 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring and Analyzing Machine Commonsense Benchmarks
Paper and Code
Dec 21, 2020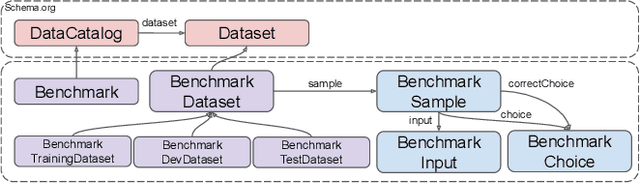


Commonsense question-answering (QA) tasks, in the form of benchmarks, are constantly being introduced for challenging and comparing commonsense QA systems. The benchmarks provide question sets that systems' developers can use to train and test new models before submitting their implementations to official leaderboards. Although these tasks are created to evaluate systems in identified dimensions (e.g. topic, reasoning type), this metadata is limited and largely presented in an unstructured format or completely not present. Because machine common sense is a fast-paced field, the problem of fully assessing current benchmarks and systems with regards to these evaluation dimensions is aggravated. We argue that the lack of a common vocabulary for aligning these approaches' metadata limits researchers in their efforts to understand systems' deficiencies and in making effective choices for future tasks. In this paper, we first discuss this MCS ecosystem in terms of its elements and their metadata. Then, we present how we are supporting the assessment of approaches by initially focusing on commonsense benchmarks. We describe our initial MCS Benchmark Ontology, an extensible common vocabulary that formalizes benchmark metadata, and showcase how it is supporting the development of a Benchmark tool that enables benchmark exploration and analysis.