 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Temporal Clustering Algorithm for Achieving the trade-off between the User Experience and the Equipment Economy in the Context of IoT
Jul 30, 2019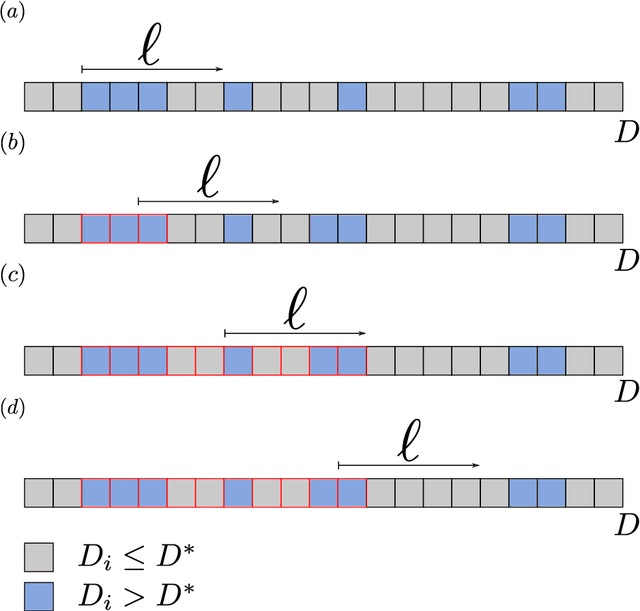
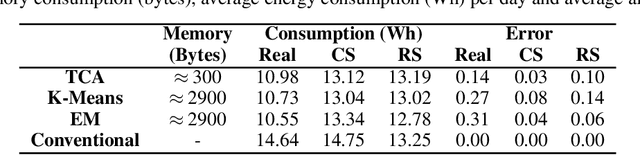
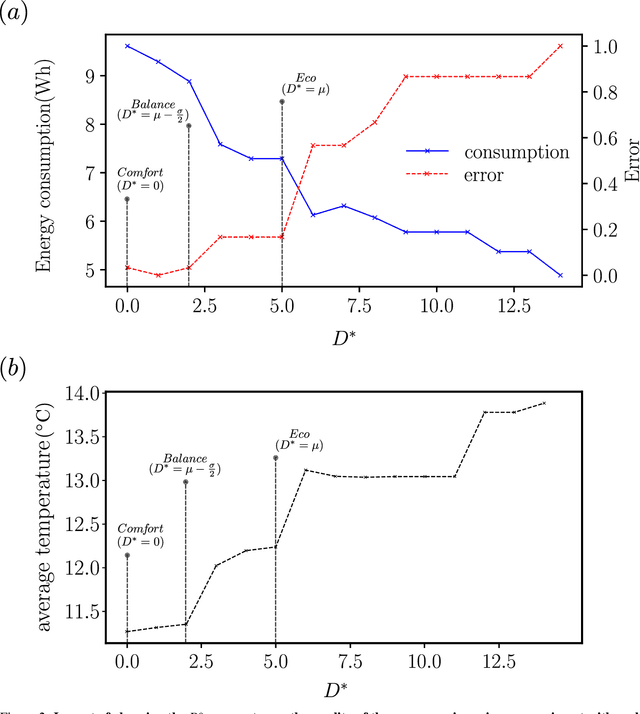
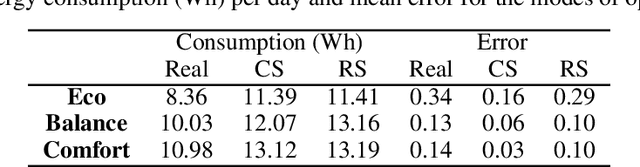
We present here the Temporal Clustering Algorithm (TCA), an incremental learning algorithm applicable to problems of anticipatory computing in the context of the Internet of Things. This algorithm was tested in a specific prediction scenario of consumption of an electric water dispenser typically used in tropical countries, in which the ambient temperature is around 30-degree Celsius. In this context, the user typically wants to drinking iced water therefore uses the cooler function of the dispenser. Real and synthetic water consumption data was used to test a forecasting capacity on how much energy can be saved by predicting the pattern of use of the equipment. In addition to using a small constant amount of memory, which allows the algorithm to be implemented at the lowest cost, while using microcontrollers with a small amount of memory (less than 1Kbyte) available on the market. The algorithm can also be configured according to user preference, prioritizing comfort, keeping the water at the desired temperature longer, or prioritizing energy savings. The main result is that the TCA achieved energy savings of up to 40% compared to the conventional mode of operation of the dispenser with an average success rate higher than 90% in its times of use.
From Data to City Indicators: A Knowledge Graph for Supporting Automatic Generation of Dashboards
Apr 06, 2017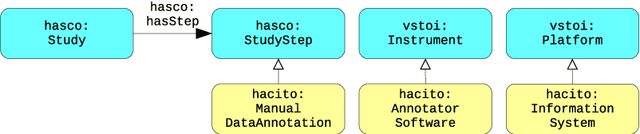
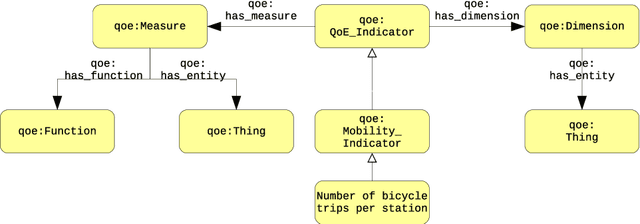
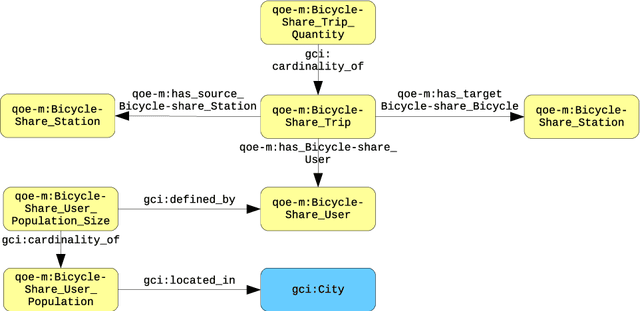
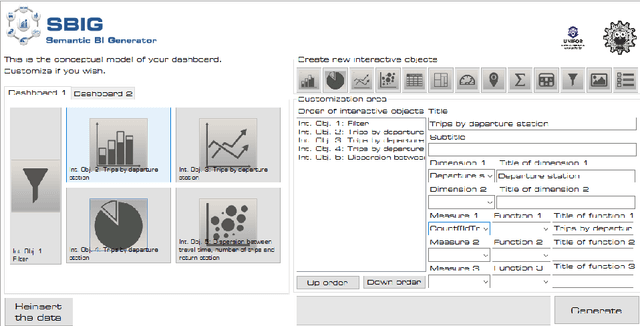
In the context of Smart Cities, indicator definitions have been used to calculate values that enable the comparison among different cities. The calculation of an indicator values has challenges as the calculation may need to combine some aspects of quality while addressing different levels of abstraction. Knowledge graphs (KGs) have been used successfully to support flexible representation, which can support improved understanding and data analysis in similar settings. This paper presents an operational description for a city KG, an indicator ontology that support indicator discovery and data visualization and an application capable of performing metadata analysis to automatically build and display dashboards according to discovered indicators. We describe our implementation in an urban mobility setting.
A Service-Oriented Architecture for Assisting the Authoring of Semantic Crowd Maps
Apr 06, 2017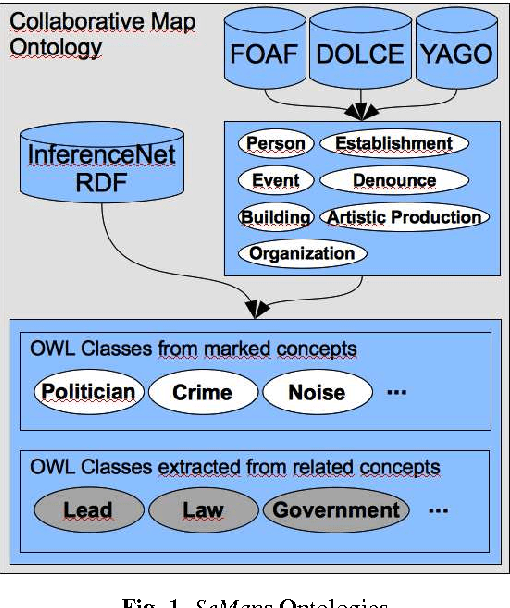
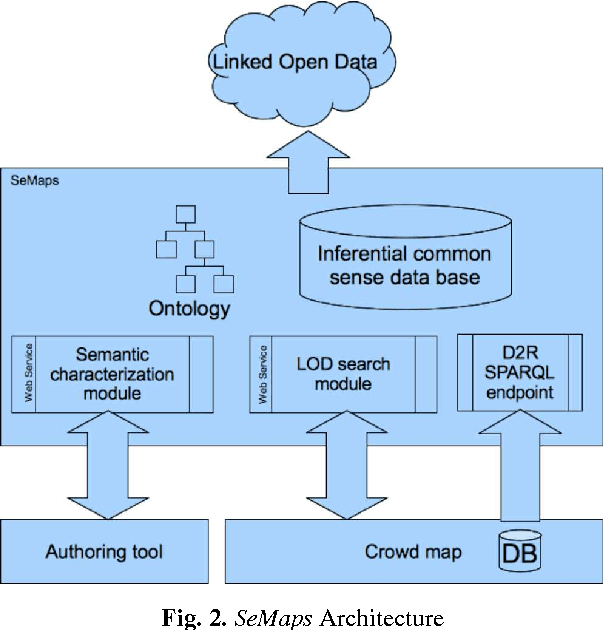
Although there are increasingly more initiatives for the generation of semantic knowledge based on user participation, there is still a shortage of platforms for regular users to create applications on which semantic data can be exploited and generated automatically. We propose an architecture, called Semantic Maps (SeMaps), for assisting the authoring and hosting of applications in which the maps combine the aggregation of a Geographic Information System and crowd-generated content (called here crowd maps). In these systems, the digital map works as a blackboard for accommodating stories told by people about events they want to share with others typically participating in their social networks. SeMaps offers an environment for the creation and maintenance of sites based on crowd maps with the possibility for the user to characterize semantically that which s/he intends to mark on the map. The designer of a crowd map, by informing a linguistic expression that designates what has to be marked on the maps, is guided in a process that aims to associate a concept from a common-sense base to this linguistic expression. Thus, the crowd maps start to have dominion over common-sense inferential relations that define the meaning of the marker, and are able to make inferences about the network of linked data. This makes it possible to generate maps that have the power to perform inferences and access external sources (such as DBpedia) that constitute information that is useful and appropriate to the context of the map. In this paper we describe the architecture of SeMaps and how it was applied in a crowd map authoring tool.
Contextual Data Collection for Smart Cities
Apr 06, 2017


As part of Smart Cities initiatives, national, regional and local governments all over the globe are under the mandate of being more open regarding how they share their data. Under this mandate, many of these governments are publishing data under the umbrella of open government data, which includes measurement data from city-wide sensor networks. Furthermore, many of these data are published in so-called data portals as documents that may be spreadsheets, comma-separated value (CSV) data files, or plain documents in PDF or Word documents. The sharing of these documents may be a convenient way for the data provider to convey and publish data but it is not the ideal way for data consumers to reuse the data. For example, the problems of reusing the data may range from difficulty opening a document that is provided in any format that is not plain text, to the actual problem of understanding the meaning of each piece of knowledge inside of the document. Our proposal tackles those challenges by identifying metadata that has been regarded to be relevant for measurement data and providing a schema for this metadata. We further leverage the Human-Aware Sensor Network Ontology (HASNetO) to build an architecture for data collected in urban environments. We discuss the use of HASNetO and the supporting infrastructure to manage both data and metadata in support of the City of Fortaleza, a large metropolitan area in Brazil.
Geracao Automatica de Paineis de Controle para Analise de Mobilidade Urbana Utilizando Redes Complexas
Apr 04, 2017In this paper we describe an automatic generator to support the data scientist to construct, in a user-friendly way, dashboards from data represented as networks. The generator called SBINet (Semantic for Business Intelligence from Networks) has a semantic layer that, through ontologies, describes the data that represents a network as well as the possible metrics to be calculated in the network. Thus, with SBINet, the stages of the dashboard constructing process that uses complex network metrics are facilitated and can be done by users who do not necessarily know about complex networks.
Detecção de comunidades em redes complexas para identificar gargalos e desperdício de recursos em sistemas de ônibus
Mar 31, 2017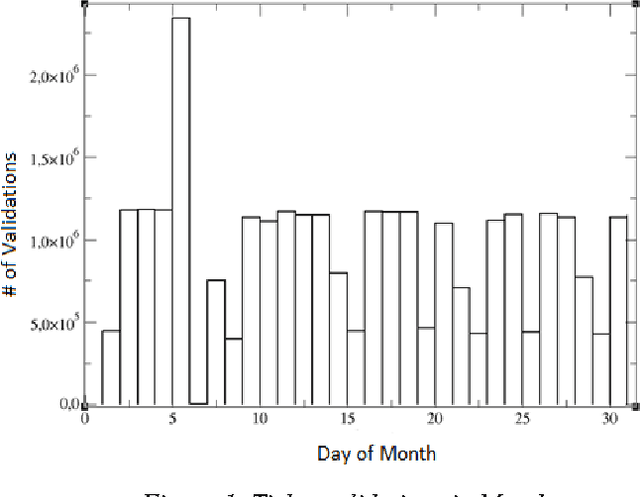
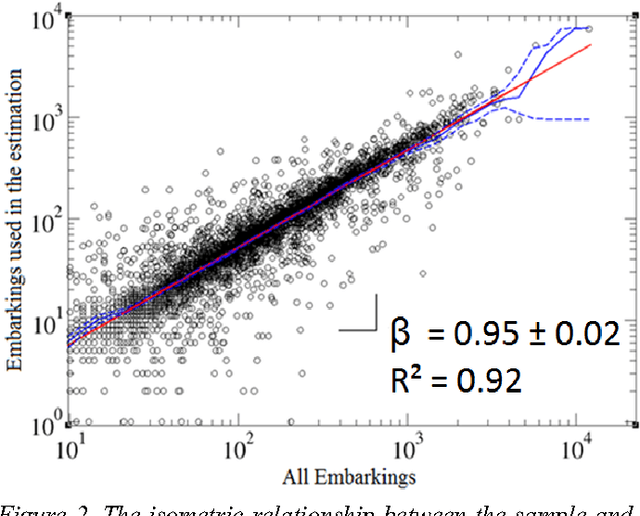

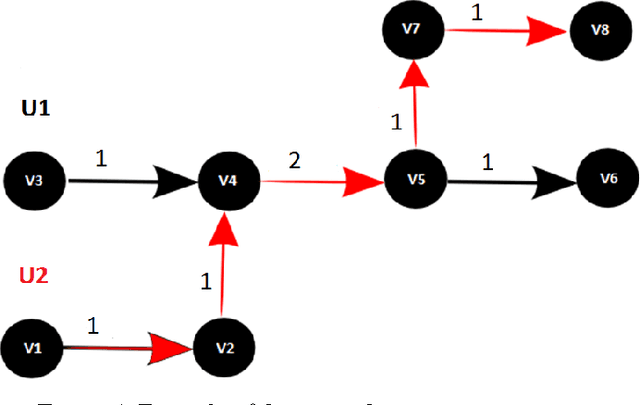
We propose here a methodology to help to understand the shortcomings of public transportation in a city via the mining of complex networks representing the supply and demand of public transport. We show how to build these networks based upon data on smart card use in buses via the application of algorithms that estimate an OD and reconstruct the complete itinerary of the passengers. The overlapping of the two networks sheds light in potential overload and waste in the offer of resources that can be mitigated with strategies for balancing supply and demand.
Micro-interventions in urban transport from pattern discovery on the flow of passengers and on the bus network
Jun 14, 2016



In this paper, we describe a case study in a big metropolis, in which from data collected by digital sensors, we tried to understand mobility patterns of persons using buses and how this can generate knowledge to suggest interventions that are applied incrementally into the transportation network in use. We have first estimated an Origin-Destination matrix of buses users from datasets about the ticket validation and GPS positioning of buses. Then we represent the supply of buses with their routes through bus stops as a complex network, which allowed us to understand the bottlenecks of the current scenario and, in particular, applying community discovery techniques, to identify clusters that the service supply infrastructure has. Finally, from the superimposing of the flow of people represented in the OriginDestination matrix in the supply network, we exemplify how micro-interventions can be prospected by means of an example of the introduction of express routes.