 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinually Evolved Multimodal Foundation Models for Cancer Prognosis
Jan 30, 2025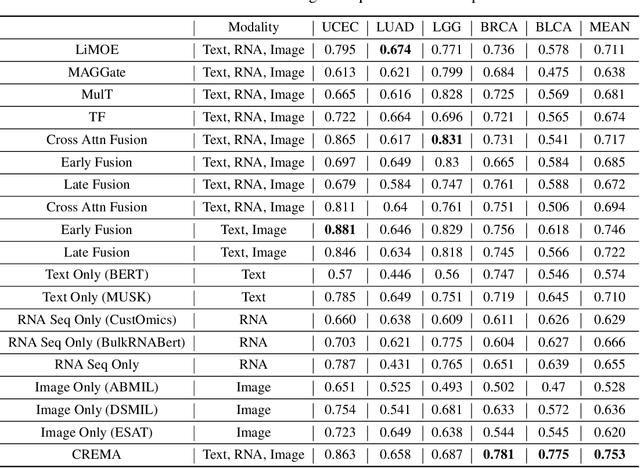
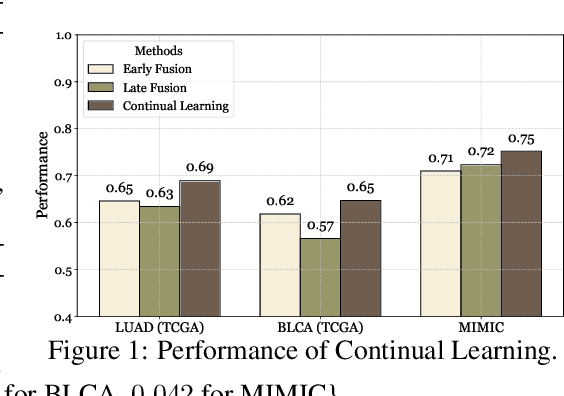
Cancer prognosis is a critical task that involves predicting patient outcomes and survival rates. To enhance prediction accuracy, previous studies have integrated diverse data modalities, such as clinical notes, medical images, and genomic data, leveraging their complementary information. However, existing approaches face two major limitations. First, they struggle to incorporate newly arrived data with varying distributions into training, such as patient records from different hospitals, thus rendering sub-optimal generalizability and limited utility in real-world applications. Second, most multimodal integration methods rely on simplistic concatenation or task-specific pipelines, which fail to capture the complex interdependencies across modalities. To address these, we propose a continually evolving multi-modal foundation model. Extensive experiments on the TCGA dataset demonstrate the effectiveness of our approach, highlighting its potential to advance cancer prognosis by enabling robust and adaptive multimodal integration.
Augmenting Prototype Network with TransMix for Few-shot Hyperspectral Image Classification
Jan 22, 2024



Few-shot hyperspectral image classification aims to identify the classes of each pixel in the images by only marking few of these pixels. And in order to obtain the spatial-spectral joint features of each pixel, the fixed-size patches centering around each pixel are often used for classification. However, observing the classification results of existing methods, we found that boundary patches corresponding to the pixels which are located at the boundary of the objects in the hyperspectral images, are hard to classify. These boundary patchs are mixed with multi-class spectral information. Inspired by this, we propose to augment the prototype network with TransMix for few-shot hyperspectrial image classification(APNT). While taking the prototype network as the backbone, it adopts the transformer as feature extractor to learn the pixel-to-pixel relation and pay different attentions to different pixels. At the same time, instead of directly using the patches which are cut from the hyperspectral images for training, it randomly mixs up two patches to imitate the boundary patches and uses the synthetic patches to train the model, with the aim to enlarge the number of hard training samples and enhance their diversity. And by following the data agumentation technique TransMix, the attention returned by the transformer is also used to mix up the labels of two patches to generate better labels for synthetic patches. Compared with existing methods, the proposed method has demonstrated sate of the art performance and better robustness for few-shot hyperspectral image classification in our experiments.
Multi-view Relation Learning for Cross-domain Few-shot Hyperspectral Image Classification
Nov 02, 2023Cross-domain few-shot hyperspectral image classification focuses on learning prior knowledge from a large number of labeled samples from source domain and then transferring the knowledge to the tasks which contain only few labeled samples in target domains. Following the metric-based manner, many current methods first extract the features of the query and support samples, and then directly predict the classes of query samples according to their distance to the support samples or prototypes. The relations between samples have not been fully explored and utilized. Different from current works, this paper proposes to learn sample relations from different views and take them into the model learning process, to improve the cross-domain few-shot hyperspectral image classification. Building on current DCFSL method which adopts a domain discriminator to deal with domain-level distribution difference, the proposed method applys contrastive learning to learn the class-level sample relations to obtain more discriminable sample features. In addition, it adopts a transformer based cross-attention learning module to learn the set-level sample relations and acquire the attentions from query samples to support samples. Our experimental results have demonstrated the contribution of the multi-view relation learning mechanism for few-shot hyperspectral image classification when compared with the state of the art methods.
Delay Analysis of Wireless Federated Learning Based on Saddle Point Approximation and Large Deviation Theory
Apr 01, 2021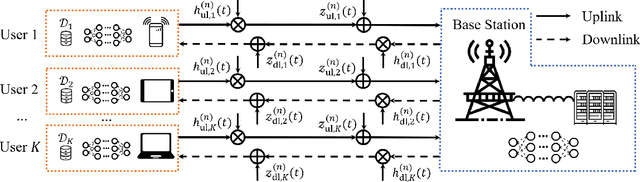



Federated learning (FL) is a collaborative machine learning paradigm, which enables deep learning model training over a large volume of decentralized data residing in mobile devices without accessing clients' private data. Driven by the ever increasing demand for model training of mobile applications or devices, a vast majority of FL tasks are implemented over wireless fading channels. Due to the time-varying nature of wireless channels, however, random delay occurs in both the uplink and downlink transmissions of FL. How to analyze the overall time consumption of a wireless FL task, or more specifically, a FL's delay distribution, becomes a challenging but important open problem, especially for delay-sensitive model training. In this paper, we present a unified framework to calculate the approximate delay distributions of FL over arbitrary fading channels. Specifically, saddle point approximation, extreme value theory (EVT), and large deviation theory (LDT) are jointly exploited to find the approximate delay distribution along with its tail distribution, which characterizes the quality-of-service of a wireless FL system. Simulation results will demonstrate that our approximation method achieves a small approximation error, which vanishes with the increase of training accuracy.