 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaExplainer: A Framework to Generate Multi-Type User-Centered Explanations for AI Systems
Aug 01, 2025Explanations are crucial for building trustworthy AI systems, but a gap often exists between the explanations provided by models and those needed by users. To address this gap, we introduce MetaExplainer, a neuro-symbolic framework designed to generate user-centered explanations. Our approach employs a three-stage process: first, we decompose user questions into machine-readable formats using state-of-the-art large language models (LLM); second, we delegate the task of generating system recommendations to model explainer methods; and finally, we synthesize natural language explanations that summarize the explainer outputs. Throughout this process, we utilize an Explanation Ontology to guide the language models and explainer methods. By leveraging LLMs and a structured approach to explanation generation, MetaExplainer aims to enhance the interpretability and trustworthiness of AI systems across various applications, providing users with tailored, question-driven explanations that better meet their needs. Comprehensive evaluations of MetaExplainer demonstrate a step towards evaluating and utilizing current state-of-the-art explanation frameworks. Our results show high performance across all stages, with a 59.06% F1-score in question reframing, 70% faithfulness in model explanations, and 67% context-utilization in natural language synthesis. User studies corroborate these findings, highlighting the creativity and comprehensiveness of generated explanations. Tested on the Diabetes (PIMA Indian) tabular dataset, MetaExplainer supports diverse explanation types, including Contrastive, Counterfactual, Rationale, Case-Based, and Data explanations. The framework's versatility and traceability from using ontology to guide LLMs suggest broad applicability beyond the tested scenarios, positioning MetaExplainer as a promising tool for enhancing AI explainability across various domains.
Informing clinical assessment by contextualizing post-hoc explanations of risk prediction models in type-2 diabetes
Feb 11, 2023
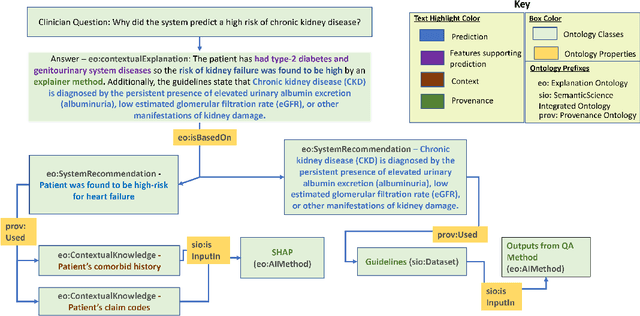


Medical experts may use Artificial Intelligence (AI) systems with greater trust if these are supported by contextual explanations that let the practitioner connect system inferences to their context of use. However, their importance in improving model usage and understanding has not been extensively studied. Hence, we consider a comorbidity risk prediction scenario and focus on contexts regarding the patients clinical state, AI predictions about their risk of complications, and algorithmic explanations supporting the predictions. We explore how relevant information for such dimensions can be extracted from Medical guidelines to answer typical questions from clinical practitioners. We identify this as a question answering (QA) task and employ several state-of-the-art LLMs to present contexts around risk prediction model inferences and evaluate their acceptability. Finally, we study the benefits of contextual explanations by building an end-to-end AI pipeline including data cohorting, AI risk modeling, post-hoc model explanations, and prototyped a visual dashboard to present the combined insights from different context dimensions and data sources, while predicting and identifying the drivers of risk of Chronic Kidney Disease - a common type-2 diabetes comorbidity. All of these steps were performed in engagement with medical experts, including a final evaluation of the dashboard results by an expert medical panel. We show that LLMs, in particular BERT and SciBERT, can be readily deployed to extract some relevant explanations to support clinical usage. To understand the value-add of the contextual explanations, the expert panel evaluated these regarding actionable insights in the relevant clinical setting. Overall, our paper is one of the first end-to-end analyses identifying the feasibility and benefits of contextual explanations in a real-world clinical use case.
A Theoretically Grounded Benchmark for Evaluating Machine Commonsense
Mar 23, 2022

Programming machines with commonsense reasoning (CSR) abilities is a longstanding challenge in the Artificial Intelligence community. Current CSR benchmarks use multiple-choice (and in relatively fewer cases, generative) question-answering instances to evaluate machine commonsense. Recent progress in transformer-based language representation models suggest that considerable progress has been made on existing benchmarks. However, although tens of CSR benchmarks currently exist, and are growing, it is not evident that the full suite of commonsense capabilities have been systematically evaluated. Furthermore, there are doubts about whether language models are 'fitting' to a benchmark dataset's training partition by picking up on subtle, but normatively irrelevant (at least for CSR), statistical features to achieve good performance on the testing partition. To address these challenges, we propose a benchmark called Theoretically-Grounded Commonsense Reasoning (TG-CSR) that is also based on discriminative question answering, but with questions designed to evaluate diverse aspects of commonsense, such as space, time, and world states. TG-CSR is based on a subset of commonsense categories first proposed as a viable theory of commonsense by Gordon and Hobbs. The benchmark is also designed to be few-shot (and in the future, zero-shot), with only a few training and validation examples provided. This report discusses the structure and construction of the benchmark. Preliminary results suggest that the benchmark is challenging even for advanced language representation models designed for discriminative CSR question answering tasks. Benchmark access and leaderboard: https://codalab.lisn.upsaclay.fr/competitions/3080 Benchmark website: https://usc-isi-i2.github.io/TGCSR/
Leveraging Clinical Context for User-Centered Explainability: A Diabetes Use Case
Jul 15, 2021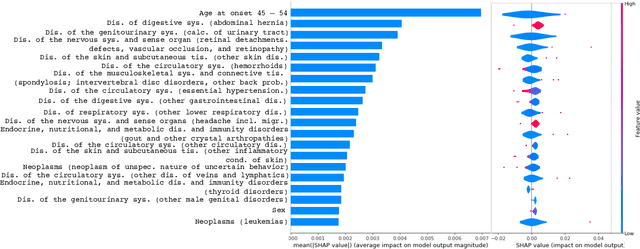

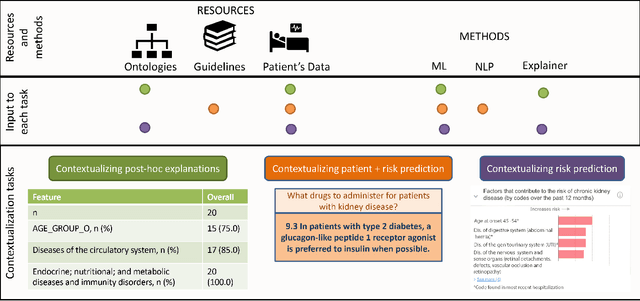
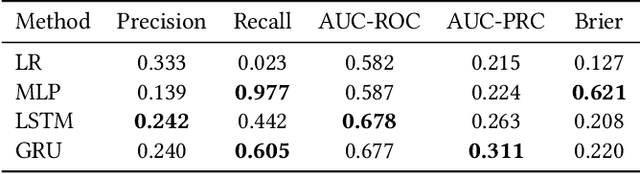
Academic advances of AI models in high-precision domains, like healthcare, need to be made explainable in order to enhance real-world adoption. Our past studies and ongoing interactions indicate that medical experts can use AI systems with greater trust if there are ways to connect the model inferences about patients to explanations that are tied back to the context of use. Specifically, risk prediction is a complex problem of diagnostic and interventional importance to clinicians wherein they consult different sources to make decisions. To enable the adoption of the ever improving AI risk prediction models in practice, we have begun to explore techniques to contextualize such models along three dimensions of interest: the patients' clinical state, AI predictions about their risk of complications, and algorithmic explanations supporting the predictions. We validate the importance of these dimensions by implementing a proof-of-concept (POC) in type-2 diabetes (T2DM) use case where we assess the risk of chronic kidney disease (CKD) - a common T2DM comorbidity. Within the POC, we include risk prediction models for CKD, post-hoc explainers of the predictions, and other natural-language modules which operationalize domain knowledge and CPGs to provide context. With primary care physicians (PCP) as our end-users, we present our initial results and clinician feedback in this paper. Our POC approach covers multiple knowledge sources and clinical scenarios, blends knowledge to explain data and predictions to PCPs, and received an enthusiastic response from our medical expert.
Geospatial Reasoning with Shapefiles for Supporting Policy Decisions
Jun 09, 2021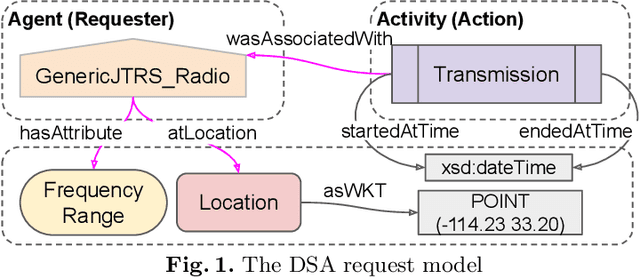
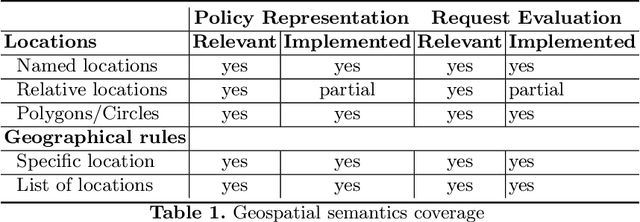
Policies are authoritative assets that are present in multiple domains to support decision-making. They describe what actions are allowed or recommended when domain entities and their attributes satisfy certain criteria. It is common to find policies that contain geographical rules, including distance and containment relationships among named locations. These locations' polygons can often be found encoded in geospatial datasets. We present an approach to transform data from geospatial datasets into Linked Data using the OWL, PROV-O, and GeoSPARQL standards, and to leverage this representation to support automated ontology-based policy decisions. We applied our approach to location-sensitive radio spectrum policies to identify relationships between radio transmitters coordinates and policy-regulated regions in Census.gov datasets. Using a policy evaluation pipeline that mixes OWL reasoning and GeoSPARQL, our approach implements the relevant geospatial relationships, according to a set of requirements elicited by radio spectrum domain experts.
Semantic Modeling for Food Recommendation Explanations
May 04, 2021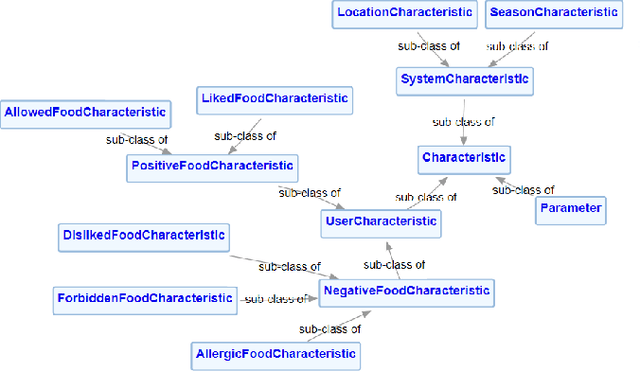

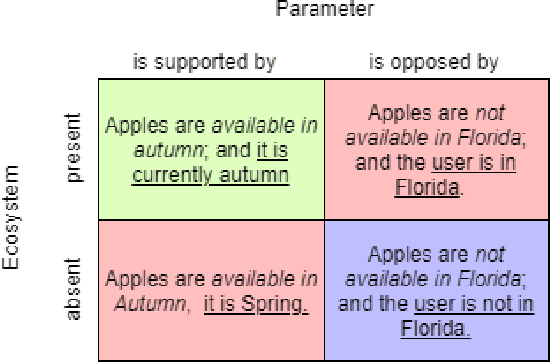
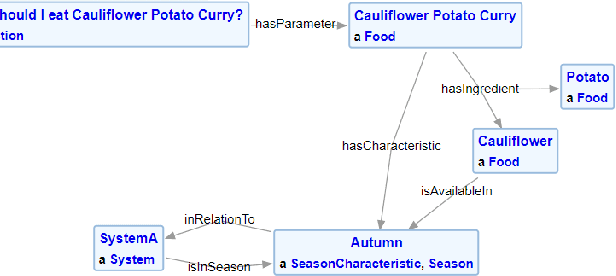
With the increased use of AI methods to provide recommendations in the health, specifically in the food dietary recommendation space, there is also an increased need for explainability of those recommendations. Such explanations would benefit users of recommendation systems by empowering them with justifications for following the system's suggestions. We present the Food Explanation Ontology (FEO) that provides a formalism for modeling explanations to users for food-related recommendations. FEO models food recommendations, using concepts from the explanation domain to create responses to user questions about food recommendations they receive from AI systems such as personalized knowledge base question answering systems. FEO uses a modular, extensible structure that lends itself to a variety of explanations while still preserving important semantic details to accurately represent explanations of food recommendations. In order to evaluate this system, we used a set of competency questions derived from explanation types present in literature that are relevant to food recommendations. Our motivation with the use of FEO is to empower users to make decisions about their health, fully equipped with an understanding of the AI recommender systems as they relate to user questions, by providing reasoning behind their recommendations in the form of explanations.
Applying Personal Knowledge Graphs to Health
Apr 15, 2021Knowledge graphs that encapsulate personal health information, or personal health knowledge graphs (PHKG), can help enable personalized health care in knowledge-driven systems. In this paper we provide a short survey of existing work surrounding the emerging paradigm of PHKGs and highlight the major challenges that remain. We find that while some preliminary exploration exists on the topic of personal knowledge graphs, development of PHKGs remains under-explored. A range of challenges surrounding the collection, linkage, and maintenance of personal health knowledge remains to be addressed to fully realize PHKGs.
Commonsense Knowledge Mining from Term Definitions
Feb 01, 2021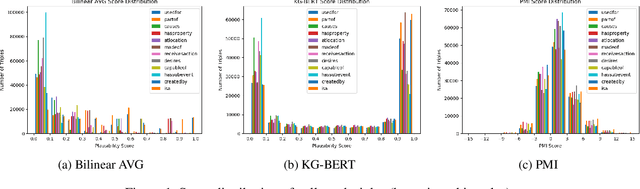
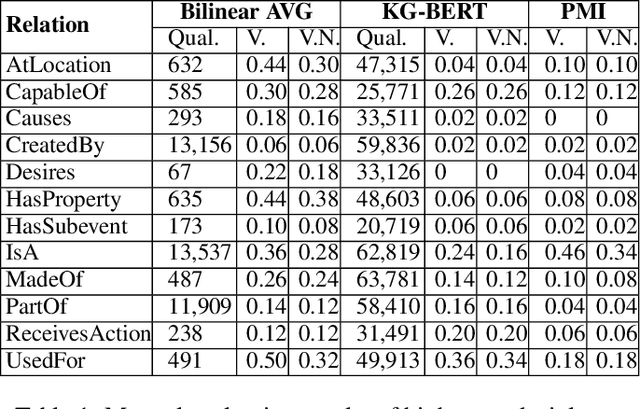
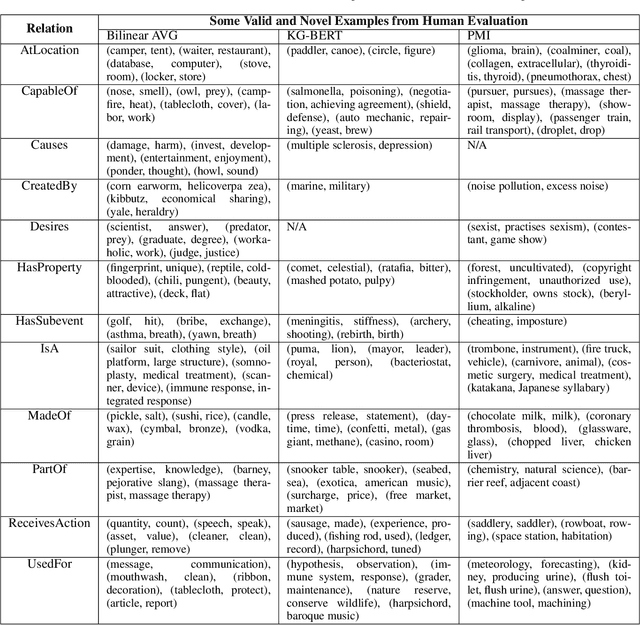

Commonsense knowledge has proven to be beneficial to a variety of application areas, including question answering and natural language understanding. Previous work explored collecting commonsense knowledge triples automatically from text to increase the coverage of current commonsense knowledge graphs. We investigate a few machine learning approaches to mining commonsense knowledge triples using dictionary term definitions as inputs and provide some initial evaluation of the results. We start from extracting candidate triples using part-of-speech tag patterns from text, and then compare the performance of three existing models for triple scoring. Our experiments show that term definitions contain some valid and novel commonsense knowledge triples for some semantic relations, and also indicate some challenges with using existing triple scoring models.
Dimensions of Commonsense Knowledge
Jan 12, 2021
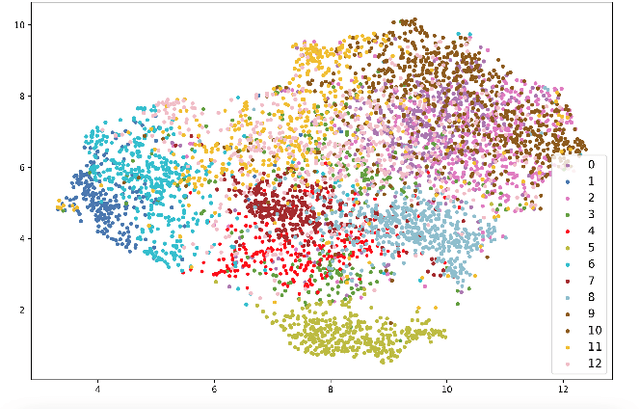
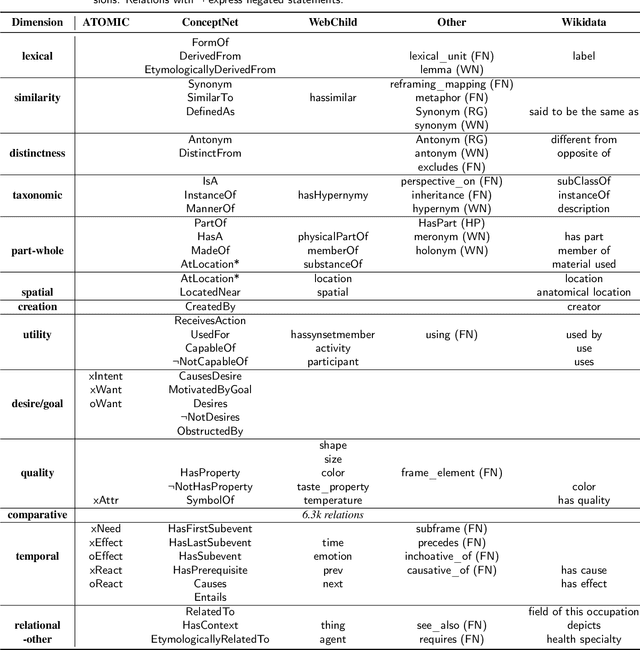
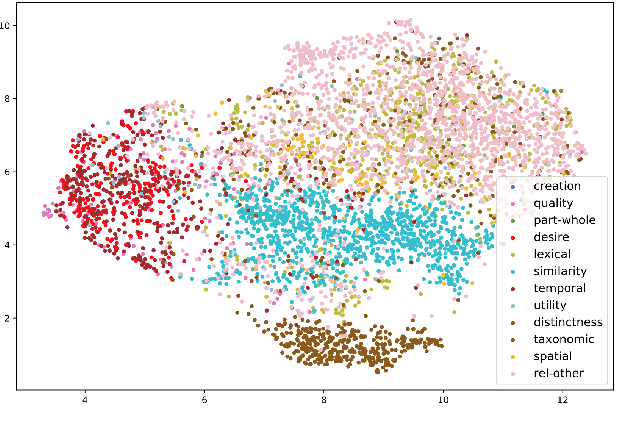
Commonsense knowledge is essential for many AI applications, including those in natural language processing, visual processing, and planning. Consequently, many sources that include commonsense knowledge have been designed and constructed over the past decades. Recently, the focus has been on large text-based sources, which facilitate easier integration with neural (language) models and application on textual tasks, typically at the expense of the semantics of the sources. Such practice prevents the harmonization of these sources, understanding their coverage and gaps, and may hinder the semantic alignment of their knowledge with downstream tasks. Efforts to consolidate commonsense knowledge have yielded partial success, but provide no clear path towards a comprehensive consolidation of existing commonsense knowledge. The ambition of this paper is to organize these sources around a common set of dimensions of commonsense knowledge. For this purpose, we survey a wide range of popular commonsense sources with a special focus on their relations. We consolidate these relations into 13 knowledge dimensions, each abstracting over more specific relations found in sources. This consolidation allows us to unify the separate sources and to compute indications of their coverage, overlap, and gaps with respect to the knowledge dimensions. Moreover, we analyze the impact of each dimension on downstream reasoning tasks that require commonsense knowledge, observing that the temporal and desire/goal dimensions are very beneficial for reasoning on current downstream tasks, while distinctness and lexical knowledge have little impact. These results reveal focus towards some dimensions in current evaluation, and potential neglect of others.
Exploring and Analyzing Machine Commonsense Benchmarks
Dec 21, 2020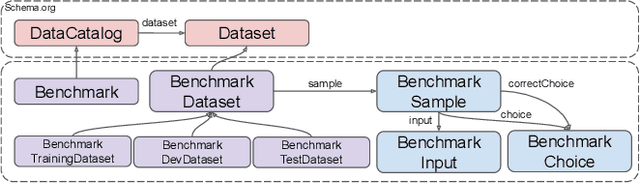


Commonsense question-answering (QA) tasks, in the form of benchmarks, are constantly being introduced for challenging and comparing commonsense QA systems. The benchmarks provide question sets that systems' developers can use to train and test new models before submitting their implementations to official leaderboards. Although these tasks are created to evaluate systems in identified dimensions (e.g. topic, reasoning type), this metadata is limited and largely presented in an unstructured format or completely not present. Because machine common sense is a fast-paced field, the problem of fully assessing current benchmarks and systems with regards to these evaluation dimensions is aggravated. We argue that the lack of a common vocabulary for aligning these approaches' metadata limits researchers in their efforts to understand systems' deficiencies and in making effective choices for future tasks. In this paper, we first discuss this MCS ecosystem in terms of its elements and their metadata. Then, we present how we are supporting the assessment of approaches by initially focusing on commonsense benchmarks. We describe our initial MCS Benchmark Ontology, an extensible common vocabulary that formalizes benchmark metadata, and showcase how it is supporting the development of a Benchmark tool that enables benchmark exploration and analysis.