 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
Apr 18, 2025



A wide range of LM applications require generating text that conforms to syntactic or semantic constraints. Imposing such constraints can be naturally framed as probabilistic conditioning, but exact generation from the resulting distribution -- which can differ substantially from the LM's base distribution -- is generally intractable. In this work, we develop an architecture for controlled LM generation based on sequential Monte Carlo (SMC). Our SMC framework allows us to flexibly incorporate domain- and problem-specific constraints at inference time, and efficiently reallocate computational resources in light of new information during the course of generation. By comparing to a number of alternatives and ablations on four challenging domains -- Python code generation for data science, text-to-SQL, goal inference, and molecule synthesis -- we demonstrate that, with little overhead, our approach allows small open-source language models to outperform models over 8x larger, as well as closed-source, fine-tuned ones. In support of the probabilistic perspective, we show that these performance improvements are driven by better approximation to the posterior distribution. Our system builds on the framework of Lew et al. (2023) and integrates with its language model probabilistic programming language, giving users a simple, programmable way to apply SMC to a broad variety of controlled generation problems.
ACQUIRED: A Dataset for Answering Counterfactual Questions In Real-Life Videos
Nov 02, 2023



Multimodal counterfactual reasoning is a vital yet challenging ability for AI systems. It involves predicting the outcomes of hypothetical circumstances based on vision and language inputs, which enables AI models to learn from failures and explore hypothetical scenarios. Despite its importance, there are only a few datasets targeting the counterfactual reasoning abilities of multimodal models. Among them, they only cover reasoning over synthetic environments or specific types of events (e.g. traffic collisions), making them hard to reliably benchmark the model generalization ability in diverse real-world scenarios and reasoning dimensions. To overcome these limitations, we develop a video question answering dataset, ACQUIRED: it consists of 3.9K annotated videos, encompassing a wide range of event types and incorporating both first and third-person viewpoints, which ensures a focus on real-world diversity. In addition, each video is annotated with questions that span three distinct dimensions of reasoning, including physical, social, and temporal, which can comprehensively evaluate the model counterfactual abilities along multiple aspects. We benchmark our dataset against several state-of-the-art language-only and multimodal models and experimental results demonstrate a significant performance gap (>13%) between models and humans. The findings suggest that multimodal counterfactual reasoning remains an open challenge and ACQUIRED is a comprehensive and reliable benchmark for inspiring future research in this direction.
Remember what you did so you know what to do next
Oct 30, 2023



We explore using a moderately sized large language model (GPT-J 6B parameters) to create a plan for a simulated robot to achieve 30 classes of goals in ScienceWorld, a text game simulator for elementary science experiments. Previously published empirical work claimed that large language models (LLMs) are a poor fit (Wang et al., 2022) compared to reinforcement learning. Using the Markov assumption (a single previous step), the LLM outperforms the reinforcement learning-based approach by a factor of 1.4. When we fill the LLM's input buffer with as many prior steps as possible, improvement rises to 3.5x. Even when training on only 6.5% of the training data, we observe a 2.2x improvement over the reinforcement-learning-based approach. Our experiments show that performance varies widely across the 30 classes of actions, indicating that averaging over tasks can hide significant performance issues. In work contemporaneous with ours, Lin et al. (2023) demonstrated a two-part approach (SwiftSage) that uses a small LLM (T5-large) complemented by OpenAI's massive LLMs to achieve outstanding results in ScienceWorld. Our 6-B parameter, single-stage GPT-J matches the performance of SwiftSage's two-stage architecture when it incorporates GPT-3.5 turbo which has 29-times more parameters than GPT-J.
RECAP: Retrieval-Enhanced Context-Aware Prefix Encoder for Personalized Dialogue Response Generation
Jun 12, 2023



Endowing chatbots with a consistent persona is essential to an engaging conversation, yet it remains an unresolved challenge. In this work, we propose a new retrieval-enhanced approach for personalized response generation. Specifically, we design a hierarchical transformer retriever trained on dialogue domain data to perform personalized retrieval and a context-aware prefix encoder that fuses the retrieved information to the decoder more effectively. Extensive experiments on a real-world dataset demonstrate the effectiveness of our model at generating more fluent and personalized responses. We quantitatively evaluate our model's performance under a suite of human and automatic metrics and find it to be superior compared to state-of-the-art baselines on English Reddit conversations.
Understanding Procedural Knowledge by Sequencing Multimodal Instructional Manuals
Oct 16, 2021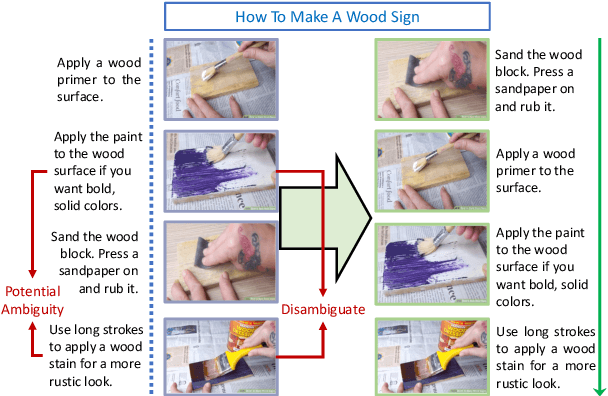
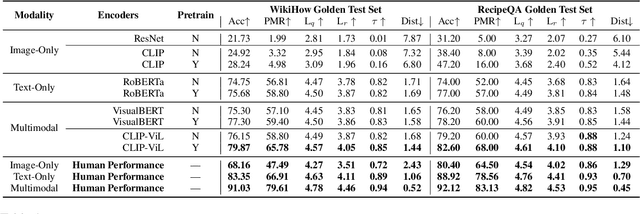
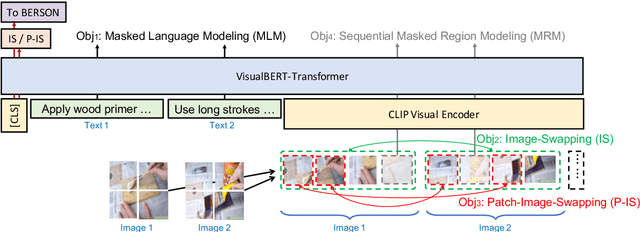

The ability to sequence unordered events is an essential skill to comprehend and reason about real world task procedures, which often requires thorough understanding of temporal common sense and multimodal information, as these procedures are often communicated through a combination of texts and images. Such capability is essential for applications such as sequential task planning and multi-source instruction summarization. While humans are capable of reasoning about and sequencing unordered multimodal procedural instructions, whether current machine learning models have such essential capability is still an open question. In this work, we benchmark models' capability of reasoning over and sequencing unordered multimodal instructions by curating datasets from popular online instructional manuals and collecting comprehensive human annotations. We find models not only perform significantly worse than humans but also seem incapable of efficiently utilizing the multimodal information. To improve machines' performance on multimodal event sequencing, we propose sequentiality-aware pretraining techniques that exploit the sequential alignment properties of both texts and images, resulting in > 5% significant improvements.
Perhaps PTLMs Should Go to School -- A Task to Assess Open Book and Closed Book QA
Oct 04, 2021
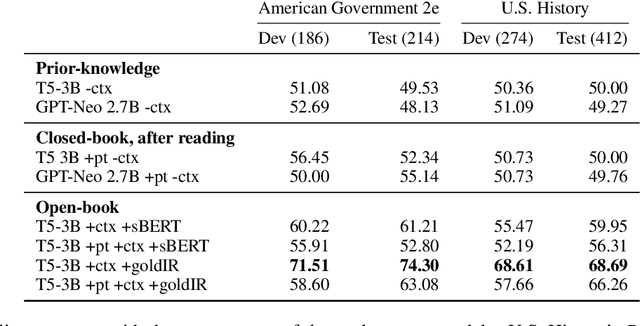
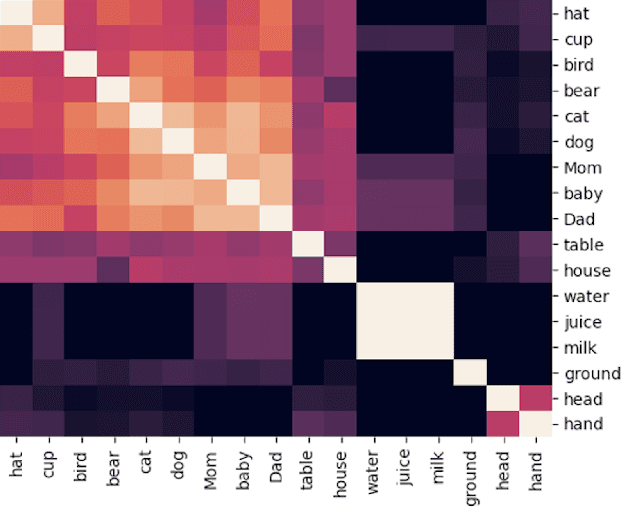
Our goal is to deliver a new task and leaderboard to stimulate research on question answering and pre-trained language models (PTLMs) to understand a significant instructional document, e.g., an introductory college textbook or a manual. PTLMs have shown great success in many question-answering tasks, given significant supervised training, but much less so in zero-shot settings. We propose a new task that includes two college-level introductory texts in the social sciences (American Government 2e) and humanities (U.S. History), hundreds of true/false statements based on review questions written by the textbook authors, validation/development tests based on the first eight chapters of the textbooks, blind tests based on the remaining textbook chapters, and baseline results given state-of-the-art PTLMs. Since the questions are balanced, random performance should be ~50%. T5, fine-tuned with BoolQ achieves the same performance, suggesting that the textbook's content is not pre-represented in the PTLM. Taking the exam closed book, but having read the textbook (i.e., adding the textbook to T5's pre-training), yields at best minor improvement (56%), suggesting that the PTLM may not have "understood" the textbook (or perhaps misunderstood the questions). Performance is better (~60%) when the exam is taken open-book (i.e., allowing the machine to automatically retrieve a paragraph and use it to answer the question).
A Grounded Approach to Modeling Generic Knowledge Acquisition
May 07, 2021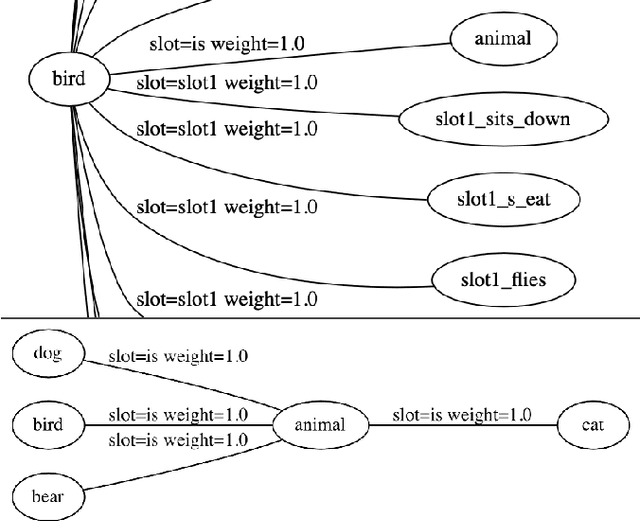

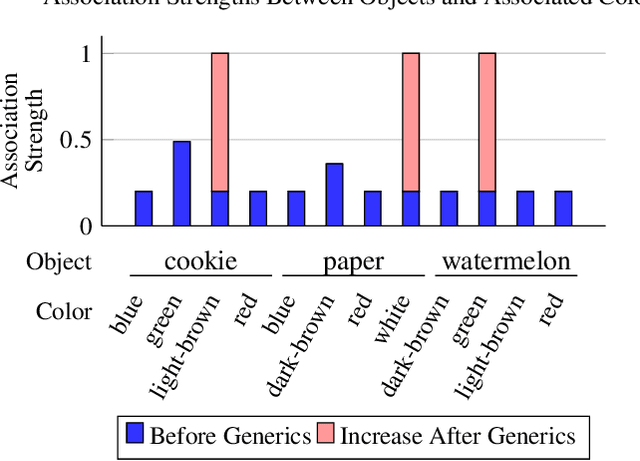
We introduce and implement a cognitively plausible model for learning from generic language, statements that express generalizations about members of a category and are an important aspect of concept development in language acquisition (Carlson & Pelletier, 1995; Gelman, 2009). We extend a computational framework designed to model grounded language acquisition by introducing the concept network. This new layer of abstraction enables the system to encode knowledge learned from generic statements and represent the associations between concepts learned by the system. Through three tasks that utilize the concept network, we demonstrate that our extensions to ADAM can acquire generic information and provide an example of how ADAM can be used to model language acquisition.
ADAM: A Sandbox for Implementing Language Learning
May 05, 2021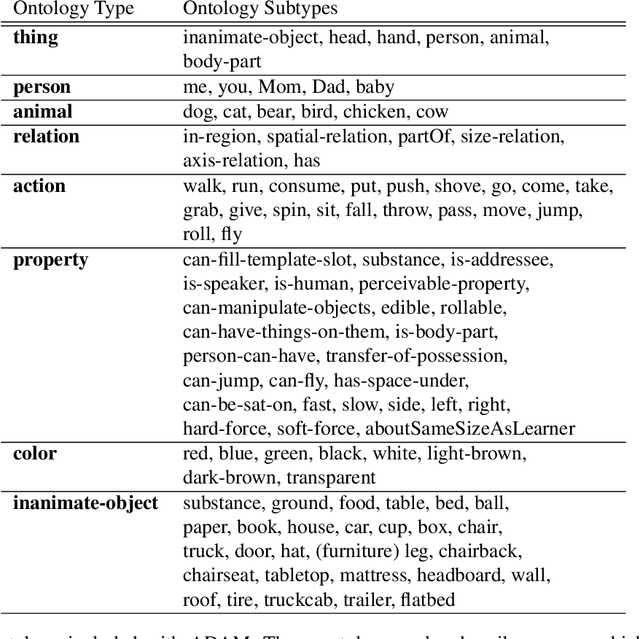

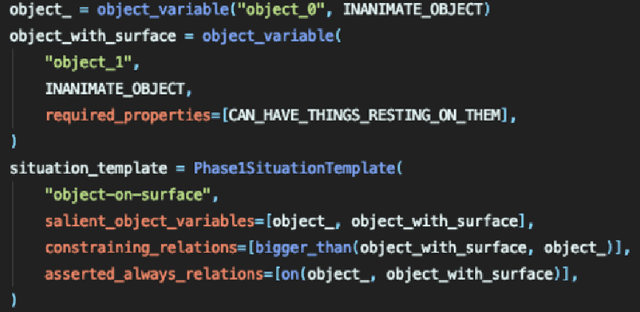
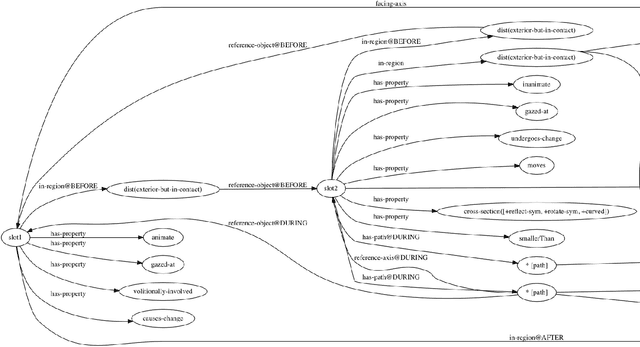
We present ADAM, a software system for designing and running child language learning experiments in Python. The system uses a virtual world to simulate a grounded language acquisition process in which the language learner utilizes cognitively plausible learning algorithms to form perceptual and linguistic representations of the observed world. The modular nature of ADAM makes it easy to design and test different language learning curricula as well as learning algorithms. In this report, we describe the architecture of the ADAM system in detail, and illustrate its components with examples. We provide our code.
Machine-Assisted Script Curation
Jan 14, 2021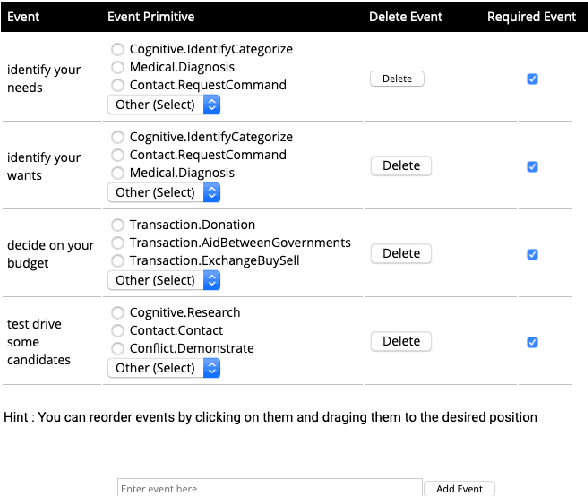
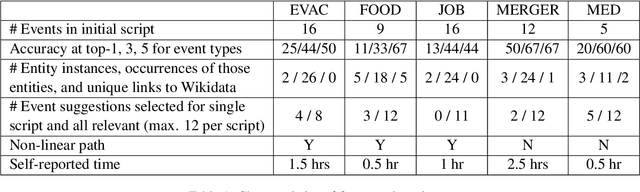
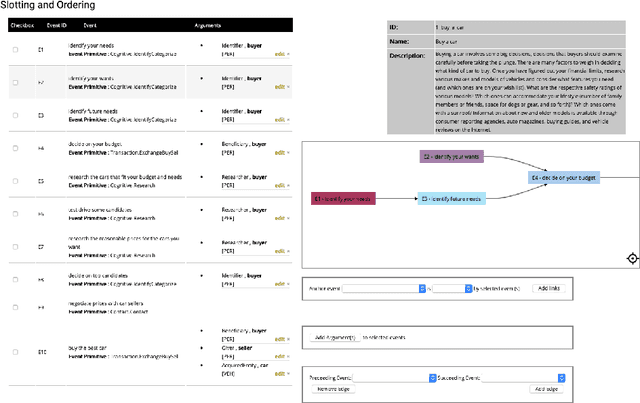
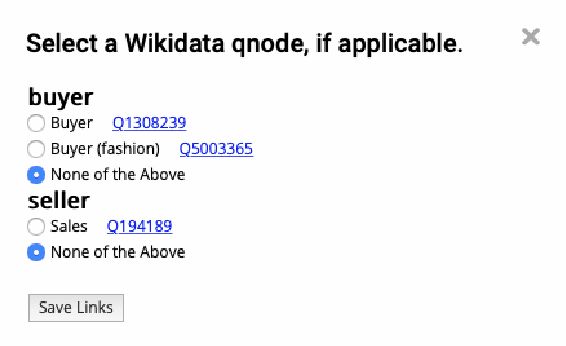
We describe Machine-Aided Script Curator (MASC), a system for human-machine collaborative script authoring. Scripts produced with MASC include (1) English descriptions of sub-events that comprise a larger, complex event; (2) event types for each of those events; (3) a record of entities expected to participate in multiple sub-events; and (4) temporal sequencing between the sub-events. MASC automates portions of the script creation process with suggestions for event types, links to Wikidata, and sub-events that may have been forgotten. We illustrate how these automations are useful to the script writer with a few case-study scripts.
Training with Streaming Annotation
Feb 11, 2020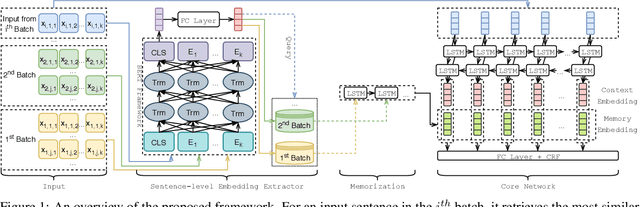
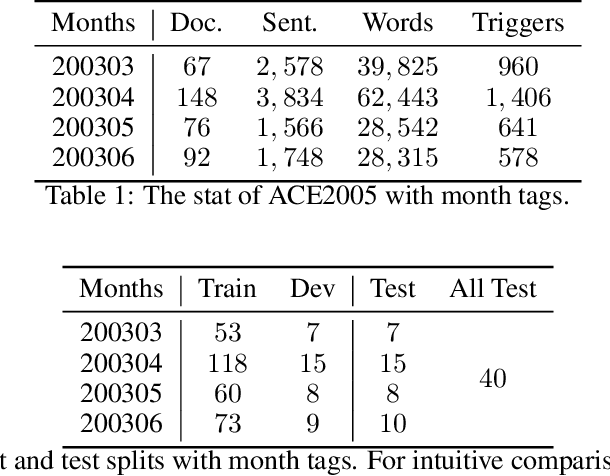
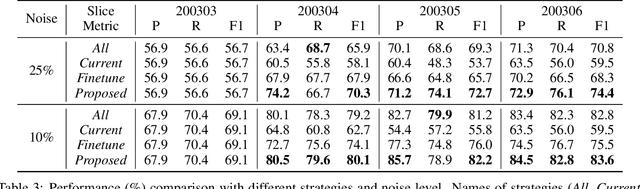
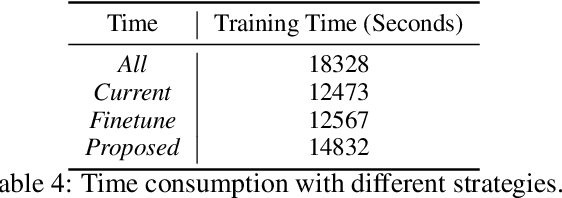
In this paper, we address a practical scenario where training data is released in a sequence of small-scale batches and annotation in earlier phases has lower quality than the later counterparts. To tackle the situation, we utilize a pre-trained transformer network to preserve and integrate the most salient document information from the earlier batches while focusing on the annotation (presumably with higher quality) from the current batch. Using event extraction as a case study, we demonstrate in the experiments that our proposed framework can perform better than conventional approaches (the improvement ranges from 3.6 to 14.9% absolute F-score gain), especially when there is more noise in the early annotation; and our approach spares 19.1% time with regard to the best conventional method.