive capability of these methods is usually limited by two key issues. (i) KGC always suffers from data sparsity, and the situation is even exacerbated in inductive KGC where new entities often have few or no connections to the original KG. (ii) Cold-start problem. It is over coarse-grained for accurate KG reasoning to generate representations for new entities by gathering the local information from few neighbors. To this end, we propose a novel iNfOmax RelAtion Network, namely NORAN, for inductive KG completion. It aims to mine latent relation patterns for inductive KG completion. Specifically, by centering on relations, NORAN provides a hyper view towards KG modeling, where the correlations between relations can be naturally captured as entity-independent logical evidence to conduct inductive KGC. Extensive experiment results on five benchmarks show that our framework substantially outperforms the state-of-the-art KGC methods.
Entity Alignment with Noisy Annotations from Large Language Models
May 28, 2024Entity alignment (EA) aims to merge two knowledge graphs (KGs) by identifying equivalent entity pairs. While existing methods heavily rely on human-generated labels, it is prohibitively expensive to incorporate cross-domain experts for annotation in real-world scenarios. The advent of Large Language Models (LLMs) presents new avenues for automating EA with annotations, inspired by their comprehensive capability to process semantic information. However, it is nontrivial to directly apply LLMs for EA since the annotation space in real-world KGs is large. LLMs could also generate noisy labels that may mislead the alignment. To this end, we propose a unified framework, LLM4EA, to effectively leverage LLMs for EA. Specifically, we design a novel active learning policy to significantly reduce the annotation space by prioritizing the most valuable entities based on the entire inter-KG and intra-KG structure. Moreover, we introduce an unsupervised label refiner to continuously enhance label accuracy through in-depth probabilistic reasoning. We iteratively optimize the policy based on the feedback from a base EA model. Extensive experiments demonstrate the advantages of LLM4EA on four benchmark datasets in terms of effectiveness, robustness, and efficiency. Codes are available via https://github.com/chensyCN/llm4ea_official.
Cost-efficient Knowledge-based Question Answering with Large Language Models
May 27, 2024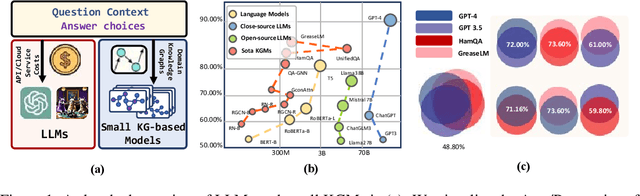
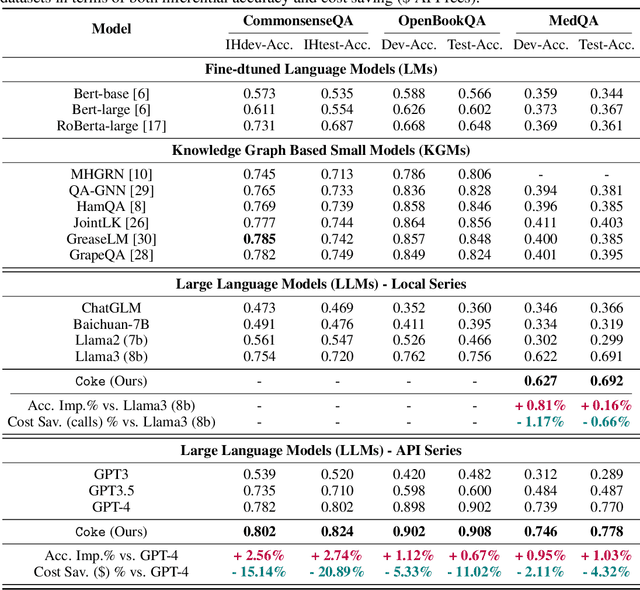
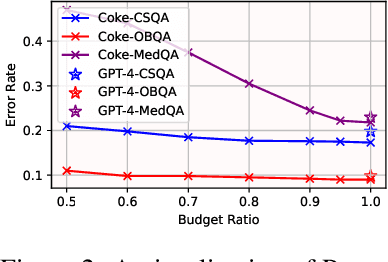
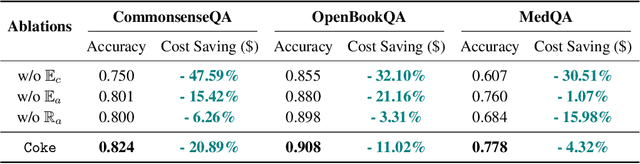
Knowledge-based question answering (KBQA) is widely used in many scenarios that necessitate domain knowledge. Large language models (LLMs) bring opportunities to KBQA, while their costs are significantly higher and absence of domain-specific knowledge during pre-training. We are motivated to combine LLMs and prior small models on knowledge graphs (KGMs) for both inferential accuracy and cost saving. However, it remains challenging since accuracy and cost are not readily combined in the optimization as two distinct metrics. It is also laborious for model selection since different models excel in diverse knowledge. To this end, we propose Coke, a novel cost-efficient strategy for KBQA with LLMs, modeled as a tailored multi-armed bandit problem to minimize calls to LLMs within limited budgets. We first formulate the accuracy expectation with a cluster-level Thompson Sampling for either KGMs or LLMs. A context-aware policy is optimized to further distinguish the expert model subject to the question semantics. The overall decision is bounded by the cost regret according to historical expenditure on failures. Extensive experiments showcase the superior performance of Coke, which moves the Pareto frontier with up to 20.89% saving of GPT-4 fees while achieving a 2.74% higher accuracy on the benchmark datasets.