 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
MeCaMIL: Causality-Aware Multiple Instance Learning for Fair and Interpretable Whole Slide Image Diagnosis
Nov 14, 2025Multiple instance learning (MIL) has emerged as the dominant paradigm for whole slide image (WSI) analysis in computational pathology, achieving strong diagnostic performance through patch-level feature aggregation. However, existing MIL methods face critical limitations: (1) they rely on attention mechanisms that lack causal interpretability, and (2) they fail to integrate patient demographics (age, gender, race), leading to fairness concerns across diverse populations. These shortcomings hinder clinical translation, where algorithmic bias can exacerbate health disparities. We introduce \textbf{MeCaMIL}, a causality-aware MIL framework that explicitly models demographic confounders through structured causal graphs. Unlike prior approaches treating demographics as auxiliary features, MeCaMIL employs principled causal inference -- leveraging do-calculus and collider structures -- to disentangle disease-relevant signals from spurious demographic correlations. Extensive evaluation on three benchmarks demonstrates state-of-the-art performance across CAMELYON16 (ACC/AUC/F1: 0.939/0.983/0.946), TCGA-Lung (0.935/0.979/0.931), and TCGA-Multi (0.977/0.993/0.970, five cancer types). Critically, MeCaMIL achieves superior fairness -- demographic disparity variance drops by over 65% relative reduction on average across attributes, with notable improvements for underserved populations. The framework generalizes to survival prediction (mean C-index: 0.653, +0.017 over best baseline across five cancer types). Ablation studies confirm causal graph structure is essential -- alternative designs yield 0.048 lower accuracy and 4.2x times worse fairness. These results establish MeCaMIL as a principled framework for fair, interpretable, and clinically actionable AI in digital pathology. Code will be released upon acceptance.
AMO-Bench: Large Language Models Still Struggle in High School Math Competitions
Oct 30, 2025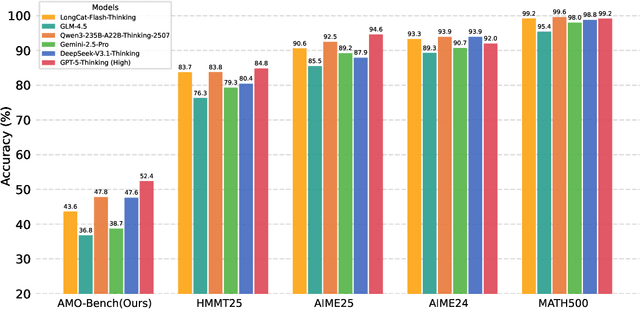
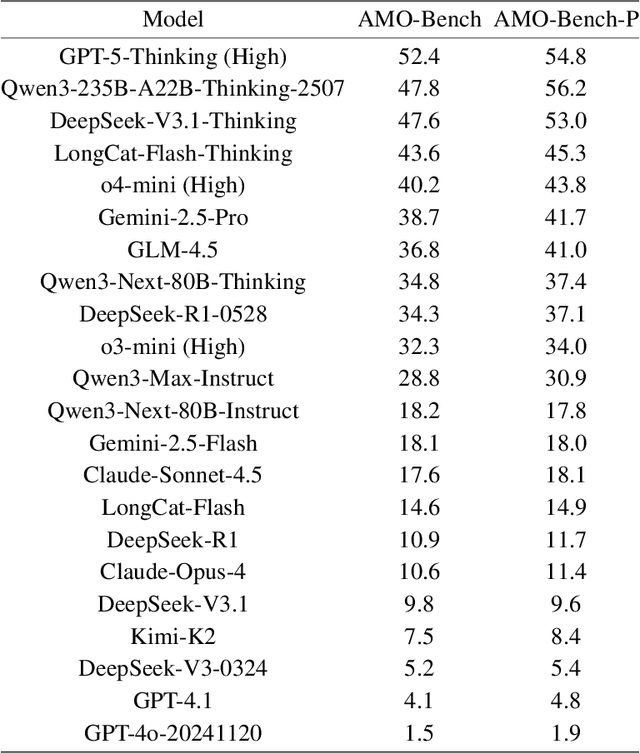
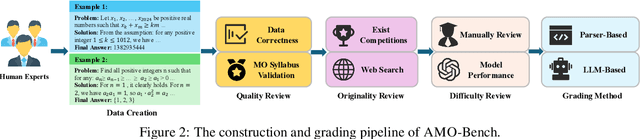
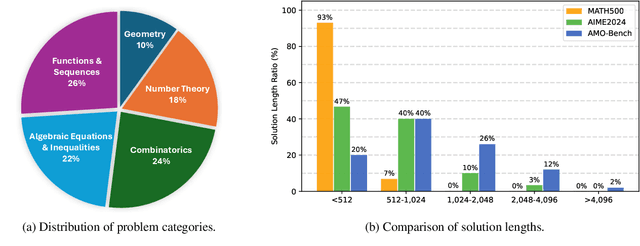
We present AMO-Bench, an Advanced Mathematical reasoning benchmark with Olympiad level or even higher difficulty, comprising 50 human-crafted problems. Existing benchmarks have widely leveraged high school math competitions for evaluating mathematical reasoning capabilities of large language models (LLMs). However, many existing math competitions are becoming less effective for assessing top-tier LLMs due to performance saturation (e.g., AIME24/25). To address this, AMO-Bench introduces more rigorous challenges by ensuring all 50 problems are (1) cross-validated by experts to meet at least the International Mathematical Olympiad (IMO) difficulty standards, and (2) entirely original problems to prevent potential performance leakages from data memorization. Moreover, each problem in AMO-Bench requires only a final answer rather than a proof, enabling automatic and robust grading for evaluation. Experimental results across 26 LLMs on AMO-Bench show that even the best-performing model achieves only 52.4% accuracy on AMO-Bench, with most LLMs scoring below 40%. Beyond these poor performances, our further analysis reveals a promising scaling trend with increasing test-time compute on AMO-Bench. These results highlight the significant room for improving the mathematical reasoning in current LLMs. We release AMO-Bench to facilitate further research into advancing the reasoning abilities of language models. https://amo-bench.github.io/
Automating Expert-Level Medical Reasoning Evaluation of Large Language Models
Jul 10, 2025As large language models (LLMs) become increasingly integrated into clinical decision-making, ensuring transparent and trustworthy reasoning is essential. However, existing evaluation strategies of LLMs' medical reasoning capability either suffer from unsatisfactory assessment or poor scalability, and a rigorous benchmark remains lacking. To address this, we introduce MedThink-Bench, a benchmark designed for rigorous, explainable, and scalable assessment of LLMs' medical reasoning. MedThink-Bench comprises 500 challenging questions across ten medical domains, each annotated with expert-crafted step-by-step rationales. Building on this, we propose LLM-w-Ref, a novel evaluation framework that leverages fine-grained rationales and LLM-as-a-Judge mechanisms to assess intermediate reasoning with expert-level fidelity while maintaining scalability. Experiments show that LLM-w-Ref exhibits a strong positive correlation with expert judgments. Benchmarking twelve state-of-the-art LLMs, we find that smaller models (e.g., MedGemma-27B) can surpass larger proprietary counterparts (e.g., OpenAI-o3). Overall, MedThink-Bench offers a foundational tool for evaluating LLMs' medical reasoning, advancing their safe and responsible deployment in clinical practice.
Uncertainty-Aware Large Language Models for Explainable Disease Diagnosis
May 06, 2025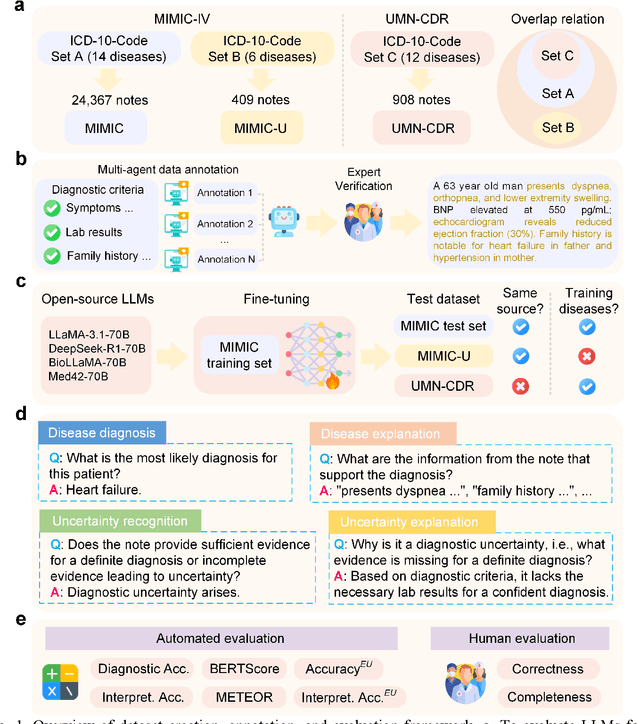
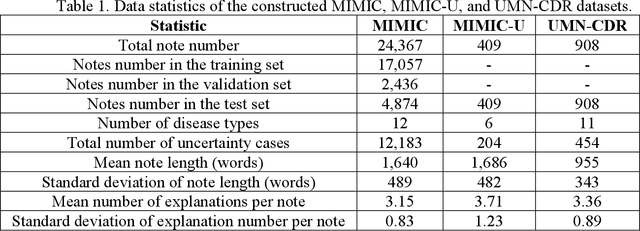

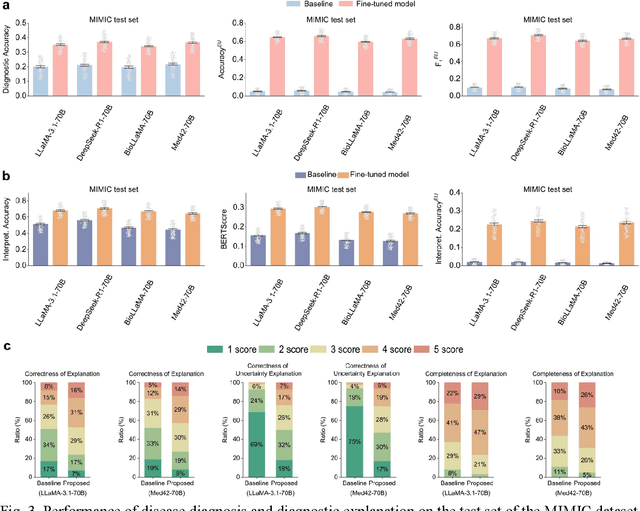
Explainable disease diagnosis, which leverages patient information (e.g., signs and symptoms) and computational models to generate probable diagnoses and reasonings, offers clear clinical values. However, when clinical notes encompass insufficient evidence for a definite diagnosis, such as the absence of definitive symptoms, diagnostic uncertainty usually arises, increasing the risk of misdiagnosis and adverse outcomes. Although explicitly identifying and explaining diagnostic uncertainties is essential for trustworthy diagnostic systems, it remains under-explored. To fill this gap, we introduce ConfiDx, an uncertainty-aware large language model (LLM) created by fine-tuning open-source LLMs with diagnostic criteria. We formalized the task and assembled richly annotated datasets that capture varying degrees of diagnostic ambiguity. Evaluating ConfiDx on real-world datasets demonstrated that it excelled in identifying diagnostic uncertainties, achieving superior diagnostic performance, and generating trustworthy explanations for diagnoses and uncertainties. To our knowledge, this is the first study to jointly address diagnostic uncertainty recognition and explanation, substantially enhancing the reliability of automatic diagnostic systems.
Retrieval-augmented in-context learning for multimodal large language models in disease classification
May 04, 2025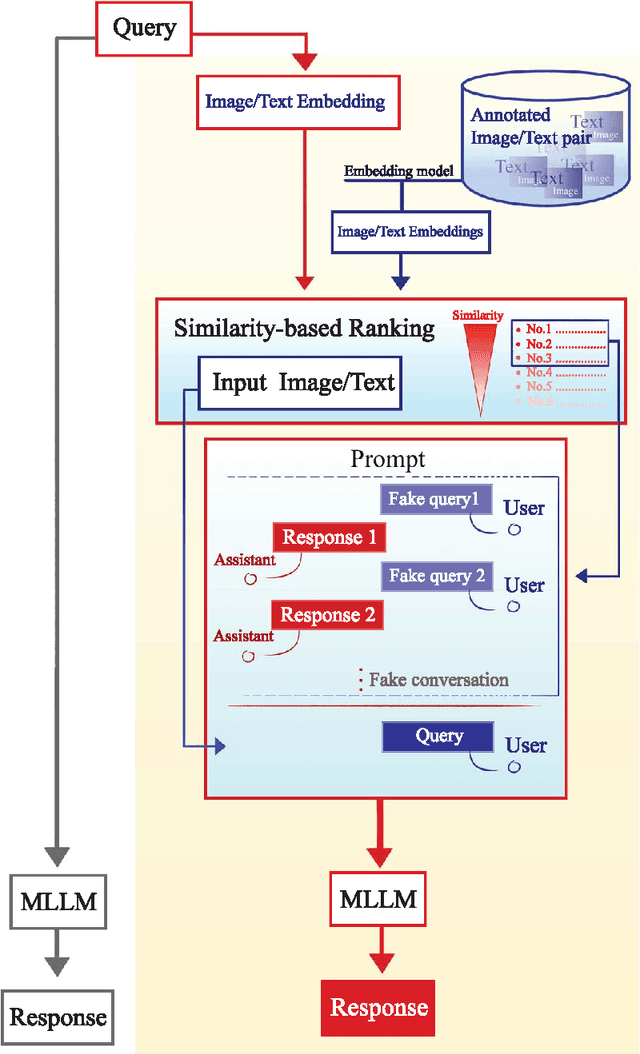
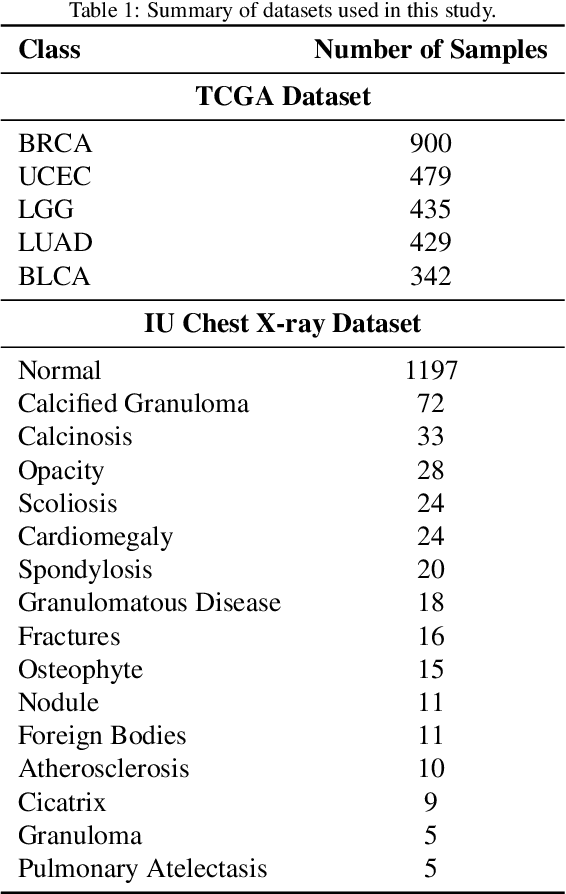
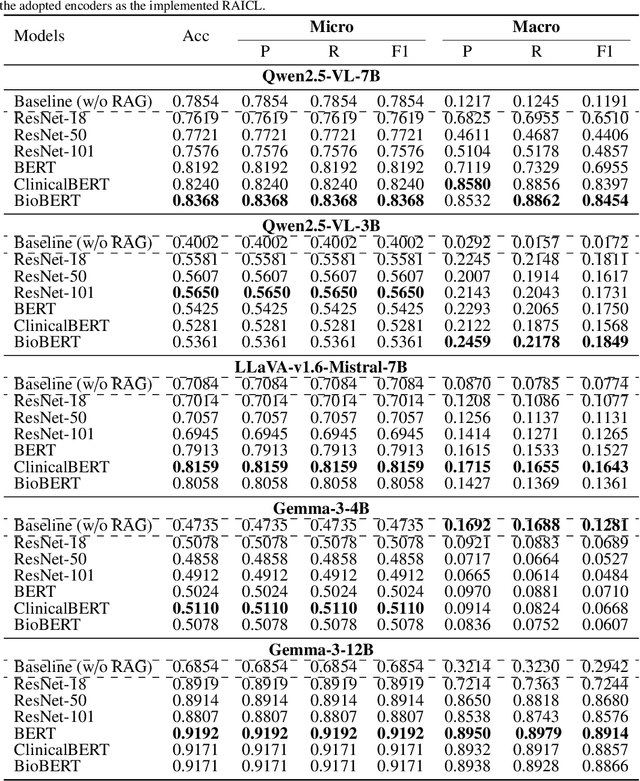
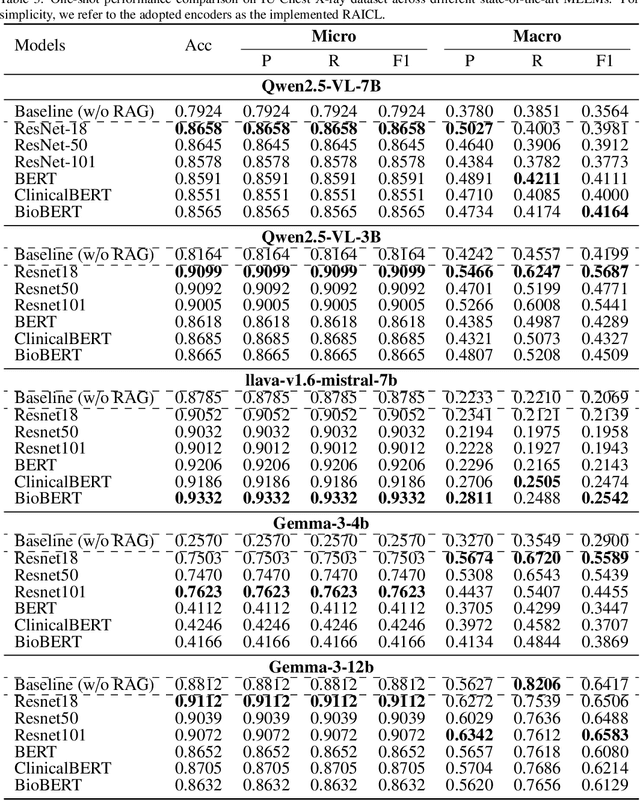
Objectives: We aim to dynamically retrieve informative demonstrations, enhancing in-context learning in multimodal large language models (MLLMs) for disease classification. Methods: We propose a Retrieval-Augmented In-Context Learning (RAICL) framework, which integrates retrieval-augmented generation (RAG) and in-context learning (ICL) to adaptively select demonstrations with similar disease patterns, enabling more effective ICL in MLLMs. Specifically, RAICL examines embeddings from diverse encoders, including ResNet, BERT, BioBERT, and ClinicalBERT, to retrieve appropriate demonstrations, and constructs conversational prompts optimized for ICL. We evaluated the framework on two real-world multi-modal datasets (TCGA and IU Chest X-ray), assessing its performance across multiple MLLMs (Qwen, Llava, Gemma), embedding strategies, similarity metrics, and varying numbers of demonstrations. Results: RAICL consistently improved classification performance. Accuracy increased from 0.7854 to 0.8368 on TCGA and from 0.7924 to 0.8658 on IU Chest X-ray. Multi-modal inputs outperformed single-modal ones, with text-only inputs being stronger than images alone. The richness of information embedded in each modality will determine which embedding model can be used to get better results. Few-shot experiments showed that increasing the number of retrieved examples further enhanced performance. Across different similarity metrics, Euclidean distance achieved the highest accuracy while cosine similarity yielded better macro-F1 scores. RAICL demonstrated consistent improvements across various MLLMs, confirming its robustness and versatility. Conclusions: RAICL provides an efficient and scalable approach to enhance in-context learning in MLLMs for multimodal disease classification.
EPEE: Towards Efficient and Effective Foundation Models in Biomedicine
Mar 03, 2025Foundation models, including language models, e.g., GPT, and vision models, e.g., CLIP, have significantly advanced numerous biomedical tasks. Despite these advancements, the high inference latency and the "overthinking" issues in model inference impair the efficiency and effectiveness of foundation models, thus limiting their application in real-time clinical settings. To address these challenges, we proposed EPEE (Entropy- and Patience-based Early Exiting), a novel hybrid strategy designed to improve the inference efficiency of foundation models. The core idea was to leverage the strengths of entropy-based and patience-based early exiting methods to overcome their respective weaknesses. To evaluate EPEE, we conducted experiments on three core biomedical tasks-classification, relation extraction, and event extraction-using four foundation models (BERT, ALBERT, GPT-2, and ViT) across twelve datasets, including clinical notes and medical images. The results showed that EPEE significantly reduced inference time while maintaining or improving accuracy, demonstrating its adaptability to diverse datasets and tasks. EPEE addressed critical barriers to deploying foundation models in healthcare by balancing efficiency and effectiveness. It potentially provided a practical solution for real-time clinical decision-making with foundation models, supporting reliable and efficient workflows.
MMRAG: Multi-Mode Retrieval-Augmented Generation with Large Language Models for Biomedical In-Context Learning
Feb 21, 2025



Objective: To optimize in-context learning in biomedical natural language processing by improving example selection. Methods: We introduce a novel multi-mode retrieval-augmented generation (MMRAG) framework, which integrates four retrieval strategies: (1) Random Mode, selecting examples arbitrarily; (2) Top Mode, retrieving the most relevant examples based on similarity; (3) Diversity Mode, ensuring variation in selected examples; and (4) Class Mode, selecting category-representative examples. This study evaluates MMRAG on three core biomedical NLP tasks: Named Entity Recognition (NER), Relation Extraction (RE), and Text Classification (TC). The datasets used include BC2GM for gene and protein mention recognition (NER), DDI for drug-drug interaction extraction (RE), GIT for general biomedical information extraction (RE), and HealthAdvice for health-related text classification (TC). The framework is tested with two large language models (Llama2-7B, Llama3-8B) and three retrievers (Contriever, MedCPT, BGE-Large) to assess performance across different retrieval strategies. Results: The results from the Random mode indicate that providing more examples in the prompt improves the model's generation performance. Meanwhile, Top mode and Diversity mode significantly outperform Random mode on the RE (DDI) task, achieving an F1 score of 0.9669, a 26.4% improvement. Among the three retrievers tested, Contriever outperformed the other two in a greater number of experiments. Additionally, Llama 2 and Llama 3 demonstrated varying capabilities across different tasks, with Llama 3 showing a clear advantage in handling NER tasks. Conclusion: MMRAG effectively enhances biomedical in-context learning by refining example selection, mitigating data scarcity issues, and demonstrating superior adaptability for NLP-driven healthcare applications.
Continually Evolved Multimodal Foundation Models for Cancer Prognosis
Jan 30, 2025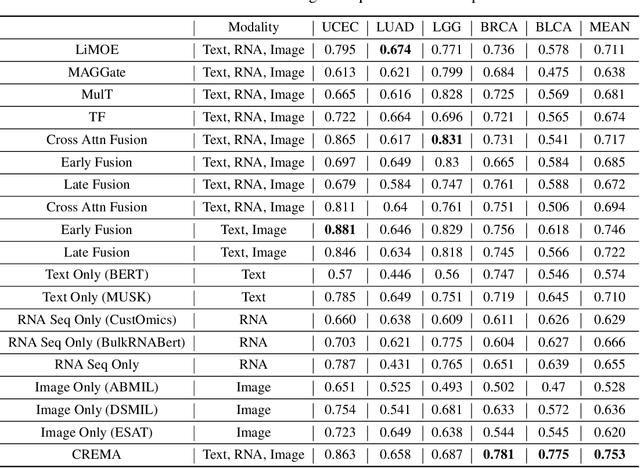
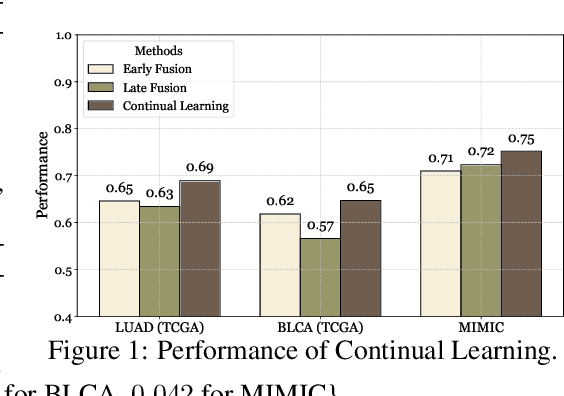
Cancer prognosis is a critical task that involves predicting patient outcomes and survival rates. To enhance prediction accuracy, previous studies have integrated diverse data modalities, such as clinical notes, medical images, and genomic data, leveraging their complementary information. However, existing approaches face two major limitations. First, they struggle to incorporate newly arrived data with varying distributions into training, such as patient records from different hospitals, thus rendering sub-optimal generalizability and limited utility in real-world applications. Second, most multimodal integration methods rely on simplistic concatenation or task-specific pipelines, which fail to capture the complex interdependencies across modalities. To address these, we propose a continually evolving multi-modal foundation model. Extensive experiments on the TCGA dataset demonstrate the effectiveness of our approach, highlighting its potential to advance cancer prognosis by enabling robust and adaptive multimodal integration.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.