 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurtleBench: A Visual Programming Benchmark in Turtle Geometry
Oct 31, 2024



Humans have the ability to reason about geometric patterns in images and scenes from a young age. However, developing large multimodal models (LMMs) capable of similar reasoning remains a challenge, highlighting the need for robust evaluation methods to assess these capabilities. We introduce TurtleBench, a benchmark designed to evaluate LMMs' capacity to interpret geometric patterns -- given visual examples, textual instructions, or both -- and generate precise code outputs. Inspired by turtle geometry, a notion used to teach children foundational coding and geometric concepts, TurtleBench features tasks with patterned shapes that have underlying algorithmic logic. Our evaluation reveals that leading LMMs struggle significantly with these tasks, with GPT-4o achieving only 19\% accuracy on the simplest tasks and few-shot prompting only marginally improves their performance ($<2\%$). TurtleBench highlights the gap between human and AI performance in intuitive and visual geometrical understanding, setting the stage for future research in this area. TurtleBench stands as one of the few benchmarks to evaluate the integration of visual understanding and code generation capabilities in LMMs, setting the stage for future research. Code and Dataset for this paper is provided here: https://github.com/sinaris76/TurtleBench
Reconciling Different Theories of Learning with an Agent-based Model of Procedural Learning
Aug 23, 2024Computational models of human learning can play a significant role in enhancing our knowledge about nuances in theoretical and qualitative learning theories and frameworks. There are many existing frameworks in educational settings that have shown to be verified using empirical studies, but at times we find these theories make conflicting claims or recommendations for instruction. In this study, we propose a new computational model of human learning, Procedural ABICAP, that reconciles the ICAP, Knowledge-Learning-Instruction (KLI), and cognitive load theory (CLT) frameworks for learning procedural knowledge. ICAP assumes that constructive learning generally yields better learning outcomes, while theories such as KLI and CLT claim that this is not always true. We suppose that one reason for this may be that ICAP is primarily used for conceptual learning and is underspecified as a framework for thinking about procedural learning. We show how our computational model, both by design and through simulations, can be used to reconcile different results in the literature. More generally, we position our computational model as an executable theory of learning that can be used to simulate various educational settings.
Equity and Artificial Intelligence in Education: Will "AIEd" Amplify or Alleviate Inequities in Education?
Apr 27, 2021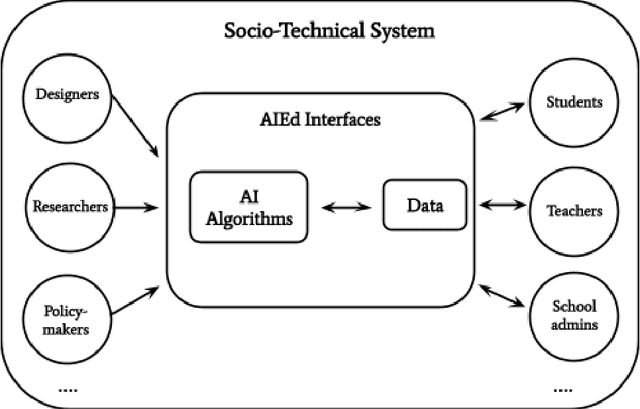
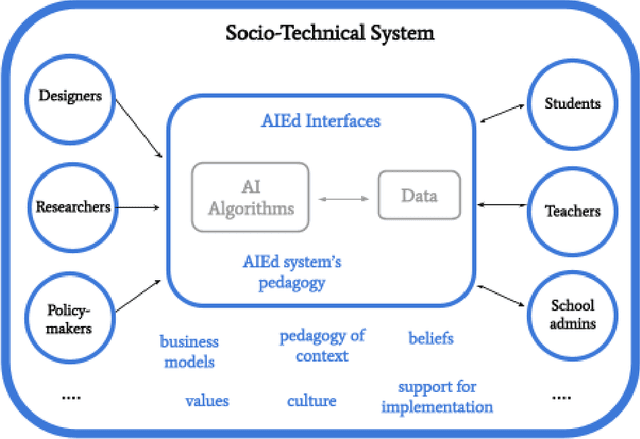
The development of educational AI (AIEd) systems has often been motivated by their potential to promote educational equity and reduce achievement gaps across different groups of learners -- for example, by scaling up the benefits of one-on-one human tutoring to a broader audience, or by filling gaps in existing educational services. Given these noble intentions, why might AIEd systems have inequitable impacts in practice? In this chapter, we discuss four lenses that can be used to examine how and why AIEd systems risk amplifying existing inequities. Building from these lenses, we then outline possible paths towards more equitable futures for AIEd, while highlighting debates surrounding each proposal. In doing so, we hope to provoke new conversations around the design of equitable AIEd, and to push ongoing conversations in the field forward.
A PAC RL Algorithm for Episodic POMDPs
Jun 01, 2016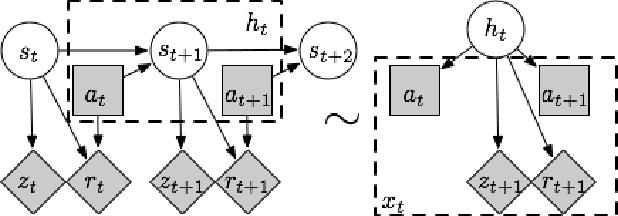
Many interesting real world domains involve reinforcement learning (RL) in partially observable environments. Efficient learning in such domains is important, but existing sample complexity bounds for partially observable RL are at least exponential in the episode length. We give, to our knowledge, the first partially observable RL algorithm with a polynomial bound on the number of episodes on which the algorithm may not achieve near-optimal performance. Our algorithm is suitable for an important class of episodic POMDPs. Our approach builds on recent advances in method of moments for latent variable model estimation.