 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetectiveQA: Evaluating Long-Context Reasoning on Detective Novels
Sep 04, 2024



With the rapid advancement of Large Language Models (LLMs), long-context information understanding and processing have become a hot topic in academia and industry. However, benchmarks for evaluating the ability of LLMs to handle long-context information do not seem to have kept pace with the development of LLMs. Despite the emergence of various long-context evaluation benchmarks, the types of capability assessed are still limited, without new capability dimensions. In this paper, we introduce DetectiveQA, a narrative reasoning benchmark featured with an average context length of over 100K tokens. DetectiveQA focuses on evaluating the long-context reasoning ability of LLMs, which not only requires a full understanding of context but also requires extracting important evidences from the context and reasoning according to extracted evidences to answer the given questions. This is a new dimension of capability evaluation, which is more in line with the current intelligence level of LLMs. We use detective novels as data sources, which naturally have various reasoning elements. Finally, we manually annotated 600 questions in Chinese and then also provided an English edition of the context information and questions. We evaluate many long-context LLMs on DetectiveQA, including commercial and open-sourced models, and the results indicate that existing long-context LLMs still require significant advancements to effectively process true long-context dependency questions.
Unified Active Retrieval for Retrieval Augmented Generation
Jun 18, 2024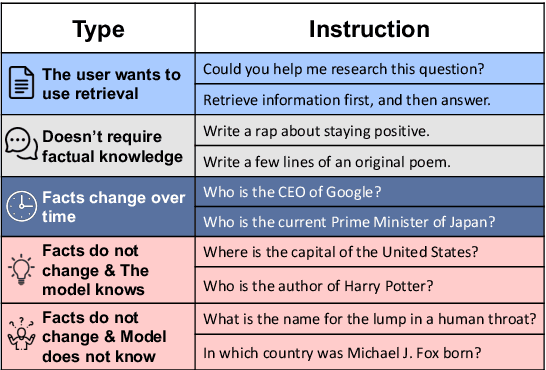

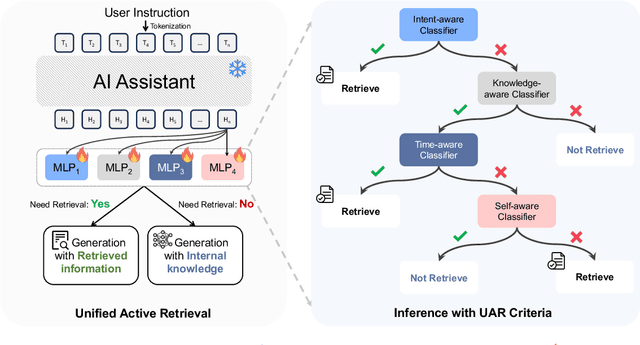
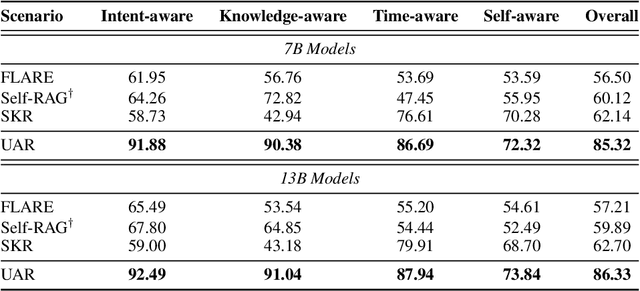
In Retrieval-Augmented Generation (RAG), retrieval is not always helpful and applying it to every instruction is sub-optimal. Therefore, determining whether to retrieve is crucial for RAG, which is usually referred to as Active Retrieval. However, existing active retrieval methods face two challenges: 1. They usually rely on a single criterion, which struggles with handling various types of instructions. 2. They depend on specialized and highly differentiated procedures, and thus combining them makes the RAG system more complicated and leads to higher response latency. To address these challenges, we propose Unified Active Retrieval (UAR). UAR contains four orthogonal criteria and casts them into plug-and-play classification tasks, which achieves multifaceted retrieval timing judgements with negligible extra inference cost. We further introduce the Unified Active Retrieval Criteria (UAR-Criteria), designed to process diverse active retrieval scenarios through a standardized procedure. Experiments on four representative types of user instructions show that UAR significantly outperforms existing work on the retrieval timing judgement and the performance of downstream tasks, which shows the effectiveness of UAR and its helpfulness to downstream tasks.
Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
May 21, 2024

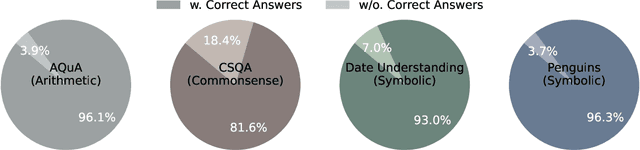
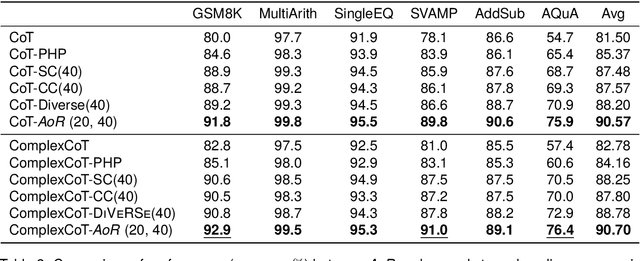
Recent advancements in Chain-of-Thought prompting have facilitated significant breakthroughs for Large Language Models (LLMs) in complex reasoning tasks. Current research enhances the reasoning performance of LLMs by sampling multiple reasoning chains and ensembling based on the answer frequency. However, this approach fails in scenarios where the correct answers are in the minority. We identify this as a primary factor constraining the reasoning capabilities of LLMs, a limitation that cannot be resolved solely based on the predicted answers. To address this shortcoming, we introduce a hierarchical reasoning aggregation framework AoR (Aggregation of Reasoning), which selects answers based on the evaluation of reasoning chains. Additionally, AoR incorporates dynamic sampling, adjusting the number of reasoning chains in accordance with the complexity of the task. Experimental results on a series of complex reasoning tasks show that AoR outperforms prominent ensemble methods. Further analysis reveals that AoR not only adapts various LLMs but also achieves a superior performance ceiling when compared to current methods.
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance
Mar 25, 2024



Pretraining data of large language models composes multiple domains (e.g., web texts, academic papers, codes), whose mixture proportions crucially impact the competence of outcome models. While existing endeavors rely on heuristics or qualitative strategies to tune the proportions, we discover the quantitative predictability of model performance regarding the mixture proportions in function forms, which we refer to as the data mixing laws. Fitting such functions on sample mixtures unveils model performance on unseen mixtures before actual runs, thus guiding the selection of an ideal data mixture. Furthermore, we propose nested use of the scaling laws of training steps, model sizes, and our data mixing law to enable predicting the performance of large models trained on massive data under various mixtures with only small-scale training. Moreover, experimental results verify that our method effectively optimizes the training mixture of a 1B model trained for 100B tokens in RedPajama, reaching a performance comparable to the one trained for 48% more steps on the default mixture. Extending the application of data mixing laws to continual training accurately predicts the critical mixture proportion that avoids catastrophic forgetting and outlooks the potential for dynamic data schedules
In-Memory Learning: A Declarative Learning Framework for Large Language Models
Mar 05, 2024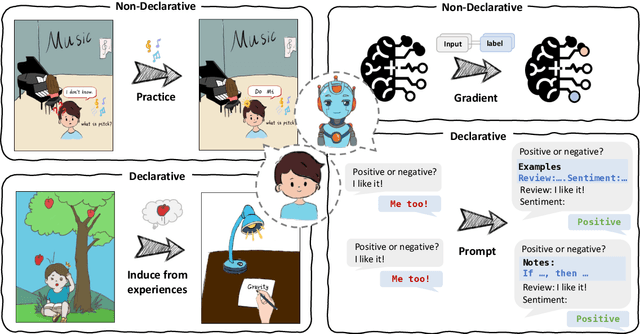



The exploration of whether agents can align with their environment without relying on human-labeled data presents an intriguing research topic. Drawing inspiration from the alignment process observed in intelligent organisms, where declarative memory plays a pivotal role in summarizing past experiences, we propose a novel learning framework. The agents adeptly distill insights from past experiences, refining and updating existing notes to enhance their performance in the environment. This entire process transpires within the memory components and is implemented through natural language, so we character this framework as In-memory Learning. We also delve into the key features of benchmarks designed to evaluate the self-improvement process. Through systematic experiments, we demonstrate the effectiveness of our framework and provide insights into this problem.
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Feb 26, 2024



We introduce AnyGPT, an any-to-any multimodal language model that utilizes discrete representations for the unified processing of various modalities, including speech, text, images, and music. AnyGPT can be trained stably without any alterations to the current large language model (LLM) architecture or training paradigms. Instead, it relies exclusively on data-level preprocessing, facilitating the seamless integration of new modalities into LLMs, akin to the incorporation of new languages. We build a multimodal text-centric dataset for multimodal alignment pre-training. Utilizing generative models, we synthesize the first large-scale any-to-any multimodal instruction dataset. It consists of 108k samples of multi-turn conversations that intricately interweave various modalities, thus equipping the model to handle arbitrary combinations of multimodal inputs and outputs. Experimental results demonstrate that AnyGPT is capable of facilitating any-to-any multimodal conversation while achieving performance comparable to specialized models across all modalities, proving that discrete representations can effectively and conveniently unify multiple modalities within a language model. Demos are shown in https://junzhan2000.github.io/AnyGPT.github.io/
Turn Waste into Worth: Rectifying Top-$k$ Router of MoE
Feb 21, 2024

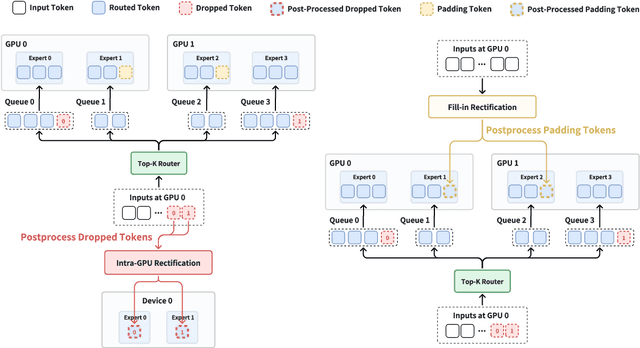

Sparse Mixture of Experts (MoE) models are popular for training large language models due to their computational efficiency. However, the commonly used top-$k$ routing mechanism suffers from redundancy computation and memory costs due to the unbalanced routing. Some experts are overflow, where the exceeding tokens are dropped. While some experts are vacant, which are padded with zeros, negatively impacting model performance. To address the dropped tokens and padding, we propose the Rectify-Router, comprising the Intra-GPU Rectification and the Fill-in Rectification. The Intra-GPU Rectification handles dropped tokens, efficiently routing them to experts within the GPU where they are located to avoid inter-GPU communication. The Fill-in Rectification addresses padding by replacing padding tokens with the tokens that have high routing scores. Our experimental results demonstrate that the Intra-GPU Rectification and the Fill-in Rectification effectively handle dropped tokens and padding, respectively. Furthermore, the combination of them achieves superior performance, surpassing the accuracy of the vanilla top-1 router by 4.7%.
Dictionary Learning Improves Patch-Free Circuit Discovery in Mechanistic Interpretability: A Case Study on Othello-GPT
Feb 19, 2024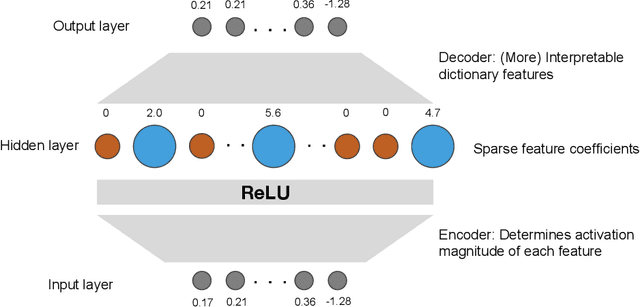

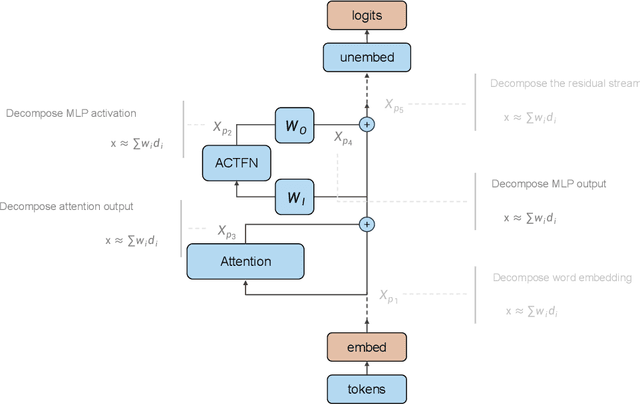
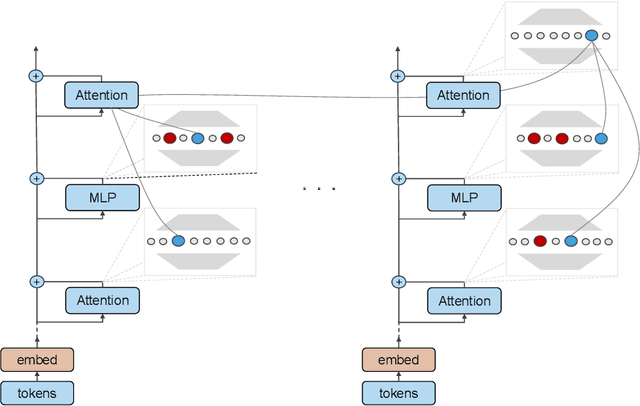
Sparse dictionary learning has been a rapidly growing technique in mechanistic interpretability to attack superposition and extract more human-understandable features from model activations. We ask a further question based on the extracted more monosemantic features: How do we recognize circuits connecting the enormous amount of dictionary features? We propose a circuit discovery framework alternative to activation patching. Our framework suffers less from out-of-distribution and proves to be more efficient in terms of asymptotic complexity. The basic unit in our framework is dictionary features decomposed from all modules writing to the residual stream, including embedding, attention output and MLP output. Starting from any logit, dictionary feature or attention score, we manage to trace down to lower-level dictionary features of all tokens and compute their contribution to these more interpretable and local model behaviors. We dig in a small transformer trained on a synthetic task named Othello and find a number of human-understandable fine-grained circuits inside of it.
LLM can Achieve Self-Regulation via Hyperparameter Aware Generation
Feb 17, 2024In the realm of Large Language Models (LLMs), users commonly employ diverse decoding strategies and adjust hyperparameters to control the generated text. However, a critical question emerges: Are LLMs conscious of the existence of these decoding strategies and capable of regulating themselves? The current decoding generation process often relies on empirical and heuristic manual adjustments to hyperparameters based on types of tasks and demands. However, this process is typically cumbersome, and the decoding hyperparameters may not always be optimal for each sample. To address the aforementioned challenges, we propose a novel text generation paradigm termed Hyperparameter Aware Generation (HAG). By leveraging hyperparameter-aware instruction tuning, the LLM autonomously determines the optimal decoding strategy and configs based on the input samples, enabling self-regulation. Our approach eliminates the need for extensive manual tuning, offering a more autonomous, self-regulate model behavior. Experimental results spanning six datasets across reasoning, creativity, translation, and mathematics tasks demonstrate that hyperparameter-aware instruction tuning empowers the LLMs to self-regulate the decoding strategy and hyperparameter. HAG extends the current paradigm in the text generation process, highlighting the feasibility of endowing the LLMs with self-regulate decoding strategies.
Can AI Assistants Know What They Don't Know?
Jan 28, 2024
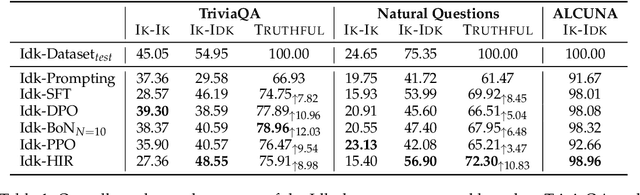

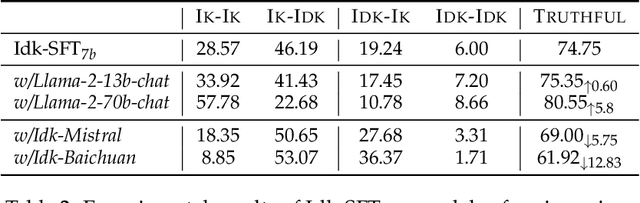
Recently, AI assistants based on large language models (LLMs) show surprising performance in many tasks, such as dialogue, solving math problems, writing code, and using tools. Although LLMs possess intensive world knowledge, they still make factual errors when facing some knowledge intensive tasks, like open-domain question answering. These untruthful responses from the AI assistant may cause significant risks in practical applications. We believe that an AI assistant's refusal to answer questions it does not know is a crucial method for reducing hallucinations and making the assistant truthful. Therefore, in this paper, we ask the question "Can AI assistants know what they don't know and express them through natural language?" To answer this question, we construct a model-specific "I don't know" (Idk) dataset for an assistant, which contains its known and unknown questions, based on existing open-domain question answering datasets. Then we align the assistant with its corresponding Idk dataset and observe whether it can refuse to answer its unknown questions after alignment. Experimental results show that after alignment with Idk datasets, the assistant can refuse to answer most its unknown questions. For questions they attempt to answer, the accuracy is significantly higher than before the alignment.