 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI Assistants Know What They Don't Know?
Paper and Code

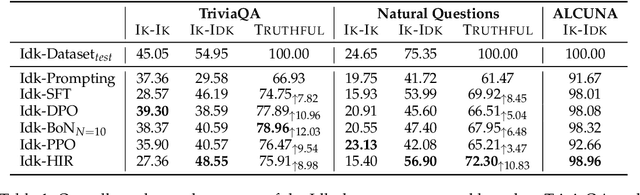

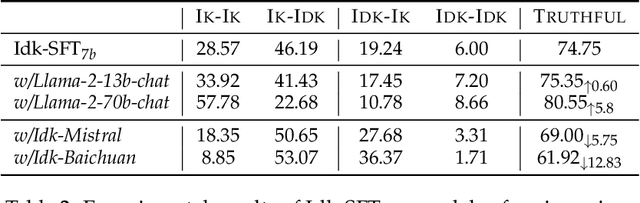
Recently, AI assistants based on large language models (LLMs) show surprising performance in many tasks, such as dialogue, solving math problems, writing code, and using tools. Although LLMs possess intensive world knowledge, they still make factual errors when facing some knowledge intensive tasks, like open-domain question answering. These untruthful responses from the AI assistant may cause significant risks in practical applications. We believe that an AI assistant's refusal to answer questions it does not know is a crucial method for reducing hallucinations and making the assistant truthful. Therefore, in this paper, we ask the question "Can AI assistants know what they don't know and express them through natural language?" To answer this question, we construct a model-specific "I don't know" (Idk) dataset for an assistant, which contains its known and unknown questions, based on existing open-domain question answering datasets. Then we align the assistant with its corresponding Idk dataset and observe whether it can refuse to answer its unknown questions after alignment. Experimental results show that after alignment with Idk datasets, the assistant can refuse to answer most its unknown questions. For questions they attempt to answer, the accuracy is significantly higher than before the alignment.