 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural ODE Interpretation of Transformer Layers
Dec 12, 2022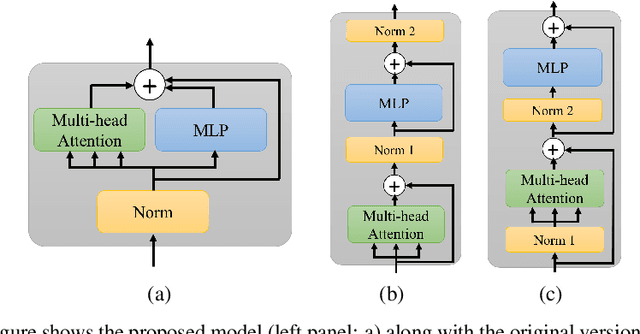

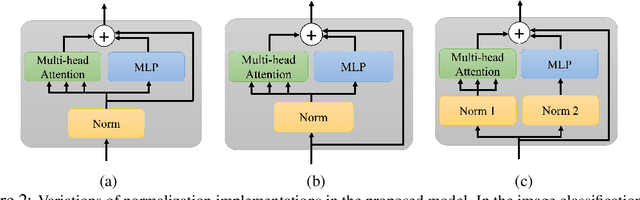

Transformer layers, which use an alternating pattern of multi-head attention and multi-layer perceptron (MLP) layers, provide an effective tool for a variety of machine learning problems. As the transformer layers use residual connections to avoid the problem of vanishing gradients, they can be viewed as the numerical integration of a differential equation. In this extended abstract, we build upon this connection and propose a modification of the internal architecture of a transformer layer. The proposed model places the multi-head attention sublayer and the MLP sublayer parallel to each other. Our experiments show that this simple modification improves the performance of transformer networks in multiple tasks. Moreover, for the image classification task, we show that using neural ODE solvers with a sophisticated integration scheme further improves performance.
Demystifying the Data Need of ML-surrogates for CFD Simulations
May 05, 2022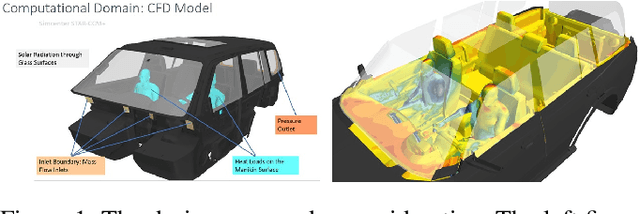
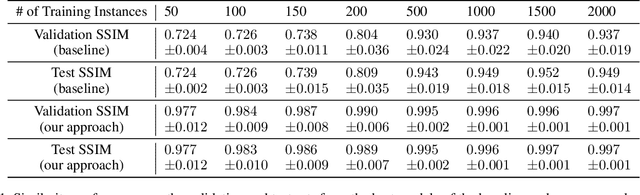
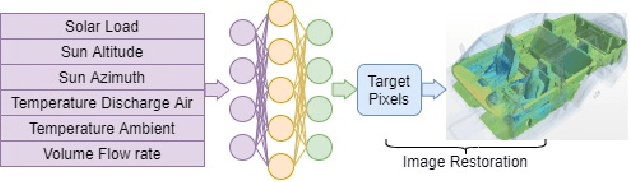
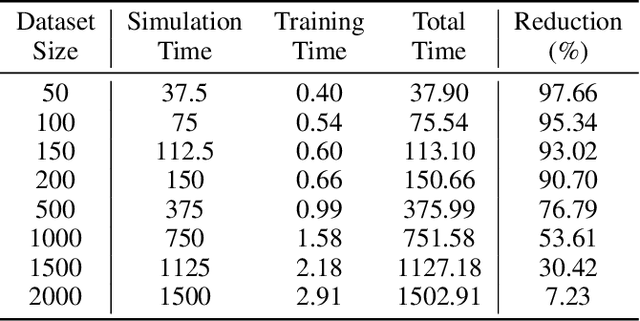
Computational fluid dynamics (CFD) simulations, a critical tool in various engineering applications, often require significant time and compute power to predict flow properties. The high computational cost associated with CFD simulations significantly restricts the scope of design space exploration and limits their use in planning and operational control. To address this issue, machine learning (ML) based surrogate models have been proposed as a computationally efficient tool to accelerate CFD simulations. However, a lack of clarity about CFD data requirements often challenges the widespread adoption of ML-based surrogates among design engineers and CFD practitioners. In this work, we propose an ML-based surrogate model to predict the temperature distribution inside the cabin of a passenger vehicle under various operating conditions and use it to demonstrate the trade-off between prediction performance and training dataset size. Our results show that the prediction accuracy is high and stable even when the training size is gradually reduced from 2000 to 200. The ML-based surrogates also reduce the compute time from ~30 minutes to around ~9 milliseconds. Moreover, even when only 50 CFD simulations are used for training, the temperature trend (e.g., locations of hot/cold regions) predicted by the ML-surrogate matches quite well with the results from CFD simulations.
Frequency-compensated PINNs for Fluid-dynamic Design Problems
Nov 03, 2020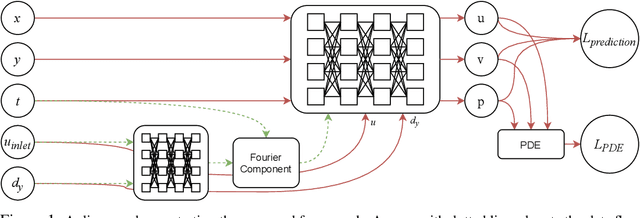
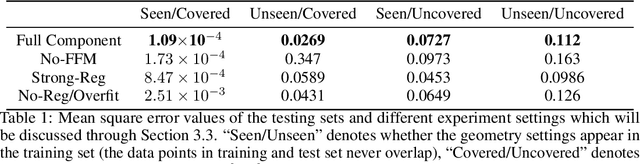
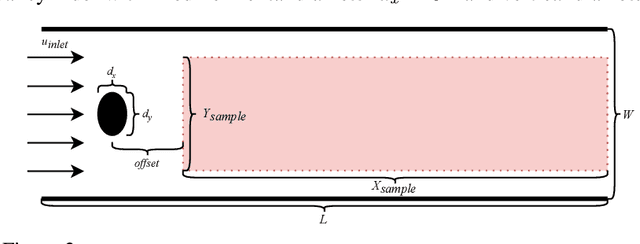
Incompressible fluid flow around a cylinder is one of the classical problems in fluid-dynamics with strong relevance with many real-world engineering problems, for example, design of offshore structures or design of a pin-fin heat exchanger. Thus learning a high-accuracy surrogate for this problem can demonstrate the efficacy of a novel machine learning approach. In this work, we propose a physics-informed neural network (PINN) architecture for learning the relationship between simulation output and the underlying geometry and boundary conditions. In addition to using a physics-based regularization term, the proposed approach also exploits the underlying physics to learn a set of Fourier features, i.e. frequency and phase offset parameters, and then use them for predicting flow velocity and pressure over the spatio-temporal domain. We demonstrate this approach by predicting simulation results over out of range time interval and for novel design conditions. Our results show that incorporation of Fourier features improves the generalization performance over both temporal domain and design space.
Training with Streaming Annotation
Feb 11, 2020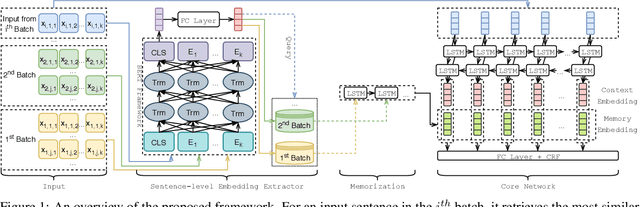
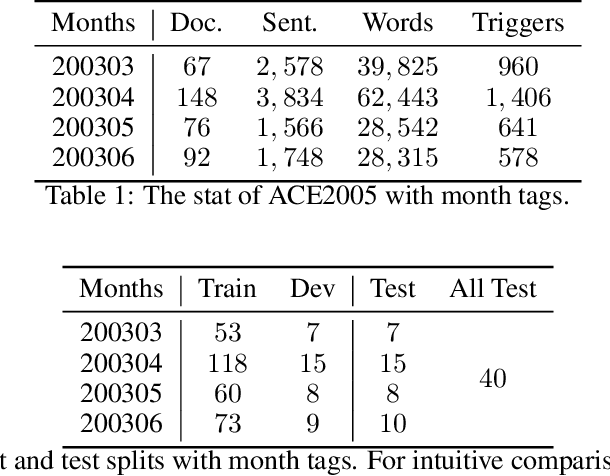
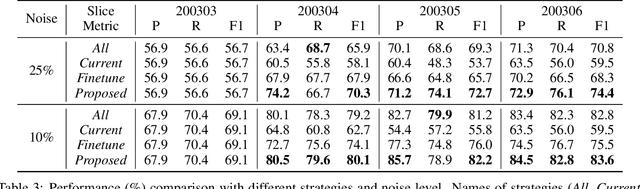
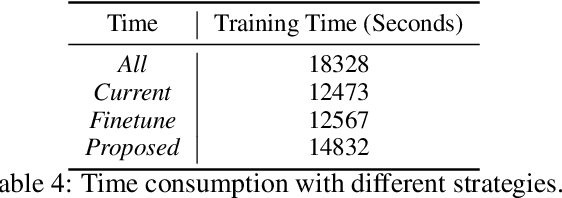
In this paper, we address a practical scenario where training data is released in a sequence of small-scale batches and annotation in earlier phases has lower quality than the later counterparts. To tackle the situation, we utilize a pre-trained transformer network to preserve and integrate the most salient document information from the earlier batches while focusing on the annotation (presumably with higher quality) from the current batch. Using event extraction as a case study, we demonstrate in the experiments that our proposed framework can perform better than conventional approaches (the improvement ranges from 3.6 to 14.9% absolute F-score gain), especially when there is more noise in the early annotation; and our approach spares 19.1% time with regard to the best conventional method.
Seq2RDF: An end-to-end application for deriving Triples from Natural Language Text
Aug 08, 2018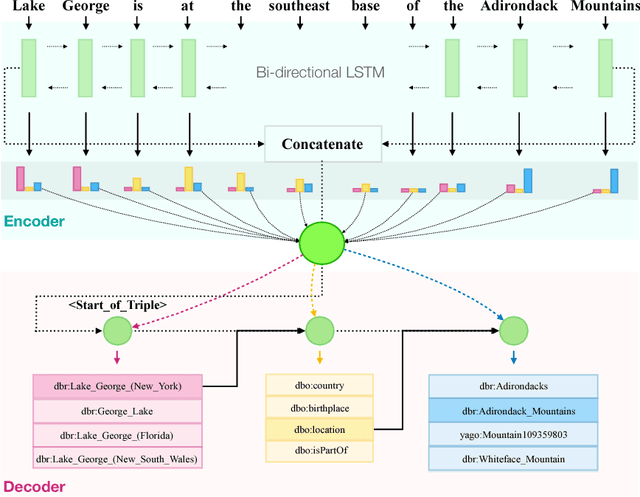
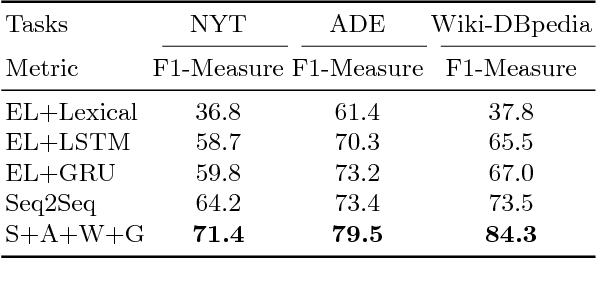
We present an end-to-end approach that takes unstructured textual input and generates structured output compliant with a given vocabulary. Inspired by recent successes in neural machine translation, we treat the triples within a given knowledge graph as an independent graph language and propose an encoder-decoder framework with an attention mechanism that leverages knowledge graph embeddings. Our model learns the mapping from natural language text to triple representation in the form of subject-predicate-object using the selected knowledge graph vocabulary. Experiments on three different data sets show that we achieve competitive F1-Measures over the baselines using our simple yet effective approach. A demo video is included.
Event Extraction with Generative Adversarial Imitation Learning
Apr 21, 2018
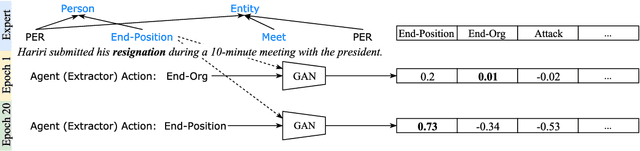
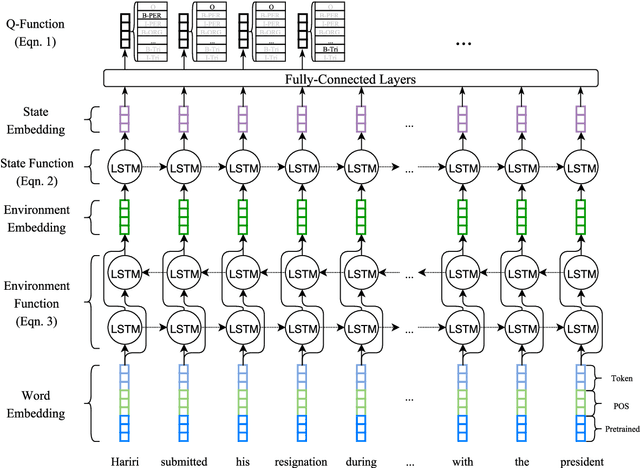

We propose a new method for event extraction (EE) task based on an imitation learning framework, specifically, inverse reinforcement learning (IRL) via generative adversarial network (GAN). The GAN estimates proper rewards according to the difference between the actions committed by the expert (or ground truth) and the agent among complicated states in the environment. EE task benefits from these dynamic rewards because instances and labels yield to various extents of difficulty and the gains are expected to be diverse -- e.g., an ambiguous but correctly detected trigger or argument should receive high gains -- while the traditional RL models usually neglect such differences and pay equal attention on all instances. Moreover, our experiments also demonstrate that the proposed framework outperforms state-of-the-art methods, without explicit feature engineering.