 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiScreen: Early Epilepsy Detection from Electronic Health Records with Large Language Models
Mar 30, 2026Epilepsy and psychogenic non-epileptic seizures often present with similar seizure-like manifestations but require fundamentally different management strategies. Misdiagnosis is common and can lead to prolonged diagnostic delays, unnecessary treatments, and substantial patient morbidity. Although prolonged video-electroencephalography is the diagnostic gold standard, its high cost and limited accessibility hinder timely diagnosis. Here, we developed a low-cost, effective approach, EpiScreen, for early epilepsy detection by utilizing routinely collected clinical notes from electronic health records. Through fine-tuning large language models on labeled notes, EpiScreen achieved an AUC of up to 0.875 on the MIMIC-IV dataset and 0.980 on a private cohort of the University of Minnesota. In a clinician-AI collaboration setting, EpiScreen-assisted neurologists outperformed unaided experts by up to 10.9%. Overall, this study demonstrates that EpiScreen supports early epilepsy detection, facilitating timely and cost-effective screening that may reduce diagnostic delays and avoid unnecessary interventions, particularly in resource-limited regions.
HeartAgent: An Autonomous Agent System for Explainable Differential Diagnosis in Cardiology
Mar 11, 2026Heart diseases remain a leading cause of morbidity and mortality worldwide, necessitating accurate and trustworthy differential diagnosis. However, existing artificial intelligence-based diagnostic methods are often limited by insufficient cardiology knowledge, inadequate support for complex reasoning, and poor interpretability. Here we present HeartAgent, a cardiology-specific agent system designed to support a reliable and explainable differential diagnosis. HeartAgent integrates customized tools and curated data resources and orchestrates multiple specialized sub-agents to perform complex reasoning while generating transparent reasoning trajectories and verifiable supporting references. Evaluated on the MIMIC dataset and a private electronic health records cohort, HeartAgent achieved over 36% and 20% improvements over established comparative methods, in top-3 diagnostic accuracy, respectively. Additionally, clinicians assisted by HeartAgent demonstrated gains of 26.9% in diagnostic accuracy and 22.7% in explanatory quality compared with unaided experts. These results demonstrate that HeartAgent provides reliable, explainable, and clinically actionable decision support for cardiovascular care.
EPEE: Towards Efficient and Effective Foundation Models in Biomedicine
Mar 03, 2025Foundation models, including language models, e.g., GPT, and vision models, e.g., CLIP, have significantly advanced numerous biomedical tasks. Despite these advancements, the high inference latency and the "overthinking" issues in model inference impair the efficiency and effectiveness of foundation models, thus limiting their application in real-time clinical settings. To address these challenges, we proposed EPEE (Entropy- and Patience-based Early Exiting), a novel hybrid strategy designed to improve the inference efficiency of foundation models. The core idea was to leverage the strengths of entropy-based and patience-based early exiting methods to overcome their respective weaknesses. To evaluate EPEE, we conducted experiments on three core biomedical tasks-classification, relation extraction, and event extraction-using four foundation models (BERT, ALBERT, GPT-2, and ViT) across twelve datasets, including clinical notes and medical images. The results showed that EPEE significantly reduced inference time while maintaining or improving accuracy, demonstrating its adaptability to diverse datasets and tasks. EPEE addressed critical barriers to deploying foundation models in healthcare by balancing efficiency and effectiveness. It potentially provided a practical solution for real-time clinical decision-making with foundation models, supporting reliable and efficient workflows.
The Efficiency vs. Accuracy Trade-off: Optimizing RAG-Enhanced LLM Recommender Systems Using Multi-Head Early Exit
Jan 04, 2025



The deployment of Large Language Models (LLMs) in recommender systems for predicting Click-Through Rates (CTR) necessitates a delicate balance between computational efficiency and predictive accuracy. This paper presents an optimization framework that combines Retrieval-Augmented Generation (RAG) with an innovative multi-head early exit architecture to concurrently enhance both aspects. By integrating Graph Convolutional Networks (GCNs) as efficient retrieval mechanisms, we are able to significantly reduce data retrieval times while maintaining high model performance. The early exit strategy employed allows for dynamic termination of model inference, utilizing real-time predictive confidence assessments across multiple heads. This not only quickens the responsiveness of LLMs but also upholds or improves their accuracy, making it ideal for real-time application scenarios. Our experiments demonstrate how this architecture effectively decreases computation time without sacrificing the accuracy needed for reliable recommendation delivery, establishing a new standard for efficient, real-time LLM deployment in commercial systems.
MCQG-SRefine: Multiple Choice Question Generation and Evaluation with Iterative Self-Critique, Correction, and Comparison Feedback
Oct 17, 2024



Automatic question generation (QG) is essential for AI and NLP, particularly in intelligent tutoring, dialogue systems, and fact verification. Generating multiple-choice questions (MCQG) for professional exams, like the United States Medical Licensing Examination (USMLE), is particularly challenging, requiring domain expertise and complex multi-hop reasoning for high-quality questions. However, current large language models (LLMs) like GPT-4 struggle with professional MCQG due to outdated knowledge, hallucination issues, and prompt sensitivity, resulting in unsatisfactory quality and difficulty. To address these challenges, we propose MCQG-SRefine, an LLM self-refine-based (Critique and Correction) framework for converting medical cases into high-quality USMLE-style questions. By integrating expert-driven prompt engineering with iterative self-critique and self-correction feedback, MCQG-SRefine significantly enhances human expert satisfaction regarding both the quality and difficulty of the questions. Furthermore, we introduce an LLM-as-Judge-based automatic metric to replace the complex and costly expert evaluation process, ensuring reliable and expert-aligned assessments.
MedQA-CS: Benchmarking Large Language Models Clinical Skills Using an AI-SCE Framework
Oct 02, 2024



Artificial intelligence (AI) and large language models (LLMs) in healthcare require advanced clinical skills (CS), yet current benchmarks fail to evaluate these comprehensively. We introduce MedQA-CS, an AI-SCE framework inspired by medical education's Objective Structured Clinical Examinations (OSCEs), to address this gap. MedQA-CS evaluates LLMs through two instruction-following tasks, LLM-as-medical-student and LLM-as-CS-examiner, designed to reflect real clinical scenarios. Our contributions include developing MedQA-CS, a comprehensive evaluation framework with publicly available data and expert annotations, and providing the quantitative and qualitative assessment of LLMs as reliable judges in CS evaluation. Our experiments show that MedQA-CS is a more challenging benchmark for evaluating clinical skills than traditional multiple-choice QA benchmarks (e.g., MedQA). Combined with existing benchmarks, MedQA-CS enables a more comprehensive evaluation of LLMs' clinical capabilities for both open- and closed-source LLMs.
Privacy-preserving Fine-tuning of Large Language Models through Flatness
Mar 07, 2024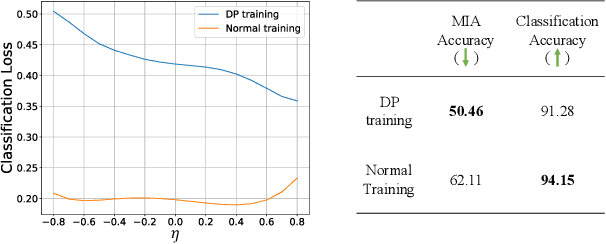
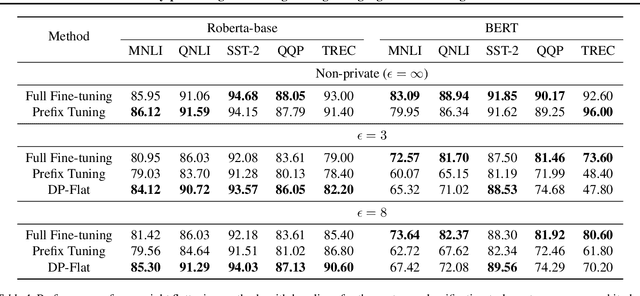
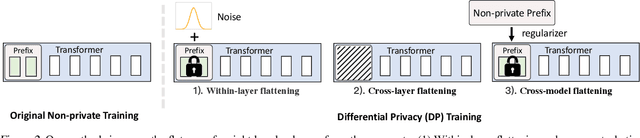

The privacy concerns associated with the use of Large Language Models (LLMs) have grown recently with the development of LLMs such as ChatGPT. Differential Privacy (DP) techniques are explored in existing work to mitigate their privacy risks at the cost of generalization degradation. Our paper reveals that the flatness of DP-trained models' loss landscape plays an essential role in the trade-off between their privacy and generalization. We further propose a holistic framework to enforce appropriate weight flatness, which substantially improves model generalization with competitive privacy preservation. It innovates from three coarse-to-grained levels, including perturbation-aware min-max optimization on model weights within a layer, flatness-guided sparse prefix-tuning on weights across layers, and weight knowledge distillation between DP \& non-DP weights copies. Comprehensive experiments of both black-box and white-box scenarios are conducted to demonstrate the effectiveness of our proposal in enhancing generalization and maintaining DP characteristics. For instance, on text classification dataset QNLI, DP-Flat achieves similar performance with non-private full fine-tuning but with DP guarantee under privacy budget $\epsilon=3$, and even better performance given higher privacy budgets. Codes are provided in the supplement.
EHRTutor: Enhancing Patient Understanding of Discharge Instructions
Oct 30, 2023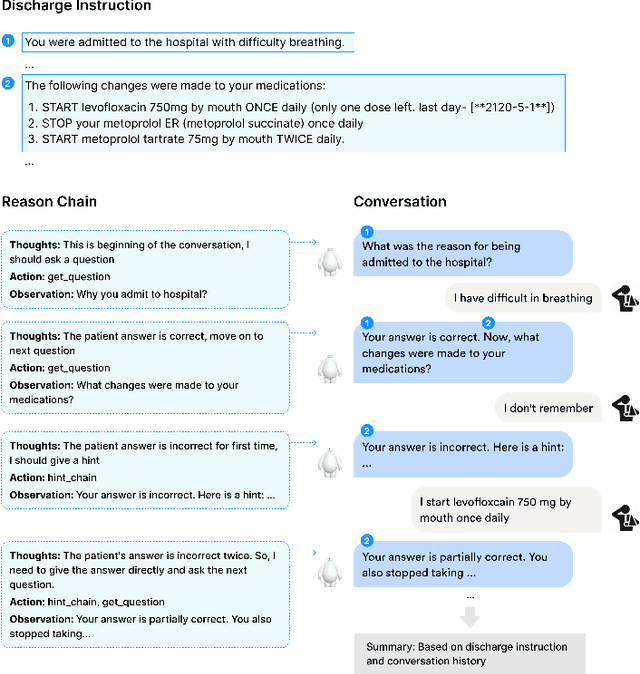
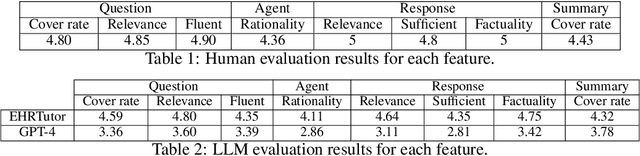
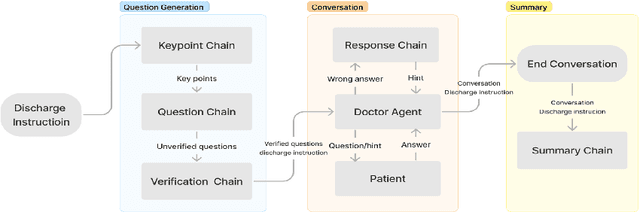

Large language models have shown success as a tutor in education in various fields. Educating patients about their clinical visits plays a pivotal role in patients' adherence to their treatment plans post-discharge. This paper presents EHRTutor, an innovative multi-component framework leveraging the Large Language Model (LLM) for patient education through conversational question-answering. EHRTutor first formulates questions pertaining to the electronic health record discharge instructions. It then educates the patient through conversation by administering each question as a test. Finally, it generates a summary at the end of the conversation. Evaluation results using LLMs and domain experts have shown a clear preference for EHRTutor over the baseline. Moreover, EHRTutor also offers a framework for generating synthetic patient education dialogues that can be used for future in-house system training.
PeTailor: Improving Large Language Model by Tailored Chunk Scorer in Biomedical Triple Extraction
Oct 27, 2023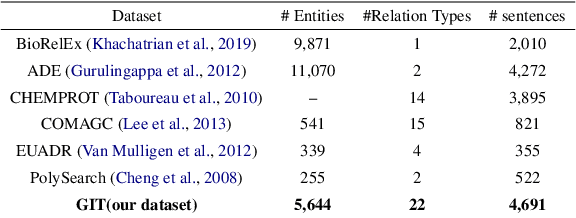



The automatic extraction of biomedical entities and their interaction from unstructured data remains a challenging task due to the limited availability of expert-labeled standard datasets. In this paper, we introduce PETAI-LOR, a retrieval-based language framework that is augmented by tailored chunk scorer. Unlike previous retrieval-augmented language models (LM) that retrieve relevant documents by calculating the similarity between the input sentence and the candidate document set, PETAILOR segments the sentence into chunks and retrieves the relevant chunk from our pre-computed chunk-based relational key-value memory. Moreover, in order to comprehend the specific requirements of the LM, PETAI-LOR adapt the tailored chunk scorer to the LM. We also introduce GM-CIHT, an expert annotated biomedical triple extraction dataset with more relation types. This dataset is centered on the non-drug treatment and general biomedical domain. Additionally, we investigate the efficacy of triple extraction models trained on general domains when applied to the biomedical domain. Our experiments reveal that PETAI-LOR achieves state-of-the-art performance on GM-CIHT
NoteChat: A Dataset of Synthetic Doctor-Patient Conversations Conditioned on Clinical Notes
Oct 24, 2023



The detailed clinical records drafted by doctors after each patient's visit are crucial for medical practitioners and researchers. Automating the creation of these notes with language models can reduce the workload of doctors. However, training such models can be difficult due to the limited public availability of conversations between patients and doctors. In this paper, we introduce NoteChat, a cooperative multi-agent framework leveraging Large Language Models (LLMs) for generating synthetic doctor-patient conversations conditioned on clinical notes. NoteChat consists of Planning, Roleplay, and Polish modules. We provide a comprehensive automatic and human evaluation of NoteChat, comparing it with state-of-the-art models, including OpenAI's ChatGPT and GPT-4. Results demonstrate that NoteChat facilitates high-quality synthetic doctor-patient conversations, underscoring the untapped potential of LLMs in healthcare. This work represents the first instance of multiple LLMs cooperating to complete a doctor-patient conversation conditioned on clinical notes, offering promising avenues for the intersection of AI and healthcare