 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Agent Memory: Taxonomy, Techniques, and Applications
Feb 05, 2026Memory emerges as the core module in the Large Language Model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. Among diverse paradigms, graph stands out as a powerful structure for agent memory due to the intrinsic capabilities to model relational dependencies, organize hierarchical information, and support efficient retrieval. This survey presents a comprehensive review of agent memory from the graph-based perspective. First, we introduce a taxonomy of agent memory, including short-term vs. long-term memory, knowledge vs. experience memory, non-structural vs. structural memory, with an implementation view of graph-based memory. Second, according to the life cycle of agent memory, we systematically analyze the key techniques in graph-based agent memory, covering memory extraction for transforming the data into the contents, storage for organizing the data efficiently, retrieval for retrieving the relevant contents from memory to support reasoning, and evolution for updating the contents in the memory. Third, we summarize the open-sourced libraries and benchmarks that support the development and evaluation of self-evolving agent memory. We also explore diverse application scenarios. Finally, we identify critical challenges and future research directions. This survey aims to offer actionable insights to advance the development of more efficient and reliable graph-based agent memory systems. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/DEEP-PolyU/Awesome-GraphMemory.
LoSemB: Logic-Guided Semantic Bridging for Inductive Tool Retrieval
Aug 11, 2025Tool learning has emerged as a promising paradigm for large language models (LLMs) to solve many real-world tasks. Nonetheless, with the tool repository rapidly expanding, it is impractical to contain all tools within the limited input length of LLMs. To alleviate these issues, researchers have explored incorporating a tool retrieval module to select the most relevant tools or represent tools as unique tokens within LLM parameters. However, most state-of-the-art methods are under transductive settings, assuming all tools have been observed during training. Such a setting deviates from reality as the real-world tool repository is evolving and incorporates new tools frequently. When dealing with these unseen tools, which refer to tools not encountered during the training phase, these methods are limited by two key issues, including the large distribution shift and the vulnerability of similarity-based retrieval. To this end, inspired by human cognitive processes of mastering unseen tools through discovering and applying the logical information from prior experience, we introduce a novel Logic-Guided Semantic Bridging framework for inductive tool retrieval, namely, LoSemB, which aims to mine and transfer latent logical information for inductive tool retrieval without costly retraining. Specifically, LoSemB contains a logic-based embedding alignment module to mitigate distribution shifts and implements a relational augmented retrieval mechanism to reduce the vulnerability of similarity-based retrieval. Extensive experiments demonstrate that LoSemB achieves advanced performance in inductive settings while maintaining desirable effectiveness in the transductive setting.
Graph-defined Language Learning with LLMs
Jan 20, 2025



Recent efforts leverage Large Language Models (LLMs) for modeling text-attributed graph structures in node classification tasks. These approaches describe graph structures for LLMs to understand or aggregate LLM-generated textual attribute embeddings through graph structure. However, these approaches face two main limitations in modeling graph structures with LLMs. (i) Graph descriptions become verbose in describing high-order graph structure. (ii) Textual attributes alone do not contain adequate graph structure information. It is challenging to model graph structure concisely and adequately with LLMs. LLMs lack built-in mechanisms to model graph structures directly. They also struggle with complex long-range dependencies between high-order nodes and target nodes. Inspired by the observation that LLMs pre-trained on one language can achieve exceptional performance on another with minimal additional training, we propose \textbf{G}raph-\textbf{D}efined \textbf{L}anguage for \textbf{L}arge \textbf{L}anguage \textbf{M}odel (GDL4LLM). This novel framework enables LLMs to transfer their powerful language understanding capabilities to graph-structured data. GDL4LLM translates graphs into a graph language corpus instead of graph descriptions and pre-trains LLMs on this corpus to adequately understand graph structures. During fine-tuning, this corpus describes the structural information of target nodes concisely with only a few tokens. By treating graphs as a new language, GDL4LLM enables LLMs to model graph structures adequately and concisely for node classification tasks. Extensive experiments on three real-world datasets demonstrate that GDL4LLM outperforms description-based and textual attribute embeddings-based baselines by efficiently modeling different orders of graph structure with LLMs.
Modality-Aware Integration with Large Language Models for Knowledge-based Visual Question Answering
Feb 20, 2024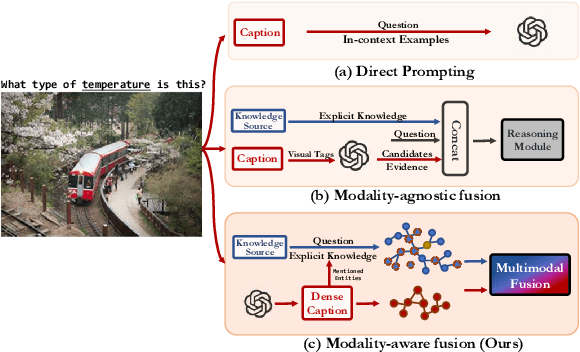
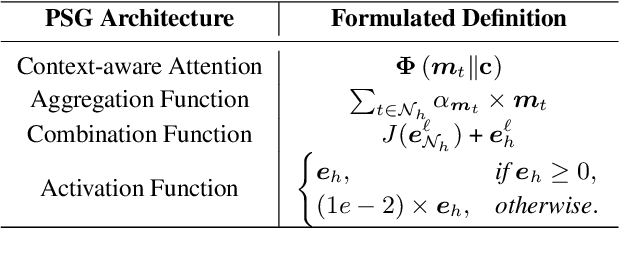
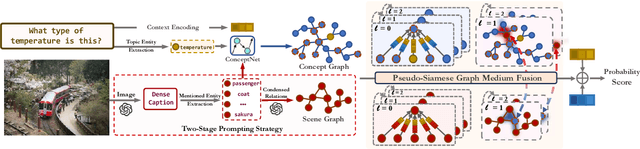
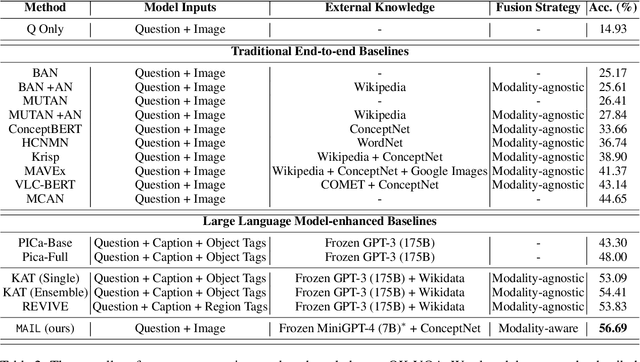
Knowledge-based visual question answering (KVQA) has been extensively studied to answer visual questions with external knowledge, e.g., knowledge graphs (KGs). While several attempts have been proposed to leverage large language models (LLMs) as an implicit knowledge source, it remains challenging since LLMs may generate hallucinations. Moreover, multiple knowledge sources, e.g., images, KGs and LLMs, cannot be readily aligned for complex scenarios. To tackle these, we present a novel modality-aware integration with LLMs for KVQA (MAIL). It carefully leverages multimodal knowledge for both image understanding and knowledge reasoning. Specifically, (i) we propose a two-stage prompting strategy with LLMs to densely embody the image into a scene graph with detailed visual features; (ii) We construct a coupled concept graph by linking the mentioned entities with external facts. (iii) A tailored pseudo-siamese graph medium fusion is designed for sufficient multimodal fusion. We utilize the shared mentioned entities in two graphs as mediums to bridge a tight inter-modal exchange, while maximally preserving insightful intra-modal learning by constraining the fusion within mediums. Extensive experiments on two benchmark datasets show the superiority of MAIL with 24x less resources.
Towards Personalized Cold-Start Recommendation with Prompts
Jul 05, 2023Recommender systems play a crucial role in helping users discover information that aligns with their interests based on their past behaviors. However, developing personalized recommendation systems becomes challenging when historical records of user-item interactions are unavailable, leading to what is known as the system cold-start recommendation problem. This issue is particularly prominent in start-up businesses or platforms with insufficient user engagement history. Previous studies focus on user or item cold-start scenarios, where systems could make recommendations for new users or items but are still trained with historical user-item interactions in the same domain, which cannot solve our problem. To bridge the gap, our research introduces an innovative and effective approach, capitalizing on the capabilities of pre-trained language models. We transform the recommendation process into sentiment analysis of natural languages containing information of user profiles and item attributes, where the sentiment polarity is predicted with prompt learning. By harnessing the extensive knowledge housed within language models, the prediction can be made without historical user-item interaction records. A benchmark is also introduced to evaluate the proposed method under the cold-start setting, and the results demonstrate the effectiveness of our method. To the best of our knowledge, this is the first study to tackle the system cold-start recommendation problem. The benchmark and implementation of the method are available at https://github.com/JacksonWuxs/PromptRec.
Improving Generalizability of Graph Anomaly Detection Models via Data Augmentation
Jun 18, 2023Graph anomaly detection (GAD) is a vital task since even a few anomalies can pose huge threats to benign users. Recent semi-supervised GAD methods, which can effectively leverage the available labels as prior knowledge, have achieved superior performances than unsupervised methods. In practice, people usually need to identify anomalies on new (sub)graphs to secure their business, but they may lack labels to train an effective detection model. One natural idea is to directly adopt a trained GAD model to the new (sub)graph for testing. However, we find that existing semi-supervised GAD methods suffer from poor generalization issue, i.e., well-trained models could not perform well on an unseen area (i.e., not accessible in training) of the same graph. It may cause great troubles. In this paper, we base on the phenomenon and propose a general and novel research problem of generalized graph anomaly detection that aims to effectively identify anomalies on both the training-domain graph and unseen testing graph to eliminate potential dangers. Nevertheless, it is a challenging task since only limited labels are available, and the normal background may differ between training and testing data. Accordingly, we propose a data augmentation method named \textit{AugAN} (\uline{Aug}mentation for \uline{A}nomaly and \uline{N}ormal distributions) to enrich training data and boost the generalizability of GAD models. Experiments verify the effectiveness of our method in improving model generalizability.
* Accepted to IEEE Transactions on Knowledge and Data Engineering (TKDE). arXiv admin note: substantial text overlap with arXiv:2209.10168