 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurtleBench: A Visual Programming Benchmark in Turtle Geometry
Oct 31, 2024



Humans have the ability to reason about geometric patterns in images and scenes from a young age. However, developing large multimodal models (LMMs) capable of similar reasoning remains a challenge, highlighting the need for robust evaluation methods to assess these capabilities. We introduce TurtleBench, a benchmark designed to evaluate LMMs' capacity to interpret geometric patterns -- given visual examples, textual instructions, or both -- and generate precise code outputs. Inspired by turtle geometry, a notion used to teach children foundational coding and geometric concepts, TurtleBench features tasks with patterned shapes that have underlying algorithmic logic. Our evaluation reveals that leading LMMs struggle significantly with these tasks, with GPT-4o achieving only 19\% accuracy on the simplest tasks and few-shot prompting only marginally improves their performance ($<2\%$). TurtleBench highlights the gap between human and AI performance in intuitive and visual geometrical understanding, setting the stage for future research in this area. TurtleBench stands as one of the few benchmarks to evaluate the integration of visual understanding and code generation capabilities in LMMs, setting the stage for future research. Code and Dataset for this paper is provided here: https://github.com/sinaris76/TurtleBench
Nudging: Inference-time Alignment via Model Collaboration
Oct 15, 2024



Large language models (LLMs) require alignment, such as instruction-tuning or reinforcement learning from human feedback, to effectively and safely follow user instructions. This process necessitates training aligned versions for every model size in each model family, resulting in significant computational overhead. In this work, we propose nudging, a simple, plug-and-play, and training-free algorithm that aligns any base model at inference time using a small aligned model. Nudging is motivated by recent findings that alignment primarily alters the model's behavior on a small subset of stylistic tokens, such as "Sure" or "Thank". We find that base models are significantly more uncertain when generating these tokens. Leveraging this observation, nudging employs a small aligned model to generate nudging tokens to steer the large base model's output toward desired directions when the base model's uncertainty is high. We evaluate the effectiveness of nudging across 3 model families and 13 tasks, covering reasoning, general knowledge, instruction following, and safety benchmarks. Without any additional training, nudging a large base model with a 7x - 14x smaller aligned model achieves zero-shot performance comparable to, and sometimes surpassing, that of large aligned models. For example, nudging OLMo-7b with OLMo-1b-instruct, affecting less than 9% of tokens, achieves a 10% absolute improvement on GSM8K over OLMo-7b-instruct. Unlike prior inference-time tuning methods, nudging enables off-the-shelf collaboration between model families. For instance, nudging Gemma-2-27b with Llama-2-7b-chat outperforms Llama-2-70b-chat on various tasks. Overall, this work introduces a simple yet powerful approach to token-level model collaboration, offering a modular solution to LLM alignment. Our project website: https://fywalter.github.io/nudging/ .
Are Models Biased on Text without Gender-related Language?
May 01, 2024Gender bias research has been pivotal in revealing undesirable behaviors in large language models, exposing serious gender stereotypes associated with occupations, and emotions. A key observation in prior work is that models reinforce stereotypes as a consequence of the gendered correlations that are present in the training data. In this paper, we focus on bias where the effect from training data is unclear, and instead address the question: Do language models still exhibit gender bias in non-stereotypical settings? To do so, we introduce UnStereoEval (USE), a novel framework tailored for investigating gender bias in stereotype-free scenarios. USE defines a sentence-level score based on pretraining data statistics to determine if the sentence contain minimal word-gender associations. To systematically benchmark the fairness of popular language models in stereotype-free scenarios, we utilize USE to automatically generate benchmarks without any gender-related language. By leveraging USE's sentence-level score, we also repurpose prior gender bias benchmarks (Winobias and Winogender) for non-stereotypical evaluation. Surprisingly, we find low fairness across all 28 tested models. Concretely, models demonstrate fair behavior in only 9%-41% of stereotype-free sentences, suggesting that bias does not solely stem from the presence of gender-related words. These results raise important questions about where underlying model biases come from and highlight the need for more systematic and comprehensive bias evaluation. We release the full dataset and code at https://ucinlp.github.io/unstereo-eval.
EchoPrompt: Instructing the Model to Rephrase Queries for Improved In-context Learning
Sep 16, 2023



Large language models primarily rely on incontext learning to execute tasks. We introduce EchoPrompt, a simple yet effective approach to prompt the model to rephrase its queries before answering them. EchoPrompt is inspired by self-questioning, a cognitive strategy humans use to vocalize queries before providing answers, thereby reducing misconceptions. Experimental results demonstrate that EchoPrompt leads to substantial improvements in both zero-shot and few-shot in-context learning with standard and chain-of-thought prompting on four families of causal language models. These improvements are observed across various numerical reasoning (GSM8K, SVAMP, MultiArith, SingleOp), reading comprehension (DROP, SQuAD), and logical reasoning (Shuffled Objects, Date Understanding, Coin Flipping) tasks. On average, EchoPrompt improves the Zero-shot-CoT performance of code-davinci-002 by 5% in numerical tasks and 13% in reading comprehension tasks. We investigate the effectiveness of EchoPrompt through ablation studies, which reveal the significance of both original and rephrased queries for EchoPrompt's efficacy. Our empirical results show that EchoPrompt is an effective technique that can easily augment in-context learning for better performance.
Selective Perception: Optimizing State Descriptions with Reinforcement Learning for Language Model Actors
Jul 21, 2023


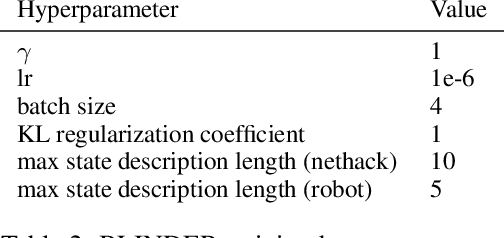
Large language models (LLMs) are being applied as actors for sequential decision making tasks in domains such as robotics and games, utilizing their general world knowledge and planning abilities. However, previous work does little to explore what environment state information is provided to LLM actors via language. Exhaustively describing high-dimensional states can impair performance and raise inference costs for LLM actors. Previous LLM actors avoid the issue by relying on hand-engineered, task-specific protocols to determine which features to communicate about a state and which to leave out. In this work, we propose Brief Language INputs for DEcision-making Responses (BLINDER), a method for automatically selecting concise state descriptions by learning a value function for task-conditioned state descriptions. We evaluate BLINDER on the challenging video game NetHack and a robotic manipulation task. Our method improves task success rate, reduces input size and compute costs, and generalizes between LLM actors.
A Theoretically Grounded Benchmark for Evaluating Machine Commonsense
Mar 23, 2022

Programming machines with commonsense reasoning (CSR) abilities is a longstanding challenge in the Artificial Intelligence community. Current CSR benchmarks use multiple-choice (and in relatively fewer cases, generative) question-answering instances to evaluate machine commonsense. Recent progress in transformer-based language representation models suggest that considerable progress has been made on existing benchmarks. However, although tens of CSR benchmarks currently exist, and are growing, it is not evident that the full suite of commonsense capabilities have been systematically evaluated. Furthermore, there are doubts about whether language models are 'fitting' to a benchmark dataset's training partition by picking up on subtle, but normatively irrelevant (at least for CSR), statistical features to achieve good performance on the testing partition. To address these challenges, we propose a benchmark called Theoretically-Grounded Commonsense Reasoning (TG-CSR) that is also based on discriminative question answering, but with questions designed to evaluate diverse aspects of commonsense, such as space, time, and world states. TG-CSR is based on a subset of commonsense categories first proposed as a viable theory of commonsense by Gordon and Hobbs. The benchmark is also designed to be few-shot (and in the future, zero-shot), with only a few training and validation examples provided. This report discusses the structure and construction of the benchmark. Preliminary results suggest that the benchmark is challenging even for advanced language representation models designed for discriminative CSR question answering tasks. Benchmark access and leaderboard: https://codalab.lisn.upsaclay.fr/competitions/3080 Benchmark website: https://usc-isi-i2.github.io/TGCSR/
Impact of Pretraining Term Frequencies on Few-Shot Reasoning
Feb 15, 2022



Pretrained Language Models (LMs) have demonstrated ability to perform numerical reasoning by extrapolating from a few examples in few-shot settings. However, the extent to which this extrapolation relies on robust reasoning is unclear. In this paper, we investigate how well these models reason with terms that are less frequent in the pretraining data. In particular, we examine the correlations between the model performance on test instances and the frequency of terms from those instances in the pretraining data. We measure the strength of this correlation for a number of GPT-based language models (pretrained on the Pile dataset) on various numerical deduction tasks (e.g., arithmetic and unit conversion). Our results consistently demonstrate that models are more accurate on instances whose terms are more prevalent, in some cases above $70\%$ (absolute) more accurate on the top 10\% frequent terms in comparison to the bottom 10\%. Overall, although LMs exhibit strong performance at few-shot numerical reasoning tasks, our results raise the question of how much models actually generalize beyond pretraining data, and we encourage researchers to take the pretraining data into account when interpreting evaluation results.
AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
Nov 07, 2020
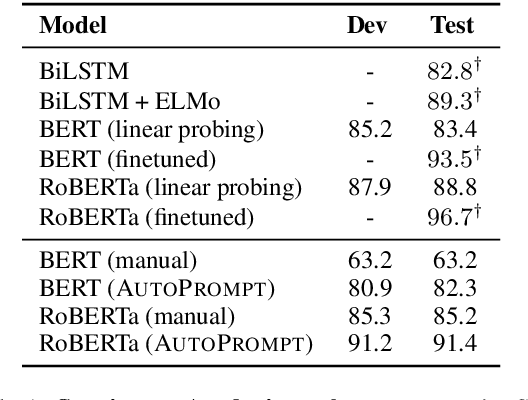
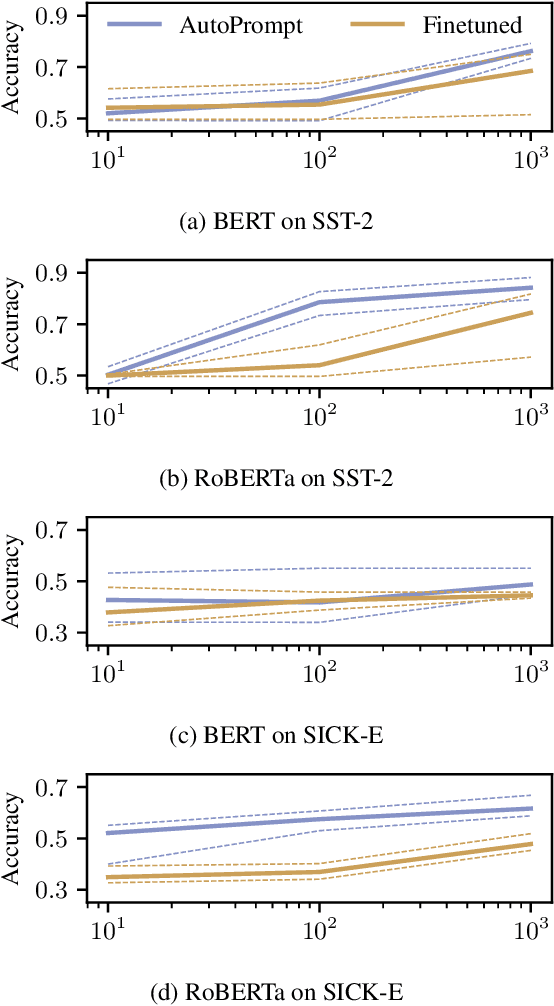

The remarkable success of pretrained language models has motivated the study of what kinds of knowledge these models learn during pretraining. Reformulating tasks as fill-in-the-blanks problems (e.g., cloze tests) is a natural approach for gauging such knowledge, however, its usage is limited by the manual effort and guesswork required to write suitable prompts. To address this, we develop AutoPrompt, an automated method to create prompts for a diverse set of tasks, based on a gradient-guided search. Using AutoPrompt, we show that masked language models (MLMs) have an inherent capability to perform sentiment analysis and natural language inference without additional parameters or finetuning, sometimes achieving performance on par with recent state-of-the-art supervised models. We also show that our prompts elicit more accurate factual knowledge from MLMs than the manually created prompts on the LAMA benchmark, and that MLMs can be used as relation extractors more effectively than supervised relation extraction models. These results demonstrate that automatically generated prompts are a viable parameter-free alternative to existing probing methods, and as pretrained LMs become more sophisticated and capable, potentially a replacement for finetuning.