 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-MLLM: Harnessing Multimodal Large Language Models for Multimodal Graph Learning
Jun 12, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in representing and understanding diverse modalities. However, they typically focus on modality alignment in a pairwise manner while overlooking structural relationships across data points. Integrating multimodality with structured graph information (i.e., multimodal graphs, MMGs) is essential for real-world applications such as social networks, healthcare, and recommendation systems. Existing MMG learning methods fall into three paradigms based on how they leverage MLLMs: Encoder, Aligner, and Predictor. MLLM-as-Encoder focuses on enhancing graph neural networks (GNNs) via multimodal feature fusion; MLLM-as-Aligner aligns multimodal attributes in language or hidden space to enable LLM-based graph reasoning; MLLM-as-Predictor treats MLLMs as standalone reasoners with in-context learning or fine-tuning. Despite their advances, the MMG field lacks a unified benchmark to fairly evaluate across these approaches, making it unclear what progress has been made. To bridge this gap, we present Graph-MLLM, a comprehensive benchmark for multimodal graph learning by systematically evaluating these three paradigms across six datasets with different domains. Through extensive experiments, we observe that jointly considering the visual and textual attributes of the nodes benefits graph learning, even when using pre-trained text-to-image alignment models (e.g., CLIP) as encoders. We also find that converting visual attributes into textual descriptions further improves performance compared to directly using visual inputs. Moreover, we observe that fine-tuning MLLMs on specific MMGs can achieve state-of-the-art results in most scenarios, even without explicit graph structure information. We hope that our open-sourced library will facilitate rapid, equitable evaluation and inspire further innovative research in this field.
FinLoRA: Benchmarking LoRA Methods for Fine-Tuning LLMs on Financial Datasets
May 26, 2025Low-rank adaptation (LoRA) methods show great potential for scaling pre-trained general-purpose Large Language Models (LLMs) to hundreds or thousands of use scenarios. However, their efficacy in high-stakes domains like finance is rarely explored, e.g., passing CFA exams and analyzing SEC filings. In this paper, we present the open-source FinLoRA project that benchmarks LoRA methods on both general and highly professional financial tasks. First, we curated 19 datasets covering diverse financial applications; in particular, we created four novel XBRL analysis datasets based on 150 SEC filings. Second, we evaluated five LoRA methods and five base LLMs. Finally, we provide extensive experimental results in terms of accuracy, F1, and BERTScore and report computational cost in terms of time and GPU memory during fine-tuning and inference stages. We find that LoRA methods achieved substantial performance gains of 36\% on average over base models. Our FinLoRA project provides an affordable and scalable approach to democratize financial intelligence to the general public. Datasets, LoRA adapters, code, and documentation are available at https://github.com/Open-Finance-Lab/FinLoRA
Beyond Pairwise Learning-To-Rank At Airbnb
May 14, 2025There are three fundamental asks from a ranking algorithm: it should scale to handle a large number of items, sort items accurately by their utility, and impose a total order on the items for logical consistency. But here's the catch-no algorithm can achieve all three at the same time. We call this limitation the SAT theorem for ranking algorithms. Given the dilemma, how can we design a practical system that meets user needs? Our current work at Airbnb provides an answer, with a working solution deployed at scale. We start with pairwise learning-to-rank (LTR) models-the bedrock of search ranking tech stacks today. They scale linearly with the number of items ranked and perform strongly on metrics like NDCG by learning from pairwise comparisons. They are at a sweet spot of performance vs. cost, making them an ideal choice for several industrial applications. However, they have a drawback-by ignoring interactions between items, they compromise on accuracy. To improve accuracy, we create a "true" pairwise LTR model-one that captures interactions between items during pairwise comparisons. But accuracy comes at the expense of scalability and total order, and we discuss strategies to counter these challenges. For greater accuracy, we take each item in the search result, and compare it against the rest of the items along two dimensions: (1) Superiority: How strongly do searchers prefer the given item over the remaining ones? (2) Similarity: How similar is the given item to all the other items? This forms the basis of our "all-pairwise" LTR framework, which factors in interactions across all items at once. Looking at items on the search result page all together-superiority and similarity combined-gives us a deeper understanding of what searchers truly want. We quantify the resulting improvements in searcher experience through offline and online experiments at Airbnb.
Large Language Models for Disease Diagnosis: A Scoping Review
Aug 27, 2024Automatic disease diagnosis has become increasingly valuable in clinical practice. The advent of large language models (LLMs) has catalyzed a paradigm shift in artificial intelligence, with growing evidence supporting the efficacy of LLMs in diagnostic tasks. Despite the growing attention in this field, many critical research questions remain under-explored. For instance, what diseases and LLM techniques have been investigated for diagnostic tasks? How can suitable LLM techniques and evaluation methods be selected for clinical decision-making? To answer these questions, we performed a comprehensive analysis of LLM-based methods for disease diagnosis. This scoping review examined the types of diseases, associated organ systems, relevant clinical data, LLM techniques, and evaluation methods reported in existing studies. Furthermore, we offered guidelines for data preprocessing and the selection of appropriate LLM techniques and evaluation strategies for diagnostic tasks. We also assessed the limitations of current research and delineated the challenges and future directions in this research field. In summary, our review outlined a blueprint for LLM-based disease diagnosis, helping to streamline and guide future research endeavors.
Understanding Different Design Choices in Training Large Time Series Models
Jun 20, 2024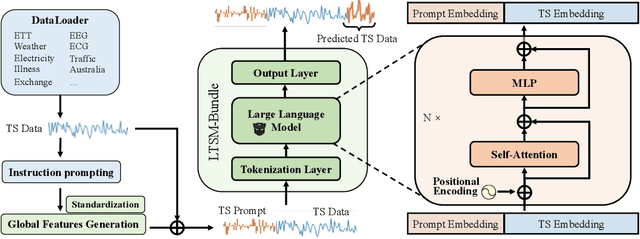
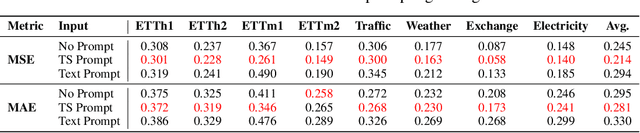

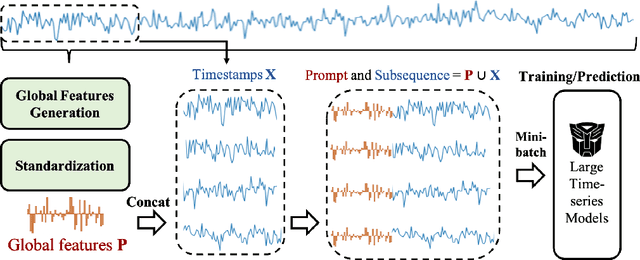
Inspired by Large Language Models (LLMs), Time Series Forecasting (TSF), a long-standing task in time series analysis, is undergoing a transition towards Large Time Series Models (LTSMs), aiming to train universal transformer-based models for TSF. However, training LTSMs on heterogeneous time series data poses unique challenges, including diverse frequencies, dimensions, and patterns across datasets. Recent endeavors have studied and evaluated various design choices aimed at enhancing LTSM training and generalization capabilities, spanning pre-processing techniques, model configurations, and dataset configurations. In this work, we comprehensively analyze these design choices and aim to identify the best practices for training LTSM. Moreover, we propose \emph{time series prompt}, a novel statistical prompting strategy tailored to time series data. Furthermore, based on the observations in our analysis, we introduce \texttt{LTSM-bundle}, which bundles the best design choices we have identified. Empirical results demonstrate that \texttt{LTSM-bundle} achieves superior zero-shot and few-shot performances compared to state-of-the-art LSTMs and traditional TSF methods on benchmark datasets.
GAugLLM: Improving Graph Contrastive Learning for Text-Attributed Graphs with Large Language Models
Jun 17, 2024



This work studies self-supervised graph learning for text-attributed graphs (TAGs) where nodes are represented by textual attributes. Unlike traditional graph contrastive methods that perturb the numerical feature space and alter the graph's topological structure, we aim to improve view generation through language supervision. This is driven by the prevalence of textual attributes in real applications, which complement graph structures with rich semantic information. However, this presents challenges because of two major reasons. First, text attributes often vary in length and quality, making it difficulty to perturb raw text descriptions without altering their original semantic meanings. Second, although text attributes complement graph structures, they are not inherently well-aligned. To bridge the gap, we introduce GAugLLM, a novel framework for augmenting TAGs. It leverages advanced large language models like Mistral to enhance self-supervised graph learning. Specifically, we introduce a mixture-of-prompt-expert technique to generate augmented node features. This approach adaptively maps multiple prompt experts, each of which modifies raw text attributes using prompt engineering, into numerical feature space. Additionally, we devise a collaborative edge modifier to leverage structural and textual commonalities, enhancing edge augmentation by examining or building connections between nodes. Empirical results across five benchmark datasets spanning various domains underscore our framework's ability to enhance the performance of leading contrastive methods as a plug-in tool. Notably, we observe that the augmented features and graph structure can also enhance the performance of standard generative methods, as well as popular graph neural networks. The open-sourced implementation of our GAugLLM is available at Github.
GraphFM: A Comprehensive Benchmark for Graph Foundation Model
Jun 12, 2024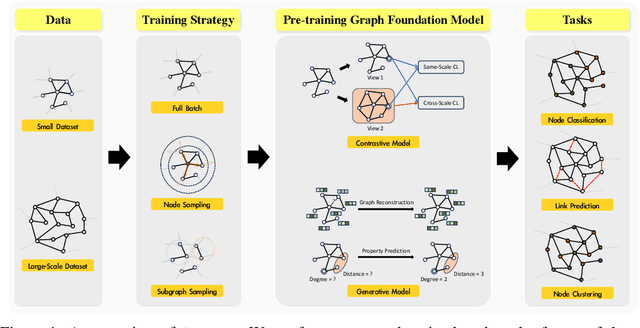
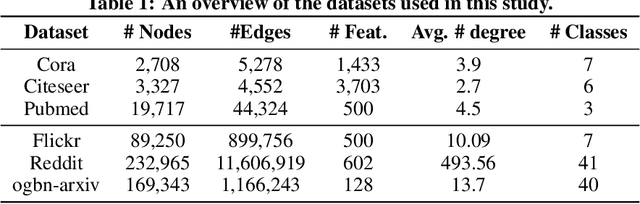
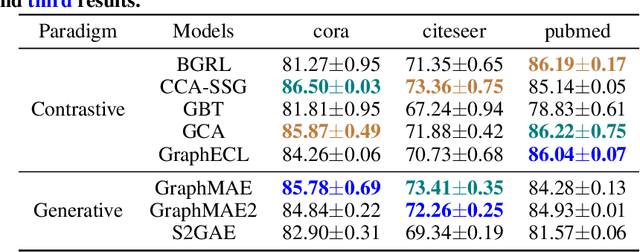
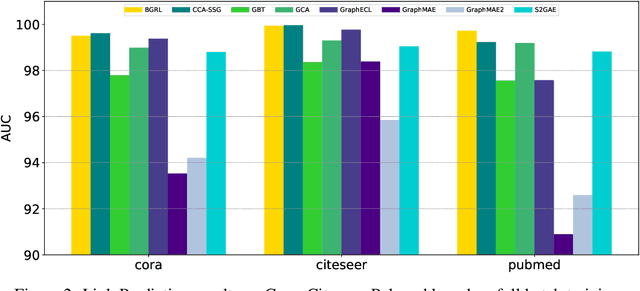
Foundation Models (FMs) serve as a general class for the development of artificial intelligence systems, offering broad potential for generalization across a spectrum of downstream tasks. Despite extensive research into self-supervised learning as the cornerstone of FMs, several outstanding issues persist in Graph Foundation Models that rely on graph self-supervised learning, namely: 1) Homogenization. The extent of generalization capability on downstream tasks remains unclear. 2) Scalability. It is unknown how effectively these models can scale to large datasets. 3) Efficiency. The training time and memory usage of these models require evaluation. 4) Training Stop Criteria. Determining the optimal stopping strategy for pre-training across multiple tasks to maximize performance on downstream tasks. To address these questions, we have constructed a rigorous benchmark that thoroughly analyzes and studies the generalization and scalability of self-supervised Graph Neural Network (GNN) models. Regarding generalization, we have implemented and compared the performance of various self-supervised GNN models, trained to generate node representations, across tasks such as node classification, link prediction, and node clustering. For scalability, we have compared the performance of various models after training using full-batch and mini-batch strategies. Additionally, we have assessed the training efficiency of these models by conducting experiments to test their GPU memory usage and throughput. Through these experiments, we aim to provide insights to motivate future research. The code for this benchmark is publicly available at https://github.com/NYUSHCS/GraphFM.
Denoising-Aware Contrastive Learning for Noisy Time Series
Jun 07, 2024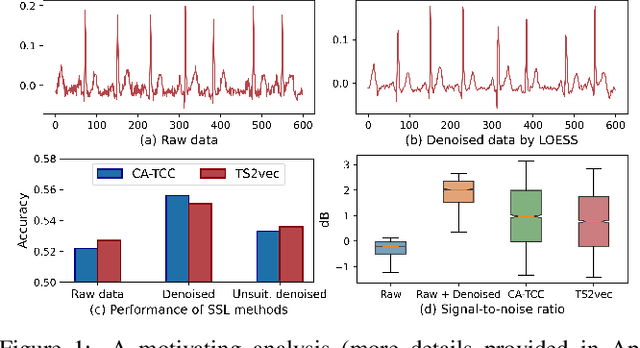



Time series self-supervised learning (SSL) aims to exploit unlabeled data for pre-training to mitigate the reliance on labels. Despite the great success in recent years, there is limited discussion on the potential noise in the time series, which can severely impair the performance of existing SSL methods. To mitigate the noise, the de facto strategy is to apply conventional denoising methods before model training. However, this pre-processing approach may not fully eliminate the effect of noise in SSL for two reasons: (i) the diverse types of noise in time series make it difficult to automatically determine suitable denoising methods; (ii) noise can be amplified after mapping raw data into latent space. In this paper, we propose denoising-aware contrastive learning (DECL), which uses contrastive learning objectives to mitigate the noise in the representation and automatically selects suitable denoising methods for every sample. Extensive experiments on various datasets verify the effectiveness of our method. The code is open-sourced.
Cost-efficient Knowledge-based Question Answering with Large Language Models
May 27, 2024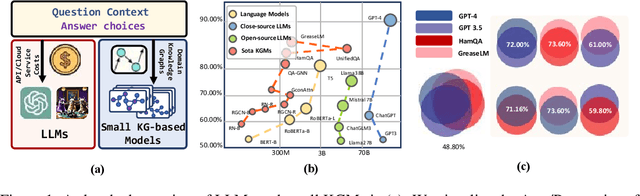
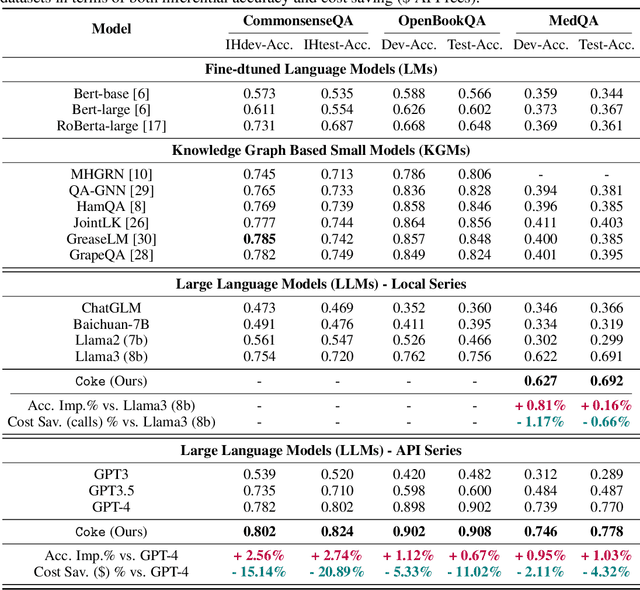
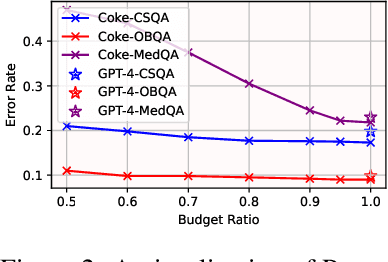
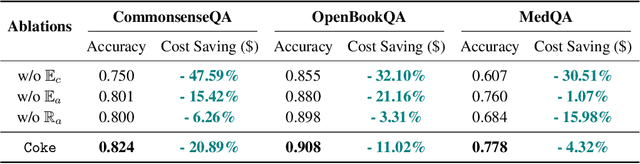
Knowledge-based question answering (KBQA) is widely used in many scenarios that necessitate domain knowledge. Large language models (LLMs) bring opportunities to KBQA, while their costs are significantly higher and absence of domain-specific knowledge during pre-training. We are motivated to combine LLMs and prior small models on knowledge graphs (KGMs) for both inferential accuracy and cost saving. However, it remains challenging since accuracy and cost are not readily combined in the optimization as two distinct metrics. It is also laborious for model selection since different models excel in diverse knowledge. To this end, we propose Coke, a novel cost-efficient strategy for KBQA with LLMs, modeled as a tailored multi-armed bandit problem to minimize calls to LLMs within limited budgets. We first formulate the accuracy expectation with a cluster-level Thompson Sampling for either KGMs or LLMs. A context-aware policy is optimized to further distinguish the expert model subject to the question semantics. The overall decision is bounded by the cost regret according to historical expenditure on failures. Extensive experiments showcase the superior performance of Coke, which moves the Pareto frontier with up to 20.89% saving of GPT-4 fees while achieving a 2.74% higher accuracy on the benchmark datasets.
E2GNN: Efficient Graph Neural Network Ensembles for Semi-Supervised Classification
May 06, 2024


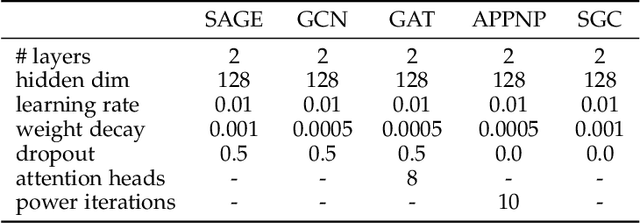
This work studies ensemble learning for graph neural networks (GNNs) under the popular semi-supervised setting. Ensemble learning has shown superiority in improving the accuracy and robustness of traditional machine learning by combining the outputs of multiple weak learners. However, adopting a similar idea to integrate different GNN models is challenging because of two reasons. First, GNN is notorious for its poor inference ability, so naively assembling multiple GNN models would deteriorate the inference efficiency. Second, when GNN models are trained with few labeled nodes, their performance are limited. In this case, the vanilla ensemble approach, e.g., majority vote, may be sub-optimal since most base models, i.e., GNNs, may make the wrong predictions. To this end, in this paper, we propose an efficient ensemble learner--E2GNN to assemble multiple GNNs in a learnable way by leveraging both labeled and unlabeled nodes. Specifically, we first pre-train different GNN models on a given data scenario according to the labeled nodes. Next, instead of directly combing their outputs for label inference, we train a simple multi-layer perceptron--MLP model to mimic their predictions on both labeled and unlabeled nodes. Then the unified MLP model is deployed to infer labels for unlabeled or new nodes. Since the predictions of unlabeled nodes from different GNN models may be incorrect, we develop a reinforced discriminator to effectively filter out those wrongly predicted nodes to boost the performance of MLP. By doing this, we suggest a principled approach to tackle the inference issues of GNN ensembles and maintain the merit of ensemble learning: improved performance. Comprehensive experiments over both transductive and inductive settings, across different GNN backbones and 8 benchmark datasets, demonstrate the superiority of E2GNN.