 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Dense Retrievers with LLM Utility via DistillationAligning Dense Retrievers with LLM Utility via Distillation
Apr 24, 2026Dense vector retrieval is the practical backbone of Retrieval- Augmented Generation (RAG), but similarity search can suffer from precision limitations. Conversely, utility-based approaches leveraging LLM re-ranking often achieve superior performance but are computationally prohibitive and prone to noise inherent in perplexity estimation. We propose Utility-Aligned Embeddings (UAE), a framework designed to merge these advantages into a practical, high-performance retrieval method. We formulate retrieval as a distribution matching problem, training a bi-encoder to imitate a utility distribution derived from perplexity reduction using a Utility-Modulated InfoNCE objective. This approach injects graded utility signals directly into the embedding space without requiring test-time LLM inference. On the QASPER benchmark, UAE improves retrieval Recall@1 by 30.59%, MAP by 30.16% and Token F1 by 17.3% over the strong semantic baseline BGE-Base. Crucially, UAE is over 180x faster than the efficient LLM re-ranking methods preserving competitive performance, demonstrating that aligning retrieval with generative utility yields reliable contexts at scale.
MOSS-TTSD: Text to Spoken Dialogue Generation
Mar 20, 2026Spoken dialogue generation is crucial for applications like podcasts, dynamic commentary, and entertainment content, but poses significant challenges compared to single-utterance text-to-speech (TTS). Key requirements include accurate turn-taking, cross-turn acoustic consistency, and long-form stability, which current models often fail to address due to a lack of dialogue context modeling. To bridge this gap, we present MOSS-TTSD, a spoken dialogue synthesis model designed for expressive, multi-party conversational speech across multiple languages. With enhanced long-context modeling, MOSS-TTSD generates long-form spoken conversations from dialogue scripts with explicit speaker tags, supporting up to 60 minutes of single-pass synthesis, multi-party dialogue with up to 5 speakers, and zero-shot voice cloning from a short reference audio clip. The model supports various mainstream languages, including English and Chinese, and is adapted to several long-form scenarios. Additionally, to address limitations of existing evaluation methods, we propose TTSD-eval, an objective evaluation framework based on forced alignment that measures speaker attribution accuracy and speaker similarity without relying on speaker diarization tools. Both objective and subjective evaluation results show that MOSS-TTSD surpasses strong open-source and proprietary baselines in dialogue synthesis.
MOSS-TTS Technical Report
Mar 18, 2026This technical report presents MOSS-TTS, a speech generation foundation model built on a scalable recipe: discrete audio tokens, autoregressive modeling, and large-scale pretraining. Built on MOSS-Audio-Tokenizer, a causal Transformer tokenizer that compresses 24 kHz audio to 12.5 fps with variable-bitrate RVQ and unified semantic-acoustic representations, we release two complementary generators: MOSS-TTS, which emphasizes structural simplicity, scalability, and long-context/control-oriented deployment, and MOSS-TTS-Local-Transformer, which introduces a frame-local autoregressive module for higher modeling efficiency, stronger speaker preservation, and a shorter time to first audio. Across multilingual and open-domain settings, MOSS-TTS supports zero-shot voice cloning, token-level duration control, phoneme-/pinyin-level pronunciation control, smooth code-switching, and stable long-form generation. This report summarizes the design, training recipe, and empirical characteristics of the released models.
MMKU-Bench: A Multimodal Update Benchmark for Diverse Visual Knowledge
Mar 16, 2026As real-world knowledge continues to evolve, the parametric knowledge acquired by multimodal models during pretraining becomes increasingly difficult to remain consistent with real-world knowledge. Existing research on multimodal knowledge updating focuses only on learning previously unknown knowledge, while overlooking the need to update knowledge that the model has already mastered but that later changes; moreover, evaluation is limited to the same modality, lacking a systematic analysis of cross-modal consistency. To address these issues, this paper proposes MMKU-Bench, a comprehensive evaluation benchmark for multimodal knowledge updating, which contains over 25k knowledge instances and more than 49k images, covering two scenarios, updated knowledge and unknown knowledge, thereby enabling comparative analysis of learning across different knowledge types. On this benchmark, we evaluate a variety of representative approaches, including supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and knowledge editing (KE). Experimental results show that SFT and RLHF are prone to catastrophic forgetting, while KE better preserve general capabilities but exhibit clear limitations in continual updating. Overall, MMKU-Bench provides a reliable and comprehensive evaluation benchmark for multimodal knowledge updating, advancing progress in this field.
RGAlign-Rec: Ranking-Guided Alignment for Latent Query Reasoning in Recommendation Systems
Feb 13, 2026Proactive intent prediction is a critical capability in modern e-commerce chatbots, enabling "zero-query" recommendations by anticipating user needs from behavioral and contextual signals. However, existing industrial systems face two fundamental challenges: (1) the semantic gap between discrete user features and the semantic intents within the chatbot's Knowledge Base, and (2) the objective misalignment between general-purpose LLM outputs and task-specific ranking utilities. To address these issues, we propose RGAlign-Rec, a closed-loop alignment framework that integrates an LLM-based semantic reasoner with a Query-Enhanced (QE) ranking model. We also introduce Ranking-Guided Alignment (RGA), a multi-stage training paradigm that utilizes downstream ranking signals as feedback to refine the LLM's latent reasoning. Extensive experiments on a large-scale industrial dataset from Shopee demonstrate that RGAlign-Rec achieves a 0.12% gain in GAUC, leading to a significant 3.52% relative reduction in error rate, and a 0.56% improvement in Recall@3. Online A/B testing further validates the cumulative effectiveness of our framework: the Query-Enhanced model (QE-Rec) initially yields a 0.98% improvement in CTR, while the subsequent Ranking-Guided Alignment stage contributes an additional 0.13% gain. These results indicate that ranking-aware alignment effectively synchronizes semantic reasoning with ranking objectives, significantly enhancing both prediction accuracy and service quality in real-world proactive recommendation systems.
MOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
Driving-RAG: Driving Scenarios Embedding, Search, and RAG Applications
Apr 06, 2025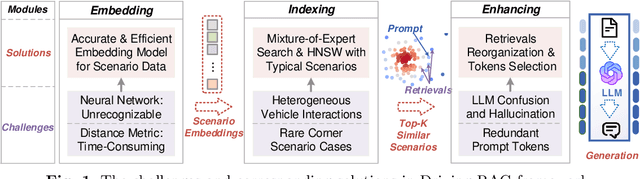
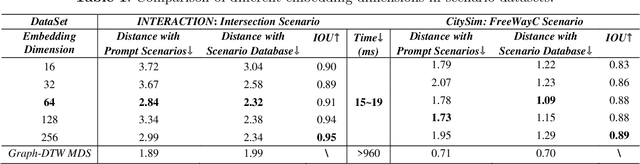
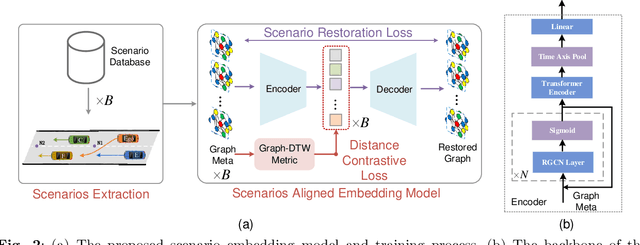
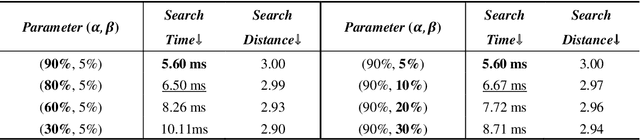
Driving scenario data play an increasingly vital role in the development of intelligent vehicles and autonomous driving. Accurate and efficient scenario data search is critical for both online vehicle decision-making and planning, and offline scenario generation and simulations, as it allows for leveraging the scenario experiences to improve the overall performance. Especially with the application of large language models (LLMs) and Retrieval-Augmented-Generation (RAG) systems in autonomous driving, urgent requirements are put forward. In this paper, we introduce the Driving-RAG framework to address the challenges of efficient scenario data embedding, search, and applications for RAG systems. Our embedding model aligns fundamental scenario information and scenario distance metrics in the vector space. The typical scenario sampling method combined with hierarchical navigable small world can perform efficient scenario vector search to achieve high efficiency without sacrificing accuracy. In addition, the reorganization mechanism by graph knowledge enhances the relevance to the prompt scenarios and augment LLM generation. We demonstrate the effectiveness of the proposed framework on typical trajectory planning task for complex interactive scenarios such as ramps and intersections, showcasing its advantages for RAG applications.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents
Nov 10, 2024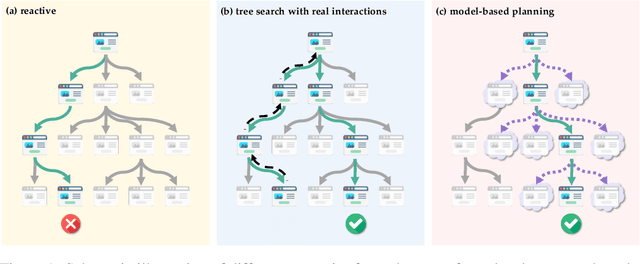

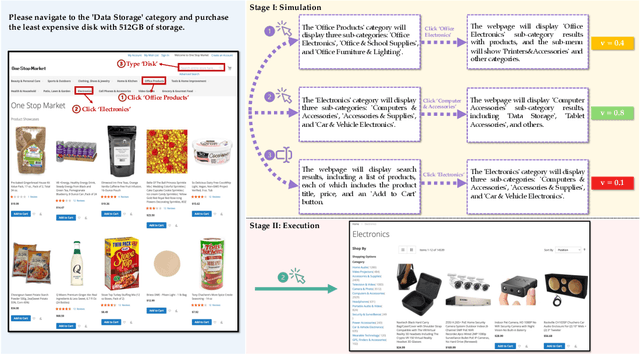

Language agents have demonstrated promising capabilities in automating web-based tasks, though their current reactive approaches still underperform largely compared to humans. While incorporating advanced planning algorithms, particularly tree search methods, could enhance these agents' performance, implementing tree search directly on live websites poses significant safety risks and practical constraints due to irreversible actions such as confirming a purchase. In this paper, we introduce a novel paradigm that augments language agents with model-based planning, pioneering the innovative use of large language models (LLMs) as world models in complex web environments. Our method, WebDreamer, builds on the key insight that LLMs inherently encode comprehensive knowledge about website structures and functionalities. Specifically, WebDreamer uses LLMs to simulate outcomes for each candidate action (e.g., "what would happen if I click this button?") using natural language descriptions, and then evaluates these imagined outcomes to determine the optimal action at each step. Empirical results on two representative web agent benchmarks with online interaction -- VisualWebArena and Mind2Web-live -- demonstrate that WebDreamer achieves substantial improvements over reactive baselines. By establishing the viability of LLMs as world models in web environments, this work lays the groundwork for a paradigm shift in automated web interaction. More broadly, our findings open exciting new avenues for future research into 1) optimizing LLMs specifically for world modeling in complex, dynamic environments, and 2) model-based speculative planning for language agents.
AMSnet-KG: A Netlist Dataset for LLM-based AMS Circuit Auto-Design Using Knowledge Graph RAG
Nov 07, 2024



High-performance analog and mixed-signal (AMS) circuits are mainly full-custom designed, which is time-consuming and labor-intensive. A significant portion of the effort is experience-driven, which makes the automation of AMS circuit design a formidable challenge. Large language models (LLMs) have emerged as powerful tools for Electronic Design Automation (EDA) applications, fostering advancements in the automatic design process for large-scale AMS circuits. However, the absence of high-quality datasets has led to issues such as model hallucination, which undermines the robustness of automatically generated circuit designs. To address this issue, this paper introduces AMSnet-KG, a dataset encompassing various AMS circuit schematics and netlists. We construct a knowledge graph with annotations on detailed functional and performance characteristics. Facilitated by AMSnet-KG, we propose an automated AMS circuit generation framework that utilizes the comprehensive knowledge embedded in LLMs. We first formulate a design strategy (e.g., circuit architecture using a number of circuit components) based on required specifications. Next, matched circuit components are retrieved and assembled into a complete topology, and transistor sizing is obtained through Bayesian optimization. Simulation results of the netlist are fed back to the LLM for further topology refinement, ensuring the circuit design specifications are met. We perform case studies of operational amplifier and comparator design to verify the automatic design flow from specifications to netlists with minimal human effort. The dataset used in this paper will be open-sourced upon publishing of this paper.