 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Feb 26, 2024



We introduce AnyGPT, an any-to-any multimodal language model that utilizes discrete representations for the unified processing of various modalities, including speech, text, images, and music. AnyGPT can be trained stably without any alterations to the current large language model (LLM) architecture or training paradigms. Instead, it relies exclusively on data-level preprocessing, facilitating the seamless integration of new modalities into LLMs, akin to the incorporation of new languages. We build a multimodal text-centric dataset for multimodal alignment pre-training. Utilizing generative models, we synthesize the first large-scale any-to-any multimodal instruction dataset. It consists of 108k samples of multi-turn conversations that intricately interweave various modalities, thus equipping the model to handle arbitrary combinations of multimodal inputs and outputs. Experimental results demonstrate that AnyGPT is capable of facilitating any-to-any multimodal conversation while achieving performance comparable to specialized models across all modalities, proving that discrete representations can effectively and conveniently unify multiple modalities within a language model. Demos are shown in https://junzhan2000.github.io/AnyGPT.github.io/
Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication
Dec 04, 2023



Large Language Models (LLMs) have recently made significant strides in complex reasoning tasks through the Chain-of-Thought technique. Despite this progress, their reasoning is often constrained by their intrinsic understanding, lacking external insights. To address this, we propose Exchange-of-Thought (EoT), a novel framework that enables cross-model communication during problem-solving. Drawing inspiration from network topology, EoT integrates four unique communication paradigms: Memory, Report, Relay, and Debate. This paper delves into the communication dynamics and volume associated with each paradigm. To counterbalance the risks of incorrect reasoning chains, we implement a robust confidence evaluation mechanism within these communications. Our experiments across diverse complex reasoning tasks demonstrate that EoT significantly surpasses established baselines, underscoring the value of external insights in enhancing LLM performance. Furthermore, we show that EoT achieves these superior results in a cost-effective manner, marking a promising advancement for efficient and collaborative AI problem-solving.
Character-LLM: A Trainable Agent for Role-Playing
Oct 16, 2023Large language models (LLMs) can be used to serve as agents to simulate human behaviors, given the powerful ability to understand human instructions and provide high-quality generated texts. Such ability stimulates us to wonder whether LLMs can simulate a person in a higher form than simple human behaviors. Therefore, we aim to train an agent with the profile, experience, and emotional states of a specific person instead of using limited prompts to instruct ChatGPT API. In this work, we introduce Character-LLM that teach LLMs to act as specific people such as Beethoven, Queen Cleopatra, Julius Caesar, etc. Our method focuses on editing profiles as experiences of a certain character and training models to be personal simulacra with these experiences. To assess the effectiveness of our approach, we build a test playground that interviews trained agents and evaluates whether the agents \textit{memorize} their characters and experiences. Experimental results show interesting observations that help build future simulacra of humankind.
Dialogue Meaning Representation for Task-Oriented Dialogue Systems
Apr 23, 2022

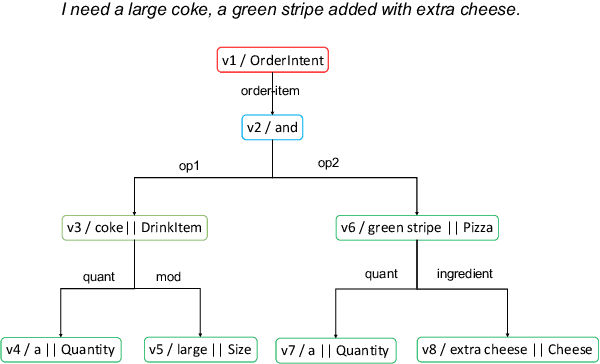

Dialogue meaning representation formulates natural language utterance semantics in their conversational context in an explicit and machine-readable form. Previous work typically follows the intent-slot framework, which is easy for annotation yet limited on scalability for complex linguistic expressions. A line of works alleviates the representation issue by introducing hierarchical structures but challenging to express complex compositional semantics, such as negation and coreference. We propose Dialogue Meaning Representation (DMR), a flexible and easily extendable representation for task-oriented dialogue. Our representation contains a set of nodes and edges with inheritance hierarchy to represent rich semantics for compositional semantics and task-specific concepts. We annotated DMR-FastFood, a multi-turn dialogue dataset with more than 70k utterances, with DMR. We propose two evaluation tasks to evaluate different machine learning based dialogue models, and further propose a novel coreference resolution model GNNCoref for the graph-based coreference resolution task. Experiments show that DMR can be parsed well with pretrained Seq2Seq model, and GNNCoref outperforms the baseline models by a large margin.
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
Sep 14, 2021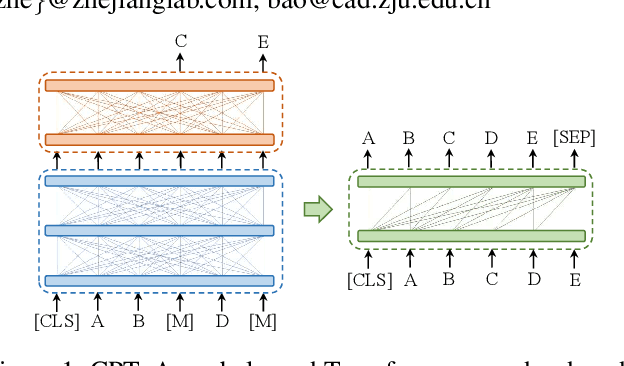
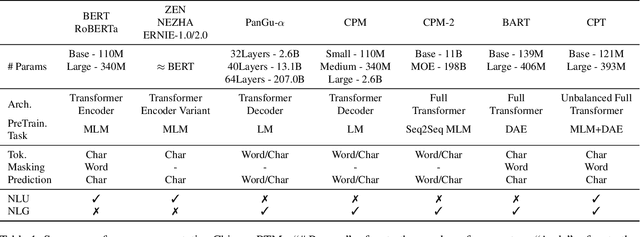
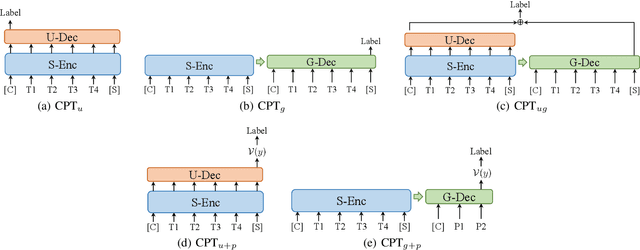
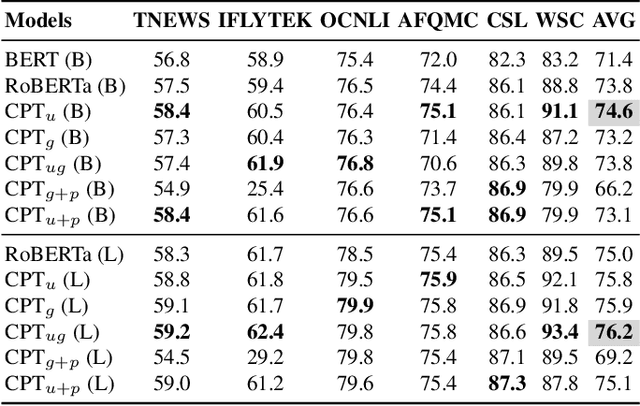
In this paper, we take the advantage of previous pre-trained models (PTMs) and propose a novel Chinese Pre-trained Unbalanced Transformer (CPT). Different from previous Chinese PTMs, CPT is designed for both natural language understanding (NLU) and natural language generation (NLG) tasks. CPT consists of three parts: a shared encoder, an understanding decoder, and a generation decoder. Two specific decoders with a shared encoder are pre-trained with masked language modeling (MLM) and denoising auto-encoding (DAE) tasks, respectively. With the partially shared architecture and multi-task pre-training, CPT can (1) learn specific knowledge of both NLU or NLG tasks with two decoders and (2) be fine-tuned flexibly that fully exploits the potential of the model. Moreover, the unbalanced Transformer saves the computational and storage cost, which makes CPT competitive and greatly accelerates the inference of text generation. Experimental results on a wide range of Chinese NLU and NLG tasks show the effectiveness of CPT.
A Unified Generative Framework for Aspect-Based Sentiment Analysis
Jun 08, 2021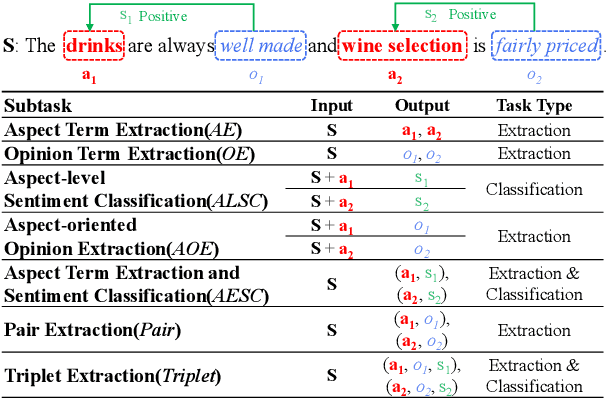

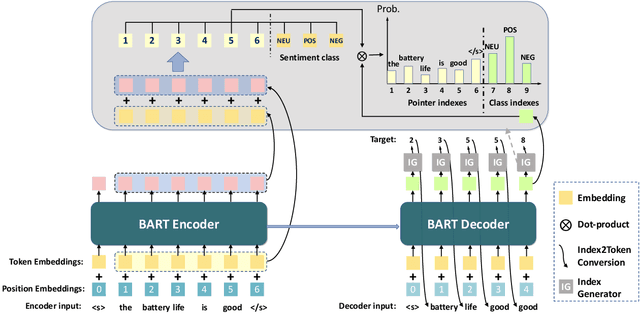
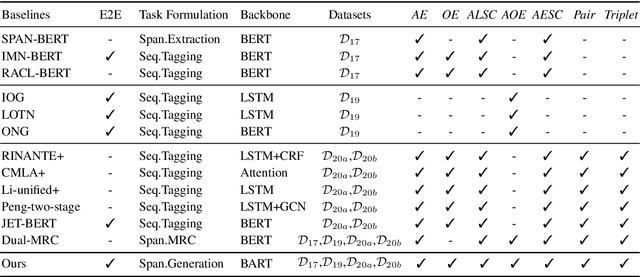
Aspect-based Sentiment Analysis (ABSA) aims to identify the aspect terms, their corresponding sentiment polarities, and the opinion terms. There exist seven subtasks in ABSA. Most studies only focus on the subsets of these subtasks, which leads to various complicated ABSA models while hard to solve these subtasks in a unified framework. In this paper, we redefine every subtask target as a sequence mixed by pointer indexes and sentiment class indexes, which converts all ABSA subtasks into a unified generative formulation. Based on the unified formulation, we exploit the pre-training sequence-to-sequence model BART to solve all ABSA subtasks in an end-to-end framework. Extensive experiments on four ABSA datasets for seven subtasks demonstrate that our framework achieves substantial performance gain and provides a real unified end-to-end solution for the whole ABSA subtasks, which could benefit multiple tasks.
A Unified Generative Framework for Various NER Subtasks
Jun 02, 2021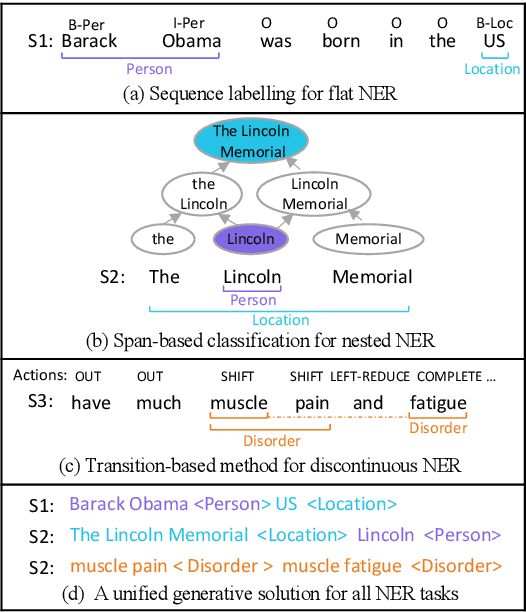
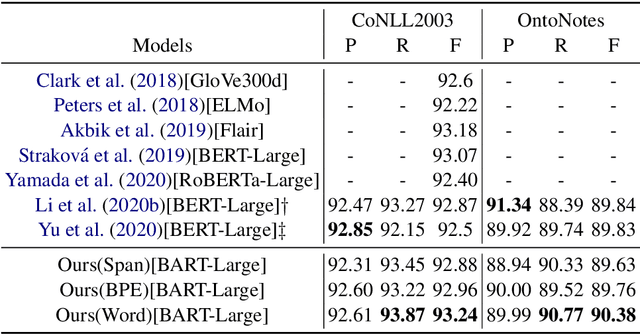

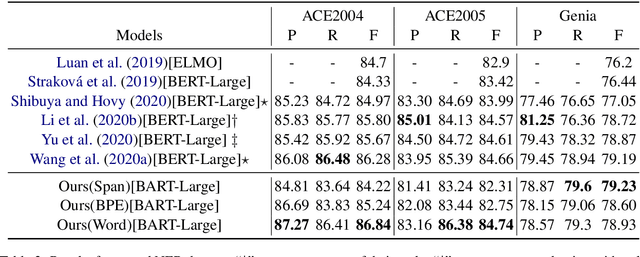
Named Entity Recognition (NER) is the task of identifying spans that represent entities in sentences. Whether the entity spans are nested or discontinuous, the NER task can be categorized into the flat NER, nested NER, and discontinuous NER subtasks. These subtasks have been mainly solved by the token-level sequence labelling or span-level classification. However, these solutions can hardly tackle the three kinds of NER subtasks concurrently. To that end, we propose to formulate the NER subtasks as an entity span sequence generation task, which can be solved by a unified sequence-to-sequence (Seq2Seq) framework. Based on our unified framework, we can leverage the pre-trained Seq2Seq model to solve all three kinds of NER subtasks without the special design of the tagging schema or ways to enumerate spans. We exploit three types of entity representations to linearize entities into a sequence. Our proposed framework is easy-to-implement and achieves state-of-the-art (SoTA) or near SoTA performance on eight English NER datasets, including two flat NER datasets, three nested NER datasets, and three discontinuous NER datasets.
EXPLAINABOARD: An Explainable Leaderboard for NLP
Apr 13, 2021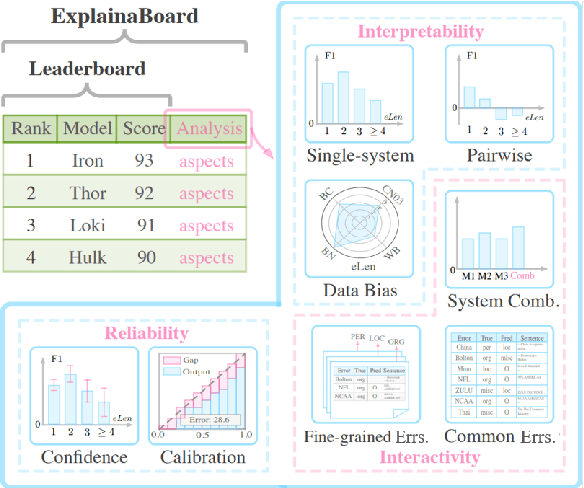
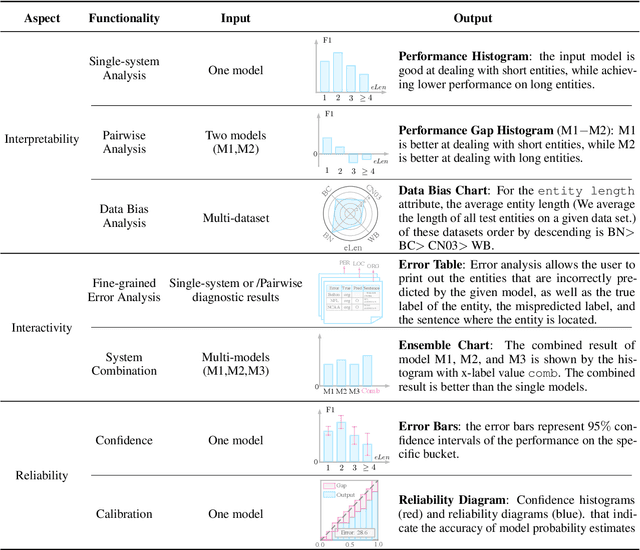
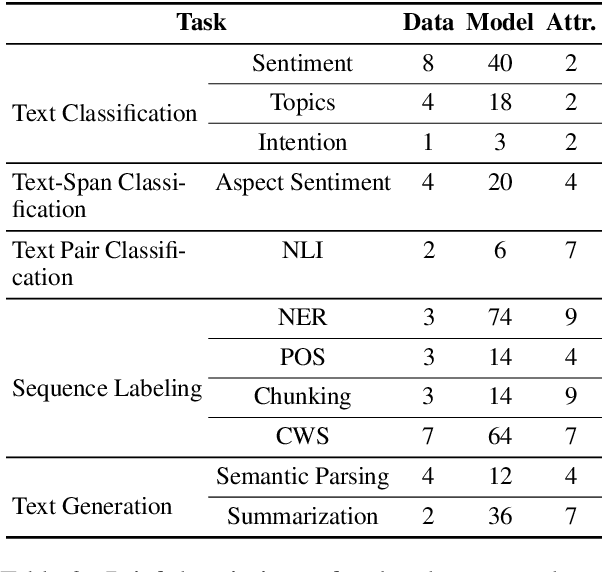
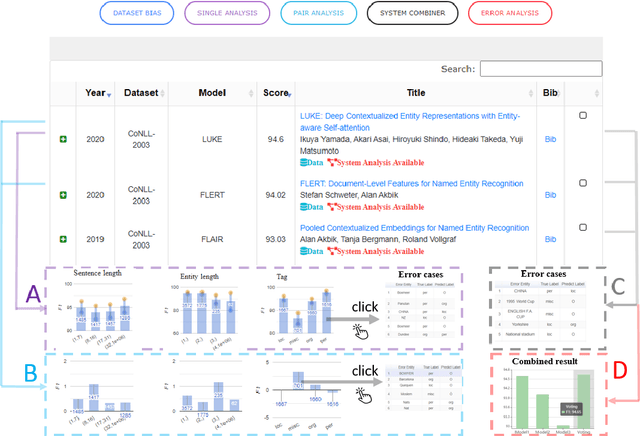
With the rapid development of NLP research, leaderboards have emerged as one tool to track the performance of various systems on various NLP tasks. They are effective in this goal to some extent, but generally present a rather simplistic one-dimensional view of the submitted systems, communicated only through holistic accuracy numbers. In this paper, we present a new conceptualization and implementation of NLP evaluation: the ExplainaBoard, which in addition to inheriting the functionality of the standard leaderboard, also allows researchers to (i) diagnose strengths and weaknesses of a single system (e.g. what is the best-performing system bad at?) (ii) interpret relationships between multiple systems. (e.g. where does system A outperform system B? What if we combine systems A, B, C?) and (iii) examine prediction results closely (e.g. what are common errors made by multiple systems or and in what contexts do particular errors occur?). ExplainaBoard has been deployed at \url{http://explainaboard.nlpedia.ai/}, and we have additionally released our interpretable evaluation code at \url{https://github.com/neulab/ExplainaBoard} and output files from more than 300 systems, 40 datasets, and 9 tasks to motivate the "output-driven" research in the future.
Does syntax matter? A strong baseline for Aspect-based Sentiment Analysis with RoBERTa
Apr 11, 2021
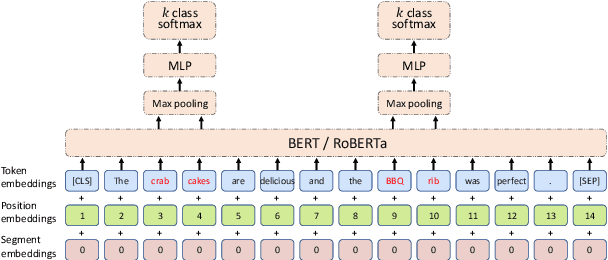
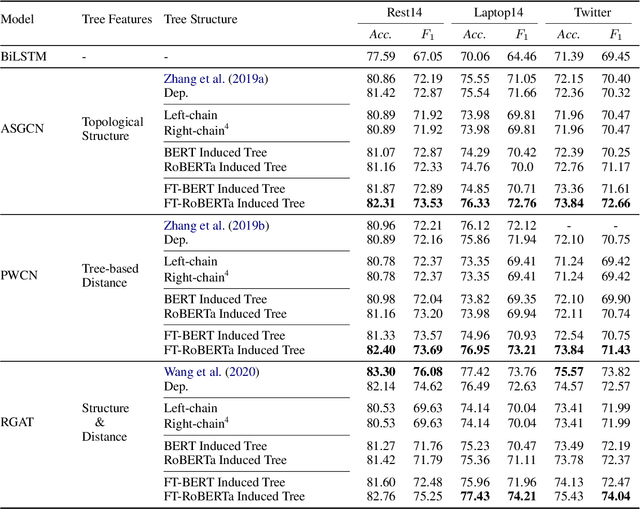

Aspect-based Sentiment Analysis (ABSA), aiming at predicting the polarities for aspects, is a fine-grained task in the field of sentiment analysis. Previous work showed syntactic information, e.g. dependency trees, can effectively improve the ABSA performance. Recently, pre-trained models (PTMs) also have shown their effectiveness on ABSA. Therefore, the question naturally arises whether PTMs contain sufficient syntactic information for ABSA so that we can obtain a good ABSA model only based on PTMs. In this paper, we firstly compare the induced trees from PTMs and the dependency parsing trees on several popular models for the ABSA task, showing that the induced tree from fine-tuned RoBERTa (FT-RoBERTa) outperforms the parser-provided tree. The further analysis experiments reveal that the FT-RoBERTa Induced Tree is more sentiment-word-oriented and could benefit the ABSA task. The experiments also show that the pure RoBERTa-based model can outperform or approximate to the previous SOTA performances on six datasets across four languages since it implicitly incorporates the task-oriented syntactic information.