 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining with Streaming Annotation
Paper and Code
Feb 11, 2020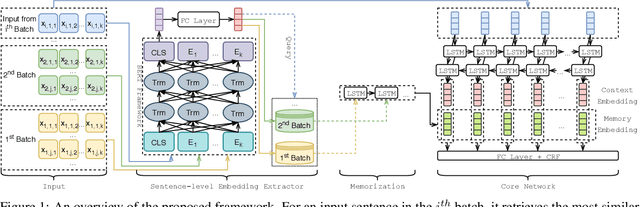
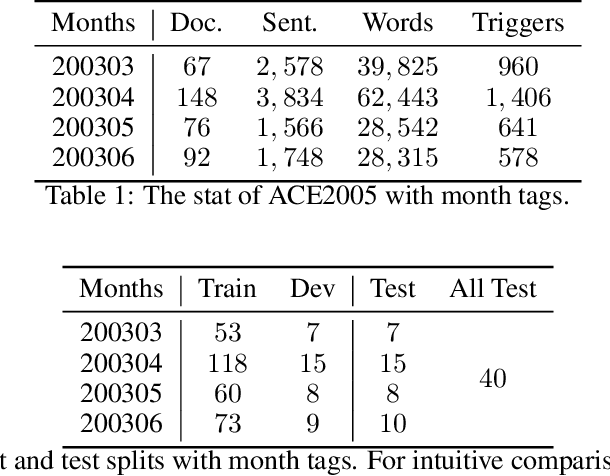
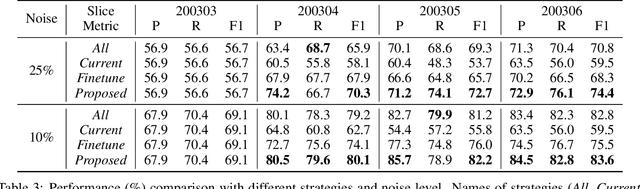
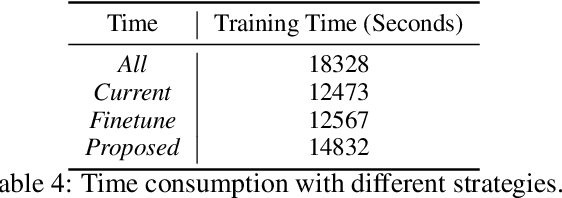
In this paper, we address a practical scenario where training data is released in a sequence of small-scale batches and annotation in earlier phases has lower quality than the later counterparts. To tackle the situation, we utilize a pre-trained transformer network to preserve and integrate the most salient document information from the earlier batches while focusing on the annotation (presumably with higher quality) from the current batch. Using event extraction as a case study, we demonstrate in the experiments that our proposed framework can perform better than conventional approaches (the improvement ranges from 3.6 to 14.9% absolute F-score gain), especially when there is more noise in the early annotation; and our approach spares 19.1% time with regard to the best conventional method.