 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERRY: Policy Evaluation with Confidence Intervals using Auxiliary Data
Jul 26, 2025Off-policy evaluation (OPE) methods aim to estimate the value of a new reinforcement learning (RL) policy prior to deployment. Recent advances have shown that leveraging auxiliary datasets, such as those synthesized by generative models, can improve the accuracy of these value estimates. Unfortunately, such auxiliary datasets may also be biased, and existing methods for using data augmentation for OPE in RL lack principled uncertainty quantification. In high stakes settings like healthcare, reliable uncertainty estimates are important for comparing policy value estimates. In this work, we propose two approaches to construct valid confidence intervals for OPE when using data augmentation. The first provides a confidence interval over the policy performance conditioned on a particular initial state $V^{\pi}(s_0)$-- such intervals are particularly important for human-centered applications. To do so we introduce a new conformal prediction method for high dimensional state MDPs. Second, we consider the more common task of estimating the average policy performance over many initial states; to do so we draw on ideas from doubly robust estimation and prediction powered inference. Across simulators spanning robotics, healthcare and inventory management, and a real healthcare dataset from MIMIC-IV, we find that our methods can use augmented data and still consistently produce intervals that cover the ground truth values, unlike previously proposed methods.
Predicting Long Term Sequential Policy Value Using Softer Surrogates
Dec 30, 2024Performing policy evaluation in education, healthcare and online commerce can be challenging, because it can require waiting substantial amounts of time to observe outcomes over the desired horizon of interest. While offline evaluation methods can be used to estimate the performance of a new decision policy from historical data in some cases, such methods struggle when the new policy involves novel actions or is being run in a new decision process with potentially different dynamics. Here we consider how to estimate the full-horizon value of a new decision policy using only short-horizon data from the new policy, and historical full-horizon data from a different behavior policy. We introduce two new estimators for this setting, including a doubly robust estimator, and provide formal analysis of their properties. Our empirical results on two realistic simulators, of HIV treatment and sepsis treatment, show that our methods can often provide informative estimates of a new decision policy ten times faster than waiting for the full horizon, highlighting that it may be possible to quickly identify if a new decision policy, involving new actions, is better or worse than existing past policies.
Predicting Long-Term Student Outcomes from Short-Term EdTech Log Data
Dec 20, 2024



Educational stakeholders are often particularly interested in sparse, delayed student outcomes, like end-of-year statewide exams. The rare occurrence of such assessments makes it harder to identify students likely to fail such assessments, as well as making it slow for researchers and educators to be able to assess the effectiveness of particular educational tools. Prior work has primarily focused on using logs from students full usage (e.g. year-long) of an educational product to predict outcomes, or considered predictive accuracy using a few minutes to predict outcomes after a short (e.g. 1 hour) session. In contrast, we investigate machine learning predictors using students' logs during their first few hours of usage can provide useful predictive insight into those students' end-of-school year external assessment. We do this on three diverse datasets: from students in Uganda using a literacy game product, and from students in the US using two mathematics intelligent tutoring systems. We consider various measures of the accuracy of the resulting predictors, including its ability to identify students at different parts along the assessment performance distribution. Our findings suggest that short-term log usage data, from 2-5 hours, can be used to provide valuable signal about students' long-term external performance.
Psychometric Alignment: Capturing Human Knowledge Distributions via Language Models
Jul 22, 2024



Language models (LMs) are increasingly used to simulate human-like responses in scenarios where accurately mimicking a population's behavior can guide decision-making, such as in developing educational materials and designing public policies. The objective of these simulations is for LMs to capture the variations in human responses, rather than merely providing the expected correct answers. Prior work has shown that LMs often generate unrealistically accurate responses, but there are no established metrics to quantify how closely the knowledge distribution of LMs aligns with that of humans. To address this, we introduce "psychometric alignment," a metric that measures the extent to which LMs reflect human knowledge distribution. Assessing this alignment involves collecting responses from both LMs and humans to the same set of test items and using Item Response Theory to analyze the differences in item functioning between the groups. We demonstrate that our metric can capture important variations in populations that traditional metrics, like differences in accuracy, fail to capture. We apply this metric to assess existing LMs for their alignment with human knowledge distributions across three real-world domains. We find significant misalignment between LMs and human populations, though using persona-based prompts can improve alignment. Interestingly, smaller LMs tend to achieve greater psychometric alignment than larger LMs. Further, training LMs on human response data from the target distribution enhances their psychometric alignment on unseen test items, but the effectiveness of such training varies across domains.
Short-Long Policy Evaluation with Novel Actions
Jul 04, 2024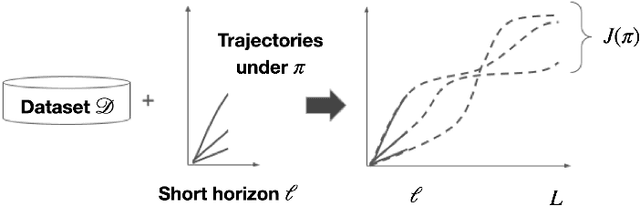

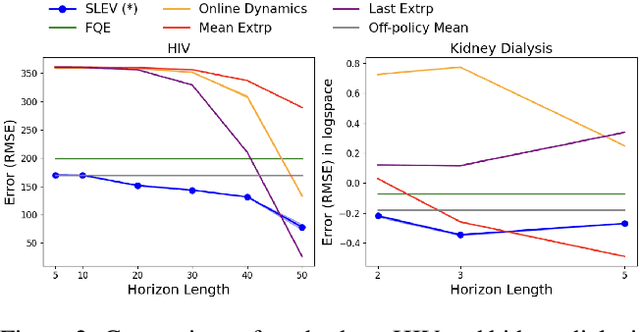

From incorporating LLMs in education, to identifying new drugs and improving ways to charge batteries, innovators constantly try new strategies in search of better long-term outcomes for students, patients and consumers. One major bottleneck in this innovation cycle is the amount of time it takes to observe the downstream effects of a decision policy that incorporates new interventions. The key question is whether we can quickly evaluate long-term outcomes of a new decision policy without making long-term observations. Organizations often have access to prior data about past decision policies and their outcomes, evaluated over the full horizon of interest. Motivated by this, we introduce a new setting for short-long policy evaluation for sequential decision making tasks. Our proposed methods significantly outperform prior results on simulators of HIV treatment, kidney dialysis and battery charging. We also demonstrate that our methods can be useful for applications in AI safety by quickly identifying when a new decision policy is likely to have substantially lower performance than past policies.
Roleplay-doh: Enabling Domain-Experts to Create LLM-simulated Patients via Eliciting and Adhering to Principles
Jul 01, 2024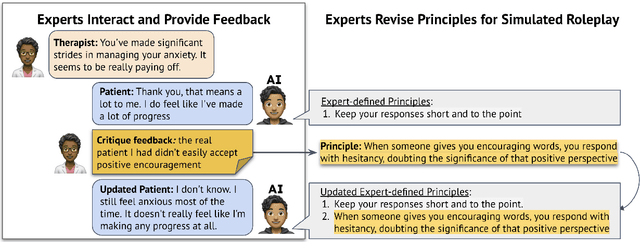
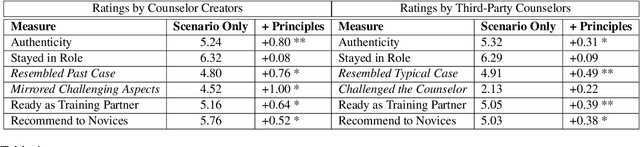
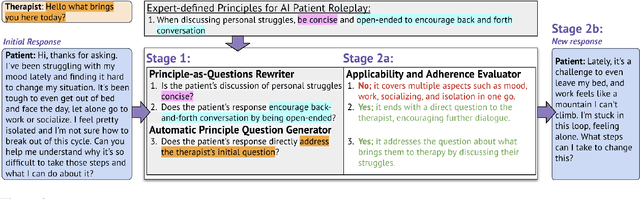
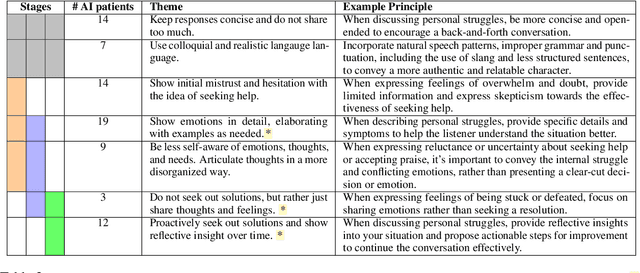
Recent works leverage LLMs to roleplay realistic social scenarios, aiding novices in practicing their social skills. However, simulating sensitive interactions, such as in mental health, is challenging. Privacy concerns restrict data access, and collecting expert feedback, although vital, is laborious. To address this, we develop Roleplay-doh, a novel human-LLM collaboration pipeline that elicits qualitative feedback from a domain-expert, which is transformed into a set of principles, or natural language rules, that govern an LLM-prompted roleplay. We apply this pipeline to enable senior mental health supporters to create customized AI patients for simulated practice partners for novice counselors. After uncovering issues in GPT-4 simulations not adhering to expert-defined principles, we also introduce a novel principle-adherence prompting pipeline which shows 30\% improvements in response quality and principle following for the downstream task. Via a user study with 25 counseling experts, we demonstrate that the pipeline makes it easy and effective to create AI patients that more faithfully resemble real patients, as judged by creators and third-party counselors.
Data-driven Error Estimation: Upper Bounding Multiple Errors with No Technical Debt
May 07, 2024We formulate the problem of constructing multiple simultaneously valid confidence intervals (CIs) as estimating a high probability upper bound on the maximum error for a class/set of estimate-estimand-error tuples, and refer to this as the error estimation problem. For a single such tuple, data-driven confidence intervals can often be used to bound the error in our estimate. However, for a class of estimate-estimand-error tuples, nontrivial high probability upper bounds on the maximum error often require class complexity as input -- limiting the practicality of such methods and often resulting in loose bounds. Rather than deriving theoretical class complexity-based bounds, we propose a completely data-driven approach to estimate an upper bound on the maximum error. The simple and general nature of our solution to this fundamental challenge lends itself to several applications including: multiple CI construction, multiple hypothesis testing, estimating excess risk bounds (a fundamental measure of uncertainty in machine learning) for any training/fine-tuning algorithm, and enabling the development of a contextual bandit pipeline that can leverage any reward model estimation procedure as input (without additional mathematical analysis).
Evaluating and Optimizing Educational Content with Large Language Model Judgments
Mar 05, 2024



Creating effective educational materials generally requires expensive and time-consuming studies of student learning outcomes. To overcome this barrier, one idea is to build computational models of student learning and use them to optimize instructional materials. However, it is difficult to model the cognitive processes of learning dynamics. We propose an alternative approach that uses Language Models (LMs) as educational experts to assess the impact of various instructions on learning outcomes. Specifically, we use GPT-3.5 to evaluate the overall effect of instructional materials on different student groups and find that it can replicate well-established educational findings such as the Expertise Reversal Effect and the Variability Effect. This demonstrates the potential of LMs as reliable evaluators of educational content. Building on this insight, we introduce an instruction optimization approach in which one LM generates instructional materials using the judgments of another LM as a reward function. We apply this approach to create math word problem worksheets aimed at maximizing student learning gains. Human teachers' evaluations of these LM-generated worksheets show a significant alignment between the LM judgments and human teacher preferences. We conclude by discussing potential divergences between human and LM opinions and the resulting pitfalls of automating instructional design.
Experiment Planning with Function Approximation
Jan 10, 2024We study the problem of experiment planning with function approximation in contextual bandit problems. In settings where there is a significant overhead to deploying adaptive algorithms -- for example, when the execution of the data collection policies is required to be distributed, or a human in the loop is needed to implement these policies -- producing in advance a set of policies for data collection is paramount. We study the setting where a large dataset of contexts but not rewards is available and may be used by the learner to design an effective data collection strategy. Although when rewards are linear this problem has been well studied, results are still missing for more complex reward models. In this work we propose two experiment planning strategies compatible with function approximation. The first is an eluder planning and sampling procedure that can recover optimality guarantees depending on the eluder dimension of the reward function class. For the second, we show that a uniform sampler achieves competitive optimality rates in the setting where the number of actions is small. We finalize our results introducing a statistical gap fleshing out the fundamental differences between planning and adaptive learning and provide results for planning with model selection.
Adaptive Instrument Design for Indirect Experiments
Dec 05, 2023



Indirect experiments provide a valuable framework for estimating treatment effects in situations where conducting randomized control trials (RCTs) is impractical or unethical. Unlike RCTs, indirect experiments estimate treatment effects by leveraging (conditional) instrumental variables, enabling estimation through encouragement and recommendation rather than strict treatment assignment. However, the sample efficiency of such estimators depends not only on the inherent variability in outcomes but also on the varying compliance levels of users with the instrumental variables and the choice of estimator being used, especially when dealing with numerous instrumental variables. While adaptive experiment design has a rich literature for direct experiments, in this paper we take the initial steps towards enhancing sample efficiency for indirect experiments by adaptively designing a data collection policy over instrumental variables. Our main contribution is a practical computational procedure that utilizes influence functions to search for an optimal data collection policy, minimizing the mean-squared error of the desired (non-linear) estimator. Through experiments conducted in various domains inspired by real-world applications, we showcase how our method can significantly improve the sample efficiency of indirect experiments.