 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DReflecNet: A Large-Scale Dataset for 3D Reconstruction of Reflective, Transparent, and Low-Texture Objects
May 11, 2026Accurate 3D reconstruction of objects with reflective, transparent, or low-texture surfaces still remains notoriously challenging. Such materials often violate key assumptions in multi-view reconstruction pipelines, such as photometric consistency and the availability on distinct geometric texture cues. Existing datasets primarily focus on diffuse, textured objects, and therefore provide limited insight into performance under real-world material complexities. We introduce 3DReflecNet, a large-scale hybrid dataset exceeding 22 TB that is specifically designed to benchmark and advance 3D vision methods for these challenging materials. 3DReflecNet combines two types of data: over 120,000 synthetic instances generated via physically-based rendering of more than 12,000 shapes, and over 1,000 real-world objects captured using consumer devices. Together, these data consist of more than 7 million multi-view frames. The dataset spans diverse materials, complex lighting conditions, and a wide range of geometric forms, including shapes generated from both real and LLM-synthesized 2D images using diffusion-based pipelines. To support robust evaluation, we design benchmarks for five core tasks: image matching, structure-from-motion, novel view synthesis, reflection removal, and relighting. Extensive experiments demonstrate that state-of-the-art methods struggle to maintain accuracy across these settings, highlighting the need for more resilient 3D vision models.
A Benchmark Study of Deep-RL Methods for Maximum Coverage Problems over Graphs
Jun 20, 2024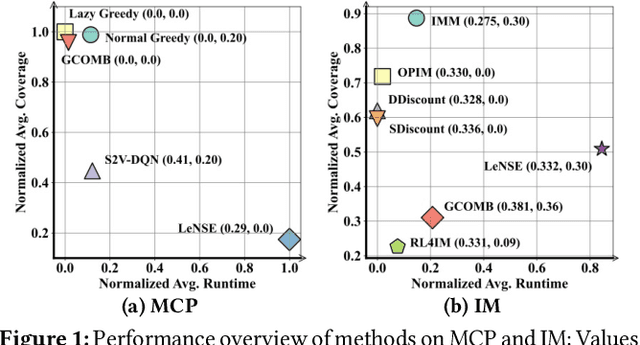
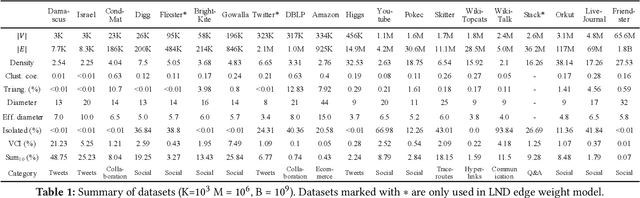
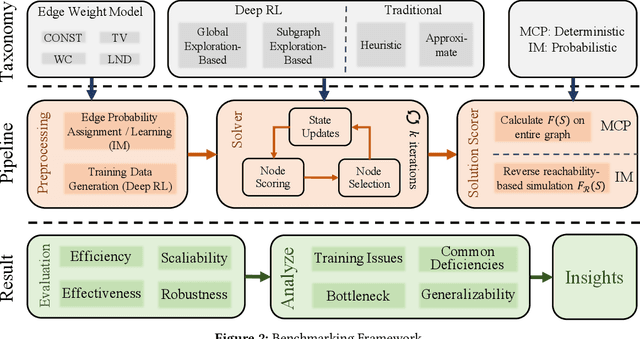
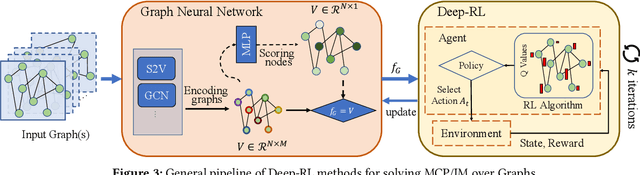
Recent years have witnessed a growing trend toward employing deep reinforcement learning (Deep-RL) to derive heuristics for combinatorial optimization (CO) problems on graphs. Maximum Coverage Problem (MCP) and its probabilistic variant on social networks, Influence Maximization (IM), have been particularly prominent in this line of research. In this paper, we present a comprehensive benchmark study that thoroughly investigates the effectiveness and efficiency of five recent Deep-RL methods for MCP and IM. These methods were published in top data science venues, namely S2V-DQN, Geometric-QN, GCOMB, RL4IM, and LeNSE. Our findings reveal that, across various scenarios, the Lazy Greedy algorithm consistently outperforms all Deep-RL methods for MCP. In the case of IM, theoretically sound algorithms like IMM and OPIM demonstrate superior performance compared to Deep-RL methods in most scenarios. Notably, we observe an abnormal phenomenon in IM problem where Deep-RL methods slightly outperform IMM and OPIM when the influence spread nearly does not increase as the budget increases. Furthermore, our experimental results highlight common issues when applying Deep-RL methods to MCP and IM in practical settings. Finally, we discuss potential avenues for improving Deep-RL methods. Our benchmark study sheds light on potential challenges in current deep reinforcement learning research for solving combinatorial optimization problems.
Commonsense Knowledge Mining from Term Definitions
Feb 01, 2021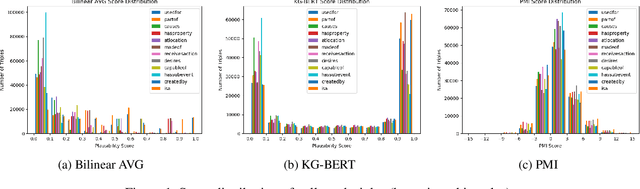
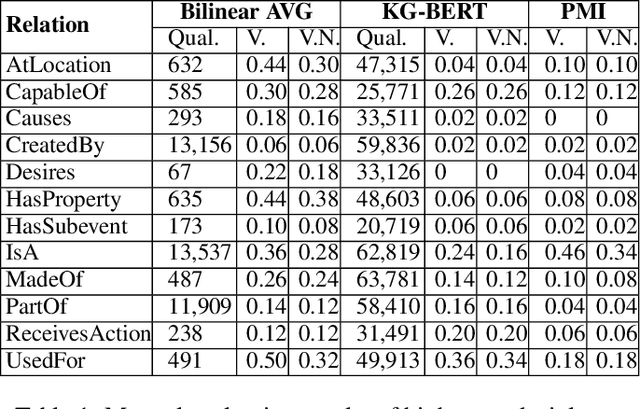
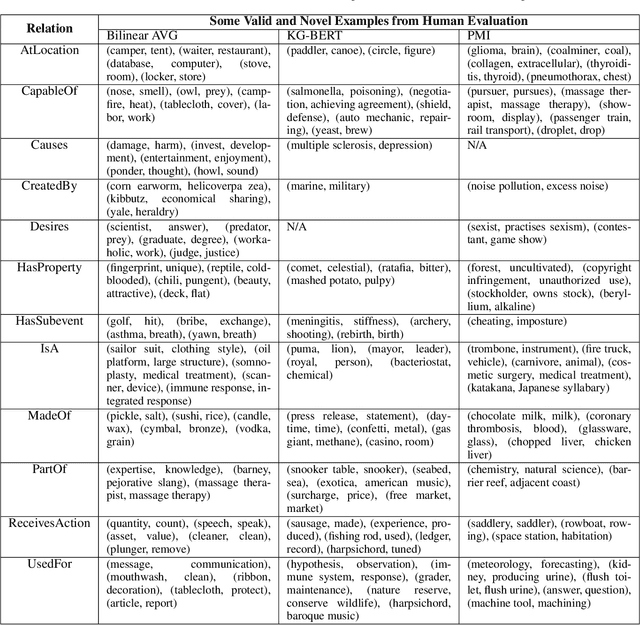

Commonsense knowledge has proven to be beneficial to a variety of application areas, including question answering and natural language understanding. Previous work explored collecting commonsense knowledge triples automatically from text to increase the coverage of current commonsense knowledge graphs. We investigate a few machine learning approaches to mining commonsense knowledge triples using dictionary term definitions as inputs and provide some initial evaluation of the results. We start from extracting candidate triples using part-of-speech tag patterns from text, and then compare the performance of three existing models for triple scoring. Our experiments show that term definitions contain some valid and novel commonsense knowledge triples for some semantic relations, and also indicate some challenges with using existing triple scoring models.
Exploring and Analyzing Machine Commonsense Benchmarks
Dec 21, 2020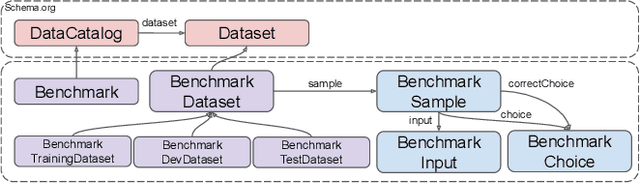


Commonsense question-answering (QA) tasks, in the form of benchmarks, are constantly being introduced for challenging and comparing commonsense QA systems. The benchmarks provide question sets that systems' developers can use to train and test new models before submitting their implementations to official leaderboards. Although these tasks are created to evaluate systems in identified dimensions (e.g. topic, reasoning type), this metadata is limited and largely presented in an unstructured format or completely not present. Because machine common sense is a fast-paced field, the problem of fully assessing current benchmarks and systems with regards to these evaluation dimensions is aggravated. We argue that the lack of a common vocabulary for aligning these approaches' metadata limits researchers in their efforts to understand systems' deficiencies and in making effective choices for future tasks. In this paper, we first discuss this MCS ecosystem in terms of its elements and their metadata. Then, we present how we are supporting the assessment of approaches by initially focusing on commonsense benchmarks. We describe our initial MCS Benchmark Ontology, an extensible common vocabulary that formalizes benchmark metadata, and showcase how it is supporting the development of a Benchmark tool that enables benchmark exploration and analysis.
Seq2RDF: An end-to-end application for deriving Triples from Natural Language Text
Aug 08, 2018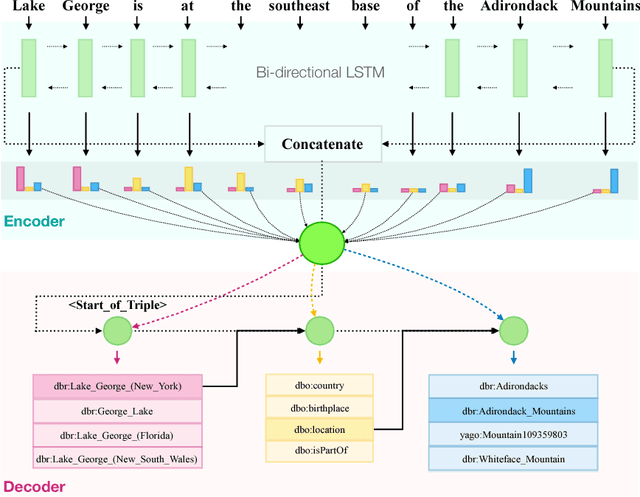
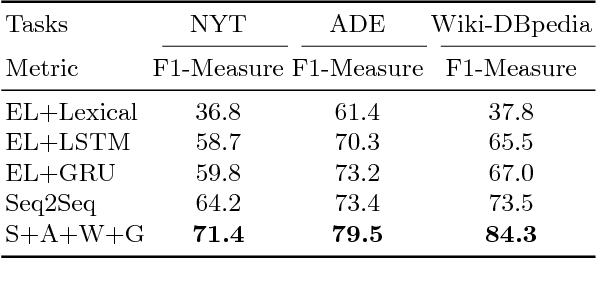
We present an end-to-end approach that takes unstructured textual input and generates structured output compliant with a given vocabulary. Inspired by recent successes in neural machine translation, we treat the triples within a given knowledge graph as an independent graph language and propose an encoder-decoder framework with an attention mechanism that leverages knowledge graph embeddings. Our model learns the mapping from natural language text to triple representation in the form of subject-predicate-object using the selected knowledge graph vocabulary. Experiments on three different data sets show that we achieve competitive F1-Measures over the baselines using our simple yet effective approach. A demo video is included.