 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and Simulation of Quadrupedal Robot in Adaptive Stair Climbing for Indoor Firefighting: An End-to-End Reinforcement Learning Approach
Feb 03, 2026Quadruped robots are used for primary searches during the early stages of indoor fires. A typical primary search involves quickly and thoroughly looking for victims under hazardous conditions and monitoring flammable materials. However, situational awareness in complex indoor environments and rapid stair climbing across different staircases remain the main challenges for robot-assisted primary searches. In this project, we designed a two-stage end-to-end deep reinforcement learning (RL) approach to optimize both navigation and locomotion. In the first stage, the quadrupeds, Unitree Go2, were trained to climb stairs in Isaac Lab's pyramid-stair terrain. In the second stage, the quadrupeds were trained to climb various realistic indoor staircases in the Isaac Lab engine, with the learned policy transferred from the previous stage. These indoor staircases are straight, L-shaped, and spiral, to support climbing tasks in complex environments. This project explores how to balance navigation and locomotion and how end-to-end RL methods can enable quadrupeds to adapt to different stair shapes. Our main contributions are: (1) A two-stage end-to-end RL framework that transfers stair-climbing skills from abstract pyramid terrain to realistic indoor stair topologies. (2) A centerline-based navigation formulation that enables unified learning of navigation and locomotion without hierarchical planning. (3) Demonstration of policy generalization across diverse staircases using only local height-map perception. (4) An empirical analysis of success, efficiency, and failure modes under increasing stair difficulty.
Tokenize Once, Recommend Anywhere: Unified Item Tokenization for Multi-domain LLM-based Recommendation
Nov 17, 2025Large language model (LLM)-based recommender systems have achieved high-quality performance by bridging the discrepancy between the item space and the language space through item tokenization. However, existing item tokenization methods typically require training separate models for each item domain, limiting generalization. Moreover, the diverse distributions and semantics across item domains make it difficult to construct a unified tokenization that preserves domain-specific information. To address these challenges, we propose UniTok, a Unified item Tokenization framework that integrates our own mixture-of-experts (MoE) architecture with a series of codebooks to convert items into discrete tokens, enabling scalable tokenization while preserving semantic information across multiple item domains. Specifically, items from different domains are first projected into a unified latent space through a shared encoder. They are then routed to domain-specific experts to capture the unique semantics, while a shared expert, which is always active, encodes common knowledge transferable across domains. Additionally, to mitigate semantic imbalance across domains, we present a mutual information calibration mechanism, which guides the model towards retaining similar levels of semantic information for each domain. Comprehensive experiments on wide-ranging real-world datasets demonstrate that the proposed UniTok framework is (a) highly effective: achieving up to 51.89% improvements over strong benchmarks, (b) theoretically sound: showing the analytical validity of our architectural design and optimization; and (c) highly generalizable: demonstrating robust performance across diverse domains without requiring per-domain retraining, a capability not supported by existing baselines.
Fine-Tuning Diffusion-Based Recommender Systems via Reinforcement Learning with Reward Function Optimization
Nov 10, 2025Diffusion models recently emerged as a powerful paradigm for recommender systems, offering state-of-the-art performance by modeling the generative process of user-item interactions. However, training such models from scratch is both computationally expensive and yields diminishing returns once convergence is reached. To remedy these challenges, we propose ReFiT, a new framework that integrates Reinforcement learning (RL)-based Fine-Tuning into diffusion-based recommender systems. In contrast to prior RL approaches for diffusion models depending on external reward models, ReFiT adopts a task-aligned design: it formulates the denoising trajectory as a Markov decision process (MDP) and incorporates a collaborative signal-aware reward function that directly reflects recommendation quality. By tightly coupling the MDP structure with this reward signal, ReFiT empowers the RL agent to exploit high-order connectivity for fine-grained optimization, while avoiding the noisy or uninformative feedback common in naive reward designs. Leveraging policy gradient optimization, ReFiT maximizes exact log-likelihood of observed interactions, thereby enabling effective post hoc fine-tuning of diffusion recommenders. Comprehensive experiments on wide-ranging real-world datasets demonstrate that the proposed ReFiT framework (a) exhibits substantial performance gains over strong competitors (up to 36.3% on sequential recommendation), (b) demonstrates strong efficiency with linear complexity in the number of users or items, and (c) generalizes well across multiple diffusion-based recommendation scenarios. The source code and datasets are publicly available at https://anonymous.4open.science/r/ReFiT-4C60.
Uncertainty-Aware Large Language Models for Explainable Disease Diagnosis
May 06, 2025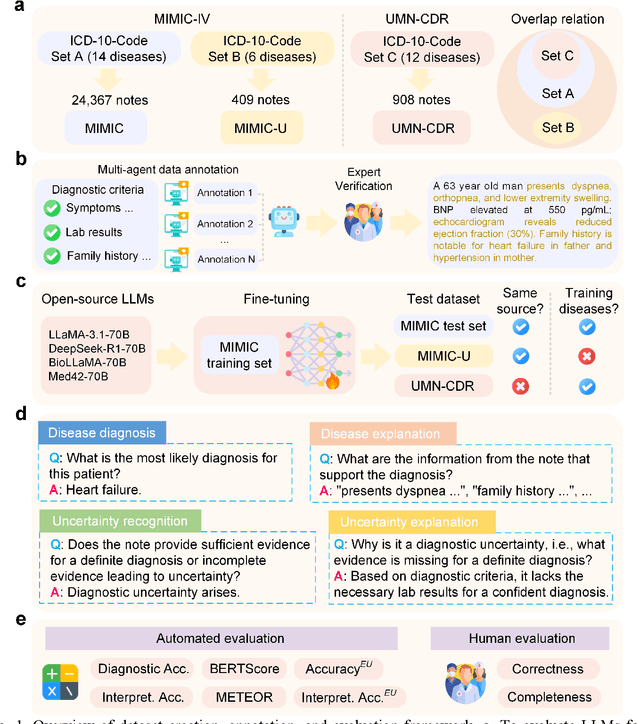
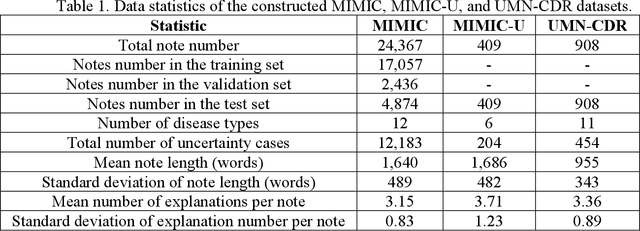

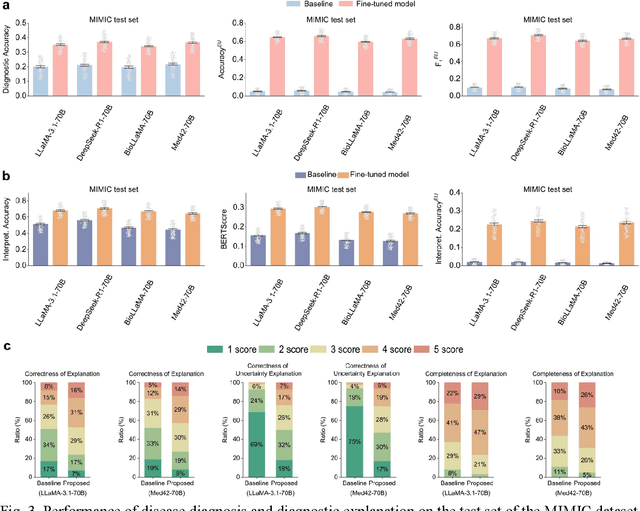
Explainable disease diagnosis, which leverages patient information (e.g., signs and symptoms) and computational models to generate probable diagnoses and reasonings, offers clear clinical values. However, when clinical notes encompass insufficient evidence for a definite diagnosis, such as the absence of definitive symptoms, diagnostic uncertainty usually arises, increasing the risk of misdiagnosis and adverse outcomes. Although explicitly identifying and explaining diagnostic uncertainties is essential for trustworthy diagnostic systems, it remains under-explored. To fill this gap, we introduce ConfiDx, an uncertainty-aware large language model (LLM) created by fine-tuning open-source LLMs with diagnostic criteria. We formalized the task and assembled richly annotated datasets that capture varying degrees of diagnostic ambiguity. Evaluating ConfiDx on real-world datasets demonstrated that it excelled in identifying diagnostic uncertainties, achieving superior diagnostic performance, and generating trustworthy explanations for diagnoses and uncertainties. To our knowledge, this is the first study to jointly address diagnostic uncertainty recognition and explanation, substantially enhancing the reliability of automatic diagnostic systems.
Retrieval-augmented in-context learning for multimodal large language models in disease classification
May 04, 2025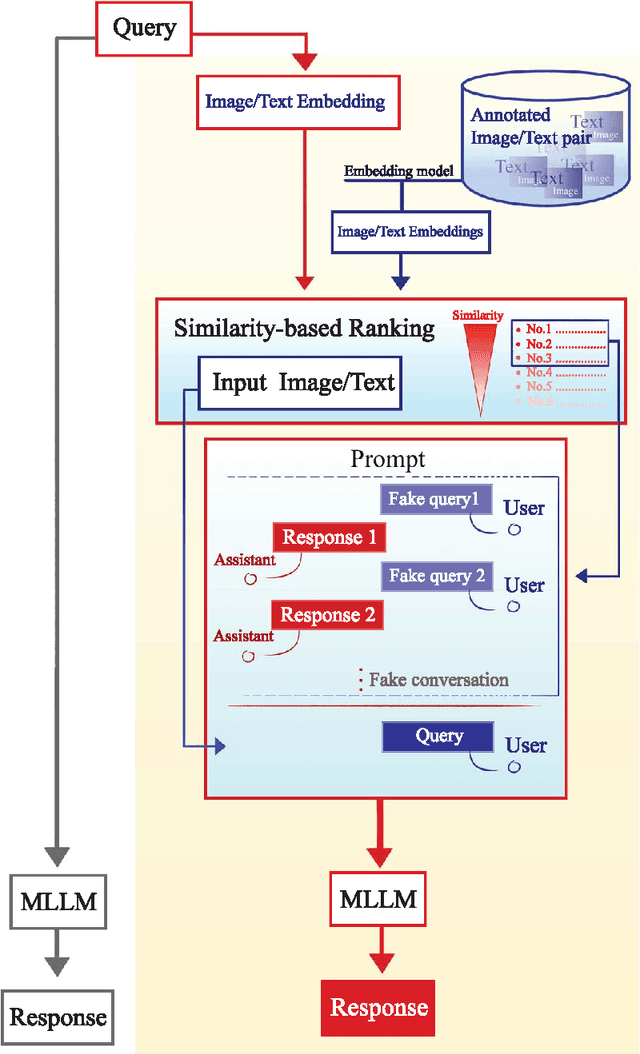
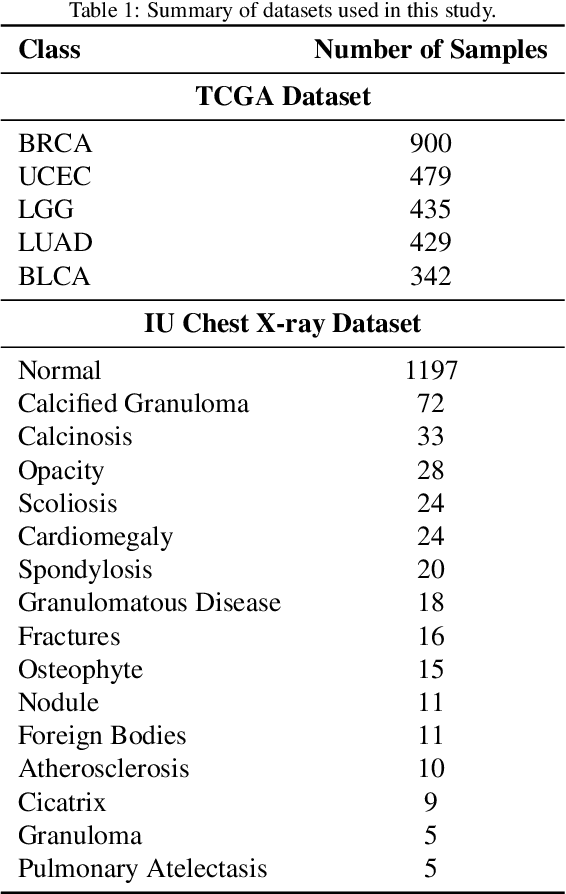
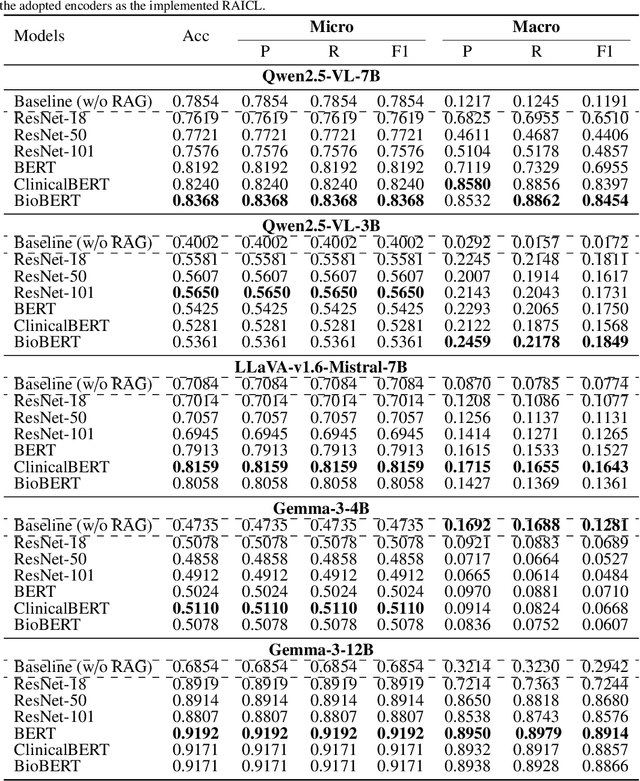
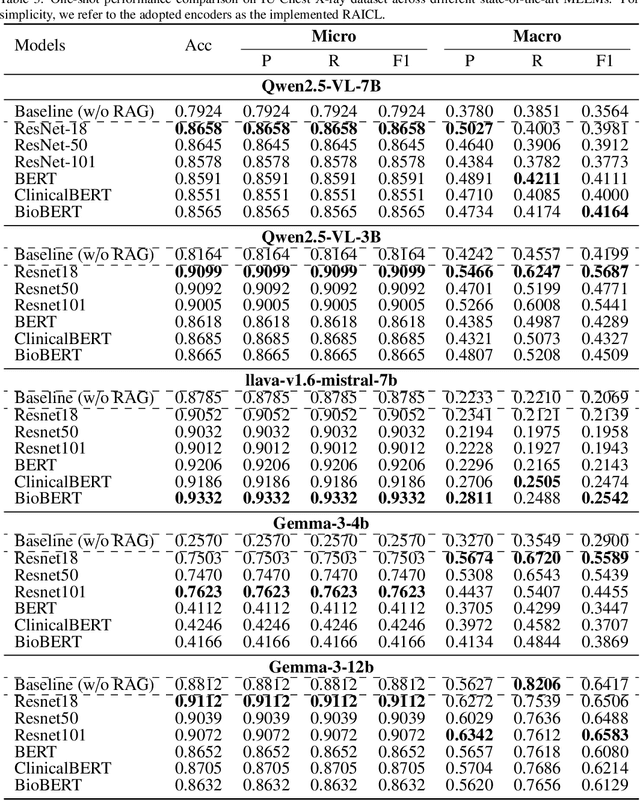
Objectives: We aim to dynamically retrieve informative demonstrations, enhancing in-context learning in multimodal large language models (MLLMs) for disease classification. Methods: We propose a Retrieval-Augmented In-Context Learning (RAICL) framework, which integrates retrieval-augmented generation (RAG) and in-context learning (ICL) to adaptively select demonstrations with similar disease patterns, enabling more effective ICL in MLLMs. Specifically, RAICL examines embeddings from diverse encoders, including ResNet, BERT, BioBERT, and ClinicalBERT, to retrieve appropriate demonstrations, and constructs conversational prompts optimized for ICL. We evaluated the framework on two real-world multi-modal datasets (TCGA and IU Chest X-ray), assessing its performance across multiple MLLMs (Qwen, Llava, Gemma), embedding strategies, similarity metrics, and varying numbers of demonstrations. Results: RAICL consistently improved classification performance. Accuracy increased from 0.7854 to 0.8368 on TCGA and from 0.7924 to 0.8658 on IU Chest X-ray. Multi-modal inputs outperformed single-modal ones, with text-only inputs being stronger than images alone. The richness of information embedded in each modality will determine which embedding model can be used to get better results. Few-shot experiments showed that increasing the number of retrieved examples further enhanced performance. Across different similarity metrics, Euclidean distance achieved the highest accuracy while cosine similarity yielded better macro-F1 scores. RAICL demonstrated consistent improvements across various MLLMs, confirming its robustness and versatility. Conclusions: RAICL provides an efficient and scalable approach to enhance in-context learning in MLLMs for multimodal disease classification.
Language Models Predict Empathy Gaps Between Social In-groups and Out-groups
Mar 02, 2025Studies of human psychology have demonstrated that people are more motivated to extend empathy to in-group members than out-group members (Cikara et al., 2011). In this study, we investigate how this aspect of intergroup relations in humans is replicated by LLMs in an emotion intensity prediction task. In this task, the LLM is given a short description of an experience a person had that caused them to feel a particular emotion; the LLM is then prompted to predict the intensity of the emotion the person experienced on a numerical scale. By manipulating the group identities assigned to the LLM's persona (the "perceiver") and the person in the narrative (the "experiencer"), we measure how predicted emotion intensities differ between in-group and out-group settings. We observe that LLMs assign higher emotion intensity scores to in-group members than out-group members. This pattern holds across all three types of social groupings we tested: race/ethnicity, nationality, and religion. We perform an in-depth analysis on Llama-3.1-8B, the model which exhibited strongest intergroup bias among those tested.
GRACE: A Granular Benchmark for Evaluating Model Calibration against Human Calibration
Feb 27, 2025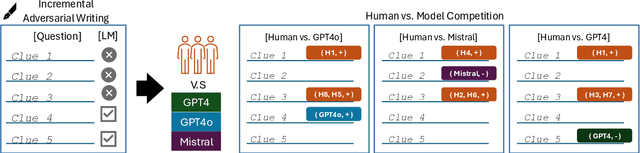
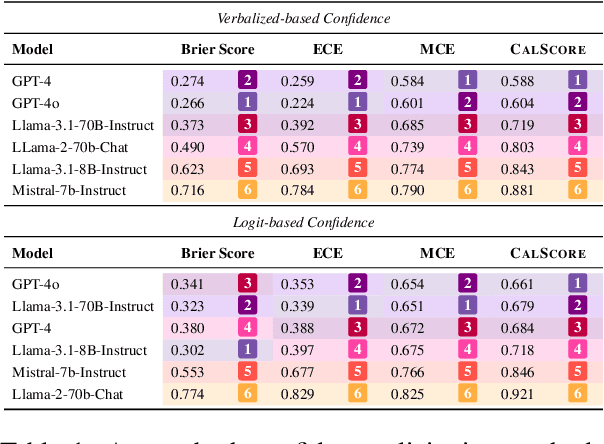
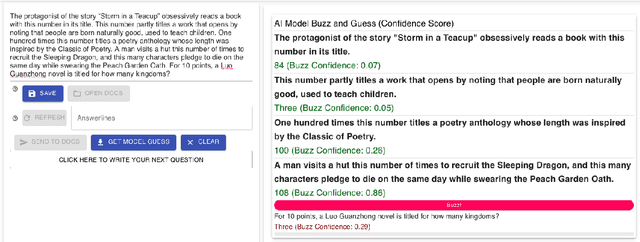
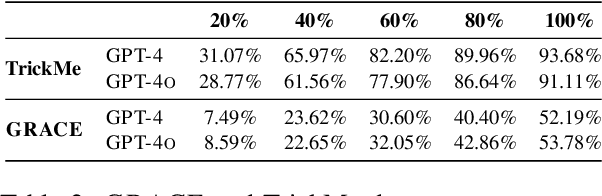
Language models are often miscalibrated, leading to confidently incorrect answers. We introduce GRACE, a benchmark for language model calibration that incorporates comparison with human calibration. GRACE consists of question-answer pairs, in which each question contains a series of clues that gradually become easier, all leading to the same answer; models must answer correctly as early as possible as the clues are revealed. This setting permits granular measurement of model calibration based on how early, accurately, and confidently a model answers. After collecting these questions, we host live human vs. model competitions to gather 1,749 data points on human and model teams' timing, accuracy, and confidence. We propose a metric, CalScore, that uses GRACE to analyze model calibration errors and identify types of model miscalibration that differ from human behavior. We find that although humans are less accurate than models, humans are generally better calibrated. Since state-of-the-art models struggle on GRACE, it effectively evaluates progress on improving model calibration.
Natural Language Inference Improves Compositionality in Vision-Language Models
Oct 29, 2024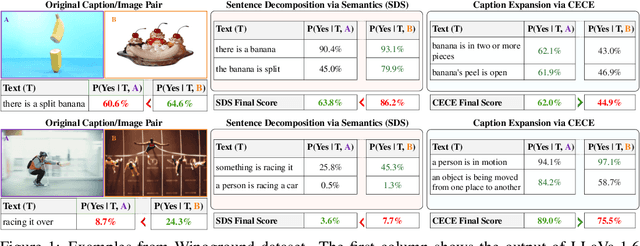
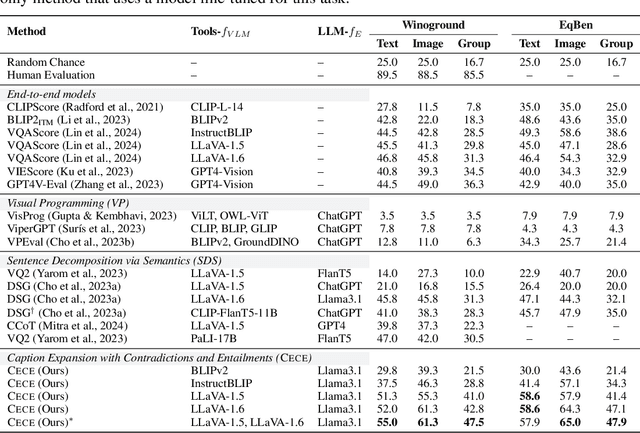
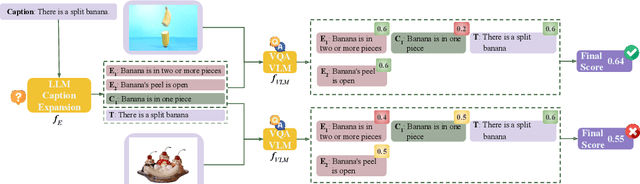

Compositional reasoning in Vision-Language Models (VLMs) remains challenging as these models often struggle to relate objects, attributes, and spatial relationships. Recent methods aim to address these limitations by relying on the semantics of the textual description, using Large Language Models (LLMs) to break them down into subsets of questions and answers. However, these methods primarily operate on the surface level, failing to incorporate deeper lexical understanding while introducing incorrect assumptions generated by the LLM. In response to these issues, we present Caption Expansion with Contradictions and Entailments (CECE), a principled approach that leverages Natural Language Inference (NLI) to generate entailments and contradictions from a given premise. CECE produces lexically diverse sentences while maintaining their core meaning. Through extensive experiments, we show that CECE enhances interpretability and reduces overreliance on biased or superficial features. By balancing CECE along the original premise, we achieve significant improvements over previous methods without requiring additional fine-tuning, producing state-of-the-art results on benchmarks that score agreement with human judgments for image-text alignment, and achieving an increase in performance on Winoground of +19.2% (group score) and +12.9% on EqBen (group score) over the best prior work (finetuned with targeted data).
Collaborative Filtering Based on Diffusion Models: Unveiling the Potential of High-Order Connectivity
Apr 22, 2024



A recent study has shown that diffusion models are well-suited for modeling the generative process of user-item interactions in recommender systems due to their denoising nature. However, existing diffusion model-based recommender systems do not explicitly leverage high-order connectivities that contain crucial collaborative signals for accurate recommendations. Addressing this gap, we propose CF-Diff, a new diffusion model-based collaborative filtering (CF) method, which is capable of making full use of collaborative signals along with multi-hop neighbors. Specifically, the forward-diffusion process adds random noise to user-item interactions, while the reverse-denoising process accommodates our own learning model, named cross-attention-guided multi-hop autoencoder (CAM-AE), to gradually recover the original user-item interactions. CAM-AE consists of two core modules: 1) the attention-aided AE module, responsible for precisely learning latent representations of user-item interactions while preserving the model's complexity at manageable levels, and 2) the multi-hop cross-attention module, which judiciously harnesses high-order connectivity information to capture enhanced collaborative signals. Through comprehensive experiments on three real-world datasets, we demonstrate that CF-Diff is (a) Superior: outperforming benchmark recommendation methods, achieving remarkable gains up to 7.29% compared to the best competitor, (b) Theoretically-validated: reducing computations while ensuring that the embeddings generated by our model closely approximate those from the original cross-attention, and (c) Scalable: proving the computational efficiency that scales linearly with the number of users or items.
A New Method of Pixel-level In-situ U-value Measurement for Building Envelopes Based on Infrared Thermography
Jan 13, 2024The potential energy loss of aging buildings traps building owners in a cycle of underfunding operations and overpaying maintenance costs. Energy auditors intending to generate an energy model of a target building for performance assessment may struggle to obtain accurate results as the spatial distribution of temperatures is not considered when calculating the U-value of the building envelope. This paper proposes a pixel-level method based on infrared thermography (IRT) that considers two-dimensional (2D) spatial temperature distributions of the outdoor and indoor surfaces of the target wall to generate a 2D U-value map of the wall. The result supports that the proposed method can better reflect the actual thermal insulation performance of the target wall compared to the current IRT-based methods that use a single-point room temperature as input.