 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoG: Mixture of Experts for Graph-based Retrieval-Augmented Generation
May 29, 2026Retrieval-augmented generation is intensively studied to ground large language models on external evidence. However, retrieving from a unified knowledge base could inevitably introduce irrelevant information that may mislead generation for complex reasoning. Inspired by the conditional computation of mixture of experts (MoE), where a router sparsely selects specialized experts alongside shared ones for each input, we propose \textbf{M}ixture \textbf{o}f experts for \textbf{G}raph-based Retrieval-Augmented Generation, i.e., \textbf{MoG}. It organizes knowledge into two core components: (i) diverse, always-accessible hub graphs that encode semantically and structurally central knowledge and provide contextual clues for expert activation, and (ii) sparsely activated expert graphs that contain domain-specific evidence. MoG first accesses hub graphs to identify general evidence and derive contextual clues. Then, a topology-aware router dynamically activates a limited set of expert graphs conditioned on the query, thereby confining retrieval to a focused evidence subspace. Extensive experiments on challenging benchmarks show that MoG consistently outperforms strong baselines, with over 20\% relative improvement on MuSiQue. Our code is available in https://github.com/DEEP-PolyU/MoG.
LogicPoison: Logical Attacks on Graph Retrieval-Augmented Generation
Apr 03, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) enhances the reasoning capabilities of Large Language Models (LLMs) by grounding their responses in structured knowledge graphs. Leveraging community detection and relation filtering techniques, GraphRAG systems demonstrate inherent resistance to traditional RAG attacks, such as text poisoning and prompt injection. However, in this paper, we find that the security of GraphRAG systems fundamentally relies on the topological integrity of the underlying graph, which can be undermined by implicitly corrupting the logical connections, without altering surface-level text semantics. To exploit this vulnerability, we propose \textsc{LogicPoison}, a novel attack framework that targets logical reasoning rather than injecting false contents. Specifically, \textsc{LogicPoison} employs a type-preserving entity swapping mechanism to perturb both global logic hubs for disrupting overall graph connectivity and query-specific reasoning bridges for severing essential multi-hop inference paths. This approach effectively reroutes valid reasoning into dead ends while maintaining surface-level textual plausibility. Comprehensive experiments across multiple benchmarks demonstrate that \textsc{LogicPoison} successfully bypasses GraphRAG's defenses, significantly degrading performance and outperforming state-of-the-art baselines in both effectiveness and stealth. Our code is available at \textcolor{blue}https://github.com/Jord8061/logicPoison.
Deep Tabular Research via Continual Experience-Driven Execution
Mar 12, 2026Large language models often struggle with complex long-horizon analytical tasks over unstructured tables, which typically feature hierarchical and bidirectional headers and non-canonical layouts. We formalize this challenge as Deep Tabular Research (DTR), requiring multi-step reasoning over interdependent table regions. To address DTR, we propose a novel agentic framework that treats tabular reasoning as a closed-loop decision-making process. We carefully design a coupled query and table comprehension for path decision making and operational execution. Specifically, (i) DTR first constructs a hierarchical meta graph to capture bidirectional semantics, mapping natural language queries into an operation-level search space; (ii) To navigate this space, we introduce an expectation-aware selection policy that prioritizes high-utility execution paths; (iii) Crucially, historical execution outcomes are synthesized into a siamese structured memory, i.e., parameterized updates and abstracted texts, enabling continual refinement. Extensive experiments on challenging unstructured tabular benchmarks verify the effectiveness and highlight the necessity of separating strategic planning from low-level execution for long-horizon tabular reasoning.
Graph-based Agent Memory: Taxonomy, Techniques, and Applications
Feb 05, 2026Memory emerges as the core module in the Large Language Model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. Among diverse paradigms, graph stands out as a powerful structure for agent memory due to the intrinsic capabilities to model relational dependencies, organize hierarchical information, and support efficient retrieval. This survey presents a comprehensive review of agent memory from the graph-based perspective. First, we introduce a taxonomy of agent memory, including short-term vs. long-term memory, knowledge vs. experience memory, non-structural vs. structural memory, with an implementation view of graph-based memory. Second, according to the life cycle of agent memory, we systematically analyze the key techniques in graph-based agent memory, covering memory extraction for transforming the data into the contents, storage for organizing the data efficiently, retrieval for retrieving the relevant contents from memory to support reasoning, and evolution for updating the contents in the memory. Third, we summarize the open-sourced libraries and benchmarks that support the development and evaluation of self-evolving agent memory. We also explore diverse application scenarios. Finally, we identify critical challenges and future research directions. This survey aims to offer actionable insights to advance the development of more efficient and reliable graph-based agent memory systems. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/DEEP-PolyU/Awesome-GraphMemory.
Use Graph When It Needs: Efficiently and Adaptively Integrating Retrieval-Augmented Generation with Graphs
Feb 03, 2026Large language models (LLMs) often struggle with knowledge-intensive tasks due to hallucinations and outdated parametric knowledge. While Retrieval-Augmented Generation (RAG) addresses this by integrating external corpora, its effectiveness is limited by fragmented information in unstructured domain documents. Graph-augmented RAG (GraphRAG) emerged to enhance contextual reasoning through structured knowledge graphs, yet paradoxically underperforms vanilla RAG in real-world scenarios, exhibiting significant accuracy drops and prohibitive latency despite gains on complex queries. We identify the rigid application of GraphRAG to all queries, regardless of complexity, as the root cause. To resolve this, we propose an efficient and adaptive GraphRAG framework called EA-GraphRAG that dynamically integrates RAG and GraphRAG paradigms through syntax-aware complexity analysis. Our approach introduces: (i) a syntactic feature constructor that parses each query and extracts a set of structural features; (ii) a lightweight complexity scorer that maps these features to a continuous complexity score; and (iii) a score-driven routing policy that selects dense RAG for low-score queries, invokes graph-based retrieval for high-score queries, and applies complexity-aware reciprocal rank fusion to handle borderline cases. Extensive experiments on a comprehensive benchmark, consisting of two single-hop and two multi-hop QA benchmarks, demonstrate that our EA-GraphRAG significantly improves accuracy, reduces latency, and achieves state-of-the-art performance in handling mixed scenarios involving both simple and complex queries.
You Don't Need Pre-built Graphs for RAG: Retrieval Augmented Generation with Adaptive Reasoning Structures
Aug 08, 2025Large language models (LLMs) often suffer from hallucination, generating factually incorrect statements when handling questions beyond their knowledge and perception. Retrieval-augmented generation (RAG) addresses this by retrieving query-relevant contexts from knowledge bases to support LLM reasoning. Recent advances leverage pre-constructed graphs to capture the relational connections among distributed documents, showing remarkable performance in complex tasks. However, existing Graph-based RAG (GraphRAG) methods rely on a costly process to transform the corpus into a graph, introducing overwhelming token cost and update latency. Moreover, real-world queries vary in type and complexity, requiring different logic structures for accurate reasoning. The pre-built graph may not align with these required structures, resulting in ineffective knowledge retrieval. To this end, we propose a \textbf{\underline{Logic}}-aware \textbf{\underline{R}}etrieval-\textbf{\underline{A}}ugmented \textbf{\underline{G}}eneration framework (\textbf{LogicRAG}) that dynamically extracts reasoning structures at inference time to guide adaptive retrieval without any pre-built graph. LogicRAG begins by decomposing the input query into a set of subproblems and constructing a directed acyclic graph (DAG) to model the logical dependencies among them. To support coherent multi-step reasoning, LogicRAG then linearizes the graph using topological sort, so that subproblems can be addressed in a logically consistent order. Besides, LogicRAG applies graph pruning to reduce redundant retrieval and uses context pruning to filter irrelevant context, significantly reducing the overall token cost. Extensive experiments demonstrate that LogicRAG achieves both superior performance and efficiency compared to state-of-the-art baselines.
LAG: Logic-Augmented Generation from a Cartesian Perspective
Aug 07, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet exhibit critical limitations in knowledge-intensive tasks, often generating hallucinations when faced with questions requiring specialized expertise. While retrieval-augmented generation (RAG) mitigates this by integrating external knowledge, it struggles with complex reasoning scenarios due to its reliance on direct semantic retrieval and lack of structured logical organization. Inspired by Cartesian principles from \textit{Discours de la m\'ethode}, this paper introduces Logic-Augmented Generation (LAG), a novel paradigm that reframes knowledge augmentation through systematic question decomposition and dependency-aware reasoning. Specifically, LAG first decomposes complex questions into atomic sub-questions ordered by logical dependencies. It then resolves these sequentially, using prior answers to guide context retrieval for subsequent sub-questions, ensuring stepwise grounding in logical chain. To prevent error propagation, LAG incorporates a logical termination mechanism that halts inference upon encountering unanswerable sub-questions and reduces wasted computation on excessive reasoning. Finally, it synthesizes all sub-resolutions to generate verified responses. Experiments on four benchmark datasets demonstrate that LAG significantly enhances reasoning robustness, reduces hallucination, and aligns LLM problem-solving with human cognition, offering a principled alternative to existing RAG systems.
Reliable Reasoning Path: Distilling Effective Guidance for LLM Reasoning with Knowledge Graphs
Jun 12, 2025Large language models (LLMs) often struggle with knowledge-intensive tasks due to a lack of background knowledge and a tendency to hallucinate. To address these limitations, integrating knowledge graphs (KGs) with LLMs has been intensively studied. Existing KG-enhanced LLMs focus on supplementary factual knowledge, but still struggle with solving complex questions. We argue that refining the relationships among facts and organizing them into a logically consistent reasoning path is equally important as factual knowledge itself. Despite their potential, extracting reliable reasoning paths from KGs poses the following challenges: the complexity of graph structures and the existence of multiple generated paths, making it difficult to distinguish between useful and redundant ones. To tackle these challenges, we propose the RRP framework to mine the knowledge graph, which combines the semantic strengths of LLMs with structural information obtained through relation embedding and bidirectional distribution learning. Additionally, we introduce a rethinking module that evaluates and refines reasoning paths according to their significance. Experimental results on two public datasets show that RRP achieves state-of-the-art performance compared to existing baseline methods. Moreover, RRP can be easily integrated into various LLMs to enhance their reasoning abilities in a plug-and-play manner. By generating high-quality reasoning paths tailored to specific questions, RRP distills effective guidance for LLM reasoning.
Graph-defined Language Learning with LLMs
Jan 20, 2025



Recent efforts leverage Large Language Models (LLMs) for modeling text-attributed graph structures in node classification tasks. These approaches describe graph structures for LLMs to understand or aggregate LLM-generated textual attribute embeddings through graph structure. However, these approaches face two main limitations in modeling graph structures with LLMs. (i) Graph descriptions become verbose in describing high-order graph structure. (ii) Textual attributes alone do not contain adequate graph structure information. It is challenging to model graph structure concisely and adequately with LLMs. LLMs lack built-in mechanisms to model graph structures directly. They also struggle with complex long-range dependencies between high-order nodes and target nodes. Inspired by the observation that LLMs pre-trained on one language can achieve exceptional performance on another with minimal additional training, we propose \textbf{G}raph-\textbf{D}efined \textbf{L}anguage for \textbf{L}arge \textbf{L}anguage \textbf{M}odel (GDL4LLM). This novel framework enables LLMs to transfer their powerful language understanding capabilities to graph-structured data. GDL4LLM translates graphs into a graph language corpus instead of graph descriptions and pre-trains LLMs on this corpus to adequately understand graph structures. During fine-tuning, this corpus describes the structural information of target nodes concisely with only a few tokens. By treating graphs as a new language, GDL4LLM enables LLMs to model graph structures adequately and concisely for node classification tasks. Extensive experiments on three real-world datasets demonstrate that GDL4LLM outperforms description-based and textual attribute embeddings-based baselines by efficiently modeling different orders of graph structure with LLMs.
Cost-efficient Knowledge-based Question Answering with Large Language Models
May 27, 2024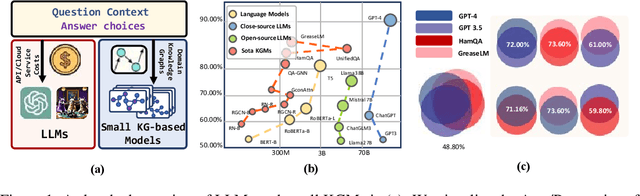
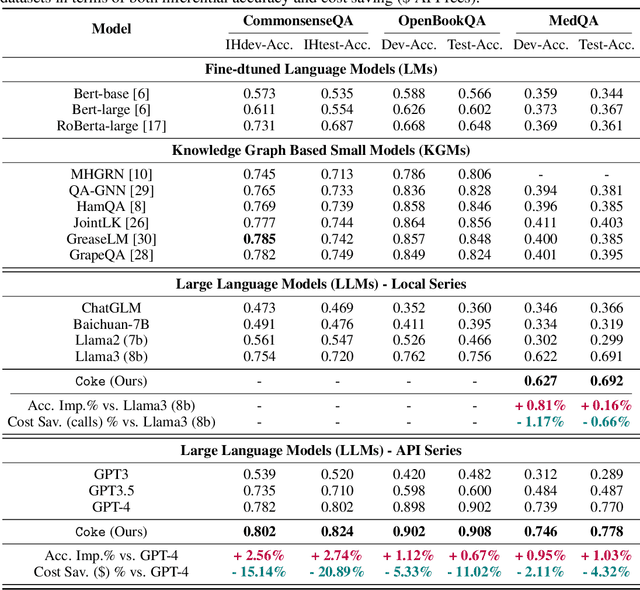
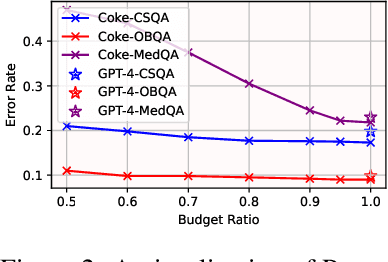
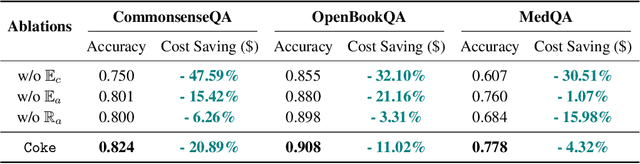
Knowledge-based question answering (KBQA) is widely used in many scenarios that necessitate domain knowledge. Large language models (LLMs) bring opportunities to KBQA, while their costs are significantly higher and absence of domain-specific knowledge during pre-training. We are motivated to combine LLMs and prior small models on knowledge graphs (KGMs) for both inferential accuracy and cost saving. However, it remains challenging since accuracy and cost are not readily combined in the optimization as two distinct metrics. It is also laborious for model selection since different models excel in diverse knowledge. To this end, we propose Coke, a novel cost-efficient strategy for KBQA with LLMs, modeled as a tailored multi-armed bandit problem to minimize calls to LLMs within limited budgets. We first formulate the accuracy expectation with a cluster-level Thompson Sampling for either KGMs or LLMs. A context-aware policy is optimized to further distinguish the expert model subject to the question semantics. The overall decision is bounded by the cost regret according to historical expenditure on failures. Extensive experiments showcase the superior performance of Coke, which moves the Pareto frontier with up to 20.89% saving of GPT-4 fees while achieving a 2.74% higher accuracy on the benchmark datasets.