 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretically Grounded Benchmark for Evaluating Machine Commonsense
Mar 23, 2022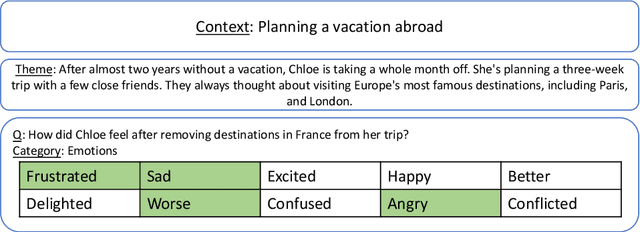

Programming machines with commonsense reasoning (CSR) abilities is a longstanding challenge in the Artificial Intelligence community. Current CSR benchmarks use multiple-choice (and in relatively fewer cases, generative) question-answering instances to evaluate machine commonsense. Recent progress in transformer-based language representation models suggest that considerable progress has been made on existing benchmarks. However, although tens of CSR benchmarks currently exist, and are growing, it is not evident that the full suite of commonsense capabilities have been systematically evaluated. Furthermore, there are doubts about whether language models are 'fitting' to a benchmark dataset's training partition by picking up on subtle, but normatively irrelevant (at least for CSR), statistical features to achieve good performance on the testing partition. To address these challenges, we propose a benchmark called Theoretically-Grounded Commonsense Reasoning (TG-CSR) that is also based on discriminative question answering, but with questions designed to evaluate diverse aspects of commonsense, such as space, time, and world states. TG-CSR is based on a subset of commonsense categories first proposed as a viable theory of commonsense by Gordon and Hobbs. The benchmark is also designed to be few-shot (and in the future, zero-shot), with only a few training and validation examples provided. This report discusses the structure and construction of the benchmark. Preliminary results suggest that the benchmark is challenging even for advanced language representation models designed for discriminative CSR question answering tasks. Benchmark access and leaderboard: https://codalab.lisn.upsaclay.fr/competitions/3080 Benchmark website: https://usc-isi-i2.github.io/TGCSR/
Geospatial Reasoning with Shapefiles for Supporting Policy Decisions
Jun 09, 2021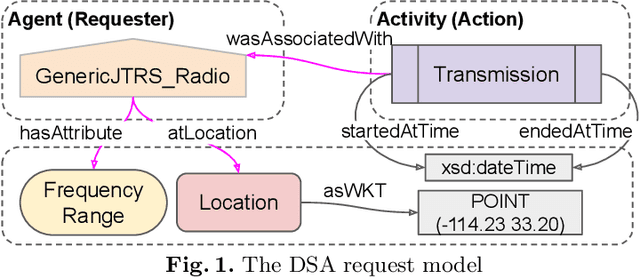
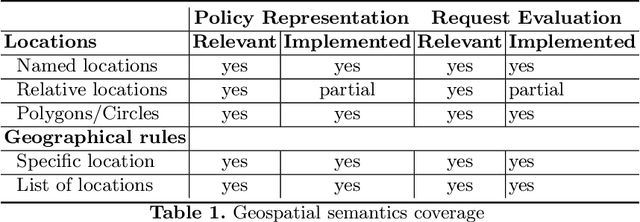
Policies are authoritative assets that are present in multiple domains to support decision-making. They describe what actions are allowed or recommended when domain entities and their attributes satisfy certain criteria. It is common to find policies that contain geographical rules, including distance and containment relationships among named locations. These locations' polygons can often be found encoded in geospatial datasets. We present an approach to transform data from geospatial datasets into Linked Data using the OWL, PROV-O, and GeoSPARQL standards, and to leverage this representation to support automated ontology-based policy decisions. We applied our approach to location-sensitive radio spectrum policies to identify relationships between radio transmitters coordinates and policy-regulated regions in Census.gov datasets. Using a policy evaluation pipeline that mixes OWL reasoning and GeoSPARQL, our approach implements the relevant geospatial relationships, according to a set of requirements elicited by radio spectrum domain experts.
Exploring and Analyzing Machine Commonsense Benchmarks
Dec 21, 2020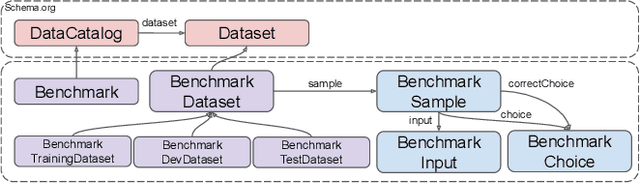


Commonsense question-answering (QA) tasks, in the form of benchmarks, are constantly being introduced for challenging and comparing commonsense QA systems. The benchmarks provide question sets that systems' developers can use to train and test new models before submitting their implementations to official leaderboards. Although these tasks are created to evaluate systems in identified dimensions (e.g. topic, reasoning type), this metadata is limited and largely presented in an unstructured format or completely not present. Because machine common sense is a fast-paced field, the problem of fully assessing current benchmarks and systems with regards to these evaluation dimensions is aggravated. We argue that the lack of a common vocabulary for aligning these approaches' metadata limits researchers in their efforts to understand systems' deficiencies and in making effective choices for future tasks. In this paper, we first discuss this MCS ecosystem in terms of its elements and their metadata. Then, we present how we are supporting the assessment of approaches by initially focusing on commonsense benchmarks. We describe our initial MCS Benchmark Ontology, an extensible common vocabulary that formalizes benchmark metadata, and showcase how it is supporting the development of a Benchmark tool that enables benchmark exploration and analysis.
From Data to City Indicators: A Knowledge Graph for Supporting Automatic Generation of Dashboards
Apr 06, 2017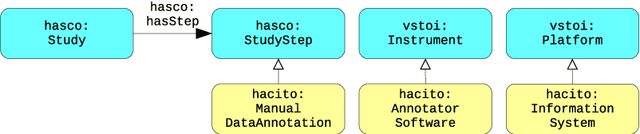
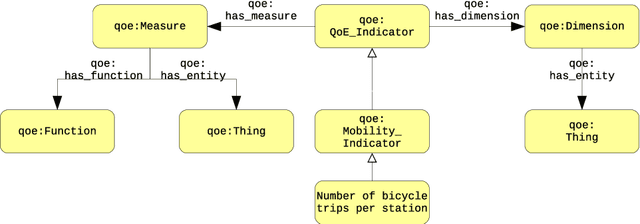
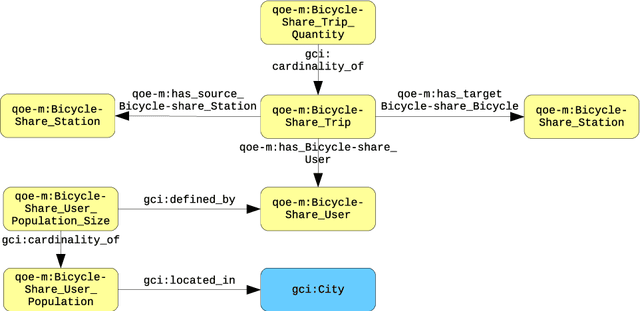
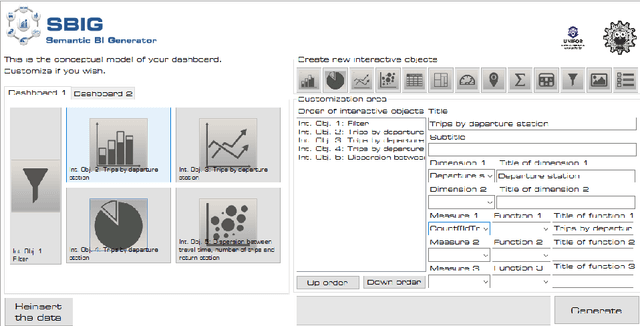
In the context of Smart Cities, indicator definitions have been used to calculate values that enable the comparison among different cities. The calculation of an indicator values has challenges as the calculation may need to combine some aspects of quality while addressing different levels of abstraction. Knowledge graphs (KGs) have been used successfully to support flexible representation, which can support improved understanding and data analysis in similar settings. This paper presents an operational description for a city KG, an indicator ontology that support indicator discovery and data visualization and an application capable of performing metadata analysis to automatically build and display dashboards according to discovered indicators. We describe our implementation in an urban mobility setting.
A Service-Oriented Architecture for Assisting the Authoring of Semantic Crowd Maps
Apr 06, 2017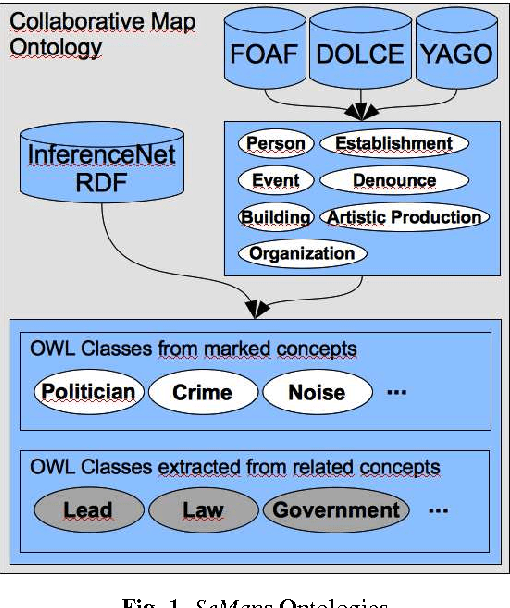
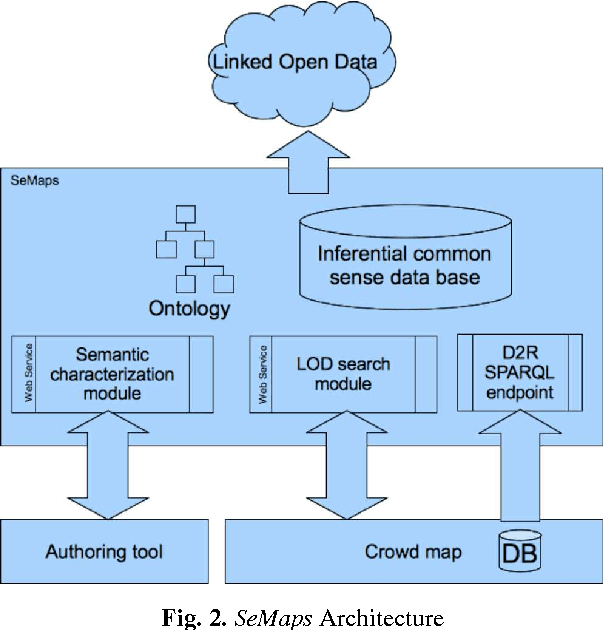
Although there are increasingly more initiatives for the generation of semantic knowledge based on user participation, there is still a shortage of platforms for regular users to create applications on which semantic data can be exploited and generated automatically. We propose an architecture, called Semantic Maps (SeMaps), for assisting the authoring and hosting of applications in which the maps combine the aggregation of a Geographic Information System and crowd-generated content (called here crowd maps). In these systems, the digital map works as a blackboard for accommodating stories told by people about events they want to share with others typically participating in their social networks. SeMaps offers an environment for the creation and maintenance of sites based on crowd maps with the possibility for the user to characterize semantically that which s/he intends to mark on the map. The designer of a crowd map, by informing a linguistic expression that designates what has to be marked on the maps, is guided in a process that aims to associate a concept from a common-sense base to this linguistic expression. Thus, the crowd maps start to have dominion over common-sense inferential relations that define the meaning of the marker, and are able to make inferences about the network of linked data. This makes it possible to generate maps that have the power to perform inferences and access external sources (such as DBpedia) that constitute information that is useful and appropriate to the context of the map. In this paper we describe the architecture of SeMaps and how it was applied in a crowd map authoring tool.
Human-Aware Sensor Network Ontology: Semantic Support for Empirical Data Collection
Apr 06, 2017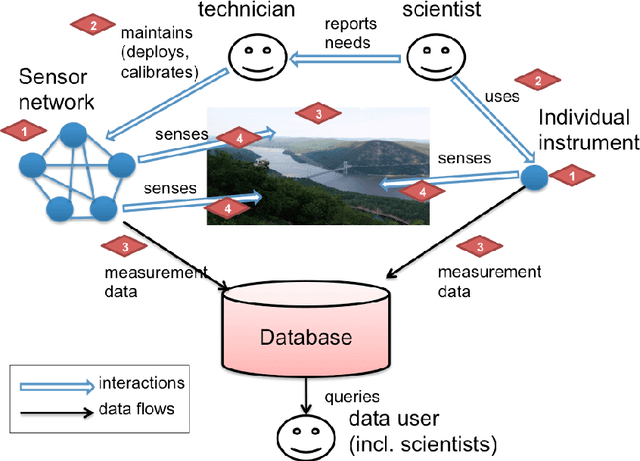
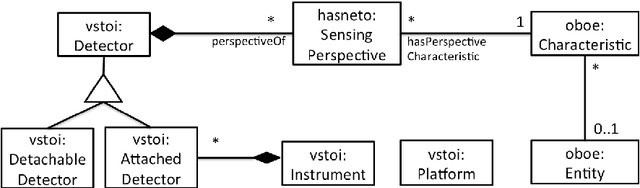

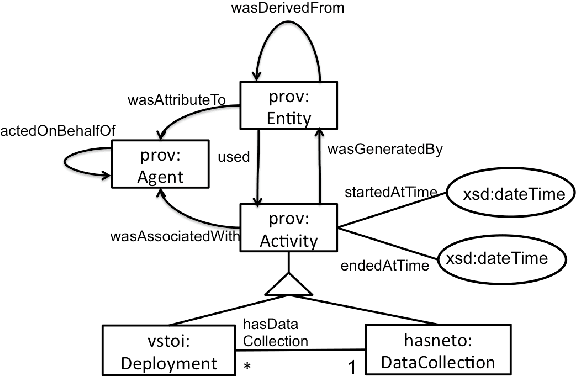
Significant efforts have been made to understand and document knowledge related to scientific measurements. Many of those efforts resulted in one or more high-quality ontologies that describe some aspects of scientific measurements, but not in a comprehensive and coherently integrated manner. For instance, we note that many of these high-quality ontologies are not properly aligned, and more challenging, that they have different and often conflicting concepts and approaches for encoding knowledge about empirical measurements. As a result of this lack of an integrated view, it is often challenging for scientists to determine whether any two scientific measurements were taken in semantically compatible manners, thus making it difficult to decide whether measurements should be analyzed in combination or not. In this paper, we present the Human-Aware Sensor Network Ontology that is a comprehensive alignment and integration of a sensing infrastructure ontology and a provenance ontology. HASNetO has been under development for more than one year, and has been reviewed, shared and used by multiple scientific communities. The ontology has been in use to support the data management of a number of large-scale ecological monitoring activities (observations) and empirical experiments.
Contextual Data Collection for Smart Cities
Apr 06, 2017


As part of Smart Cities initiatives, national, regional and local governments all over the globe are under the mandate of being more open regarding how they share their data. Under this mandate, many of these governments are publishing data under the umbrella of open government data, which includes measurement data from city-wide sensor networks. Furthermore, many of these data are published in so-called data portals as documents that may be spreadsheets, comma-separated value (CSV) data files, or plain documents in PDF or Word documents. The sharing of these documents may be a convenient way for the data provider to convey and publish data but it is not the ideal way for data consumers to reuse the data. For example, the problems of reusing the data may range from difficulty opening a document that is provided in any format that is not plain text, to the actual problem of understanding the meaning of each piece of knowledge inside of the document. Our proposal tackles those challenges by identifying metadata that has been regarded to be relevant for measurement data and providing a schema for this metadata. We further leverage the Human-Aware Sensor Network Ontology (HASNetO) to build an architecture for data collected in urban environments. We discuss the use of HASNetO and the supporting infrastructure to manage both data and metadata in support of the City of Fortaleza, a large metropolitan area in Brazil.
Geracao Automatica de Paineis de Controle para Analise de Mobilidade Urbana Utilizando Redes Complexas
Apr 04, 2017In this paper we describe an automatic generator to support the data scientist to construct, in a user-friendly way, dashboards from data represented as networks. The generator called SBINet (Semantic for Business Intelligence from Networks) has a semantic layer that, through ontologies, describes the data that represents a network as well as the possible metrics to be calculated in the network. Thus, with SBINet, the stages of the dashboard constructing process that uses complex network metrics are facilitated and can be done by users who do not necessarily know about complex networks.